
Fuzzing or fuzz testing is style of testing that generates random inputs to targeted interfaces in order to automatically find defects, vulnerabilities, or both.
In other words, fuzzing is simply an automated way of testing APIs with generated data.
A fuzzer is a program that is used to fuzz an interface. It typically has three steps that it executes repeatedly:
- Generate a new input. This part of the fuzzer is referred to as the fuzzing engine.
- Use the input to exercise the targeted interface, or code being tested. This is referred to as the fuzz target function.
- Monitor the code being tested for any abnormal conditions. This is referred to as instrumentation.
This document explores fuzzing in general. For detailed guides on how to fuzz Fuchsia software, see Fuzzing in Fuchsia.
History
Although using random data in tests can be traced back as far as the punch card era, the term fuzzing originated with Barton Miller around 1990, who was surprised by how many Unix programs would crash as sent remote commands during a thunderstorm. In subsequent efforts, he and his students found crashing inputs for over a quarter of the commonly used Unix utilities they examined.
Over time, fuzzing matured into several different forms, including:
- Dumb fuzzing: This is the form most widely known, and simply consists of submitting random data and watching for crashes. It has a tendency to get stuck on shallow error paths.
- Generation-based fuzzing: A model is used to describe what the generated data should look like. This approach often can reach much deeper into code, as the model ensures inputs pass simpler validations. However, creating and maintaining the data model often requires a significant investment of time and effort.
- Mutation-based fuzzing: Instead of describing the data with a model, this form starts with actual valid inputs, and adds random mutations to them. This group of "seed" inputs is collectively referred to as a corpus. It can be much simpler to set up, but a significant number of mutations fail simple validations.
Coverage-guided fuzzing
A variant of mutation-based fuzzing known as coverage-guided fuzzing has been shown to yield a particularly high number of bugs for the effort involved. This is the preferred form of fuzzing at Google, and is the primary form supported on Fuchsia through LLVM's libFuzzer.
Code coverage is a measure of what instructions are executed as a result of handling a specific input. In coverage-guided fuzzing, the code under test is instrumented to collect code coverage data in addition to monitoring for abnormal conditions. The fuzzing engine uses this data to determine which inputs increase the overall code coverage and uses those inputs as the basis for generating further inputs.
Examples of coverage-guided fuzzing engines include libFuzzer, syzkaller, and AFL. Each has its own strategies for mutating inputs based on those in its corpus and the feedback it gets from the instrumentation.
Examples of coverage-guided instrumentation include LLVM's sanitizers, such as ASan. These check for specific conditions, such as memory corruption, while also providing callbacks to register which code blocks are executed.
In the diagram below, a fuzzer author would provide the fuzz target function and an optional corpus.
This is combined with the fuzzing engine, a sanitizer for instrumentation, and the library code to
be tested to create a fuzzer. The fuzzer returns inputs that demonstrate software defects along with
other artifacts such as logs and/or stack traces.
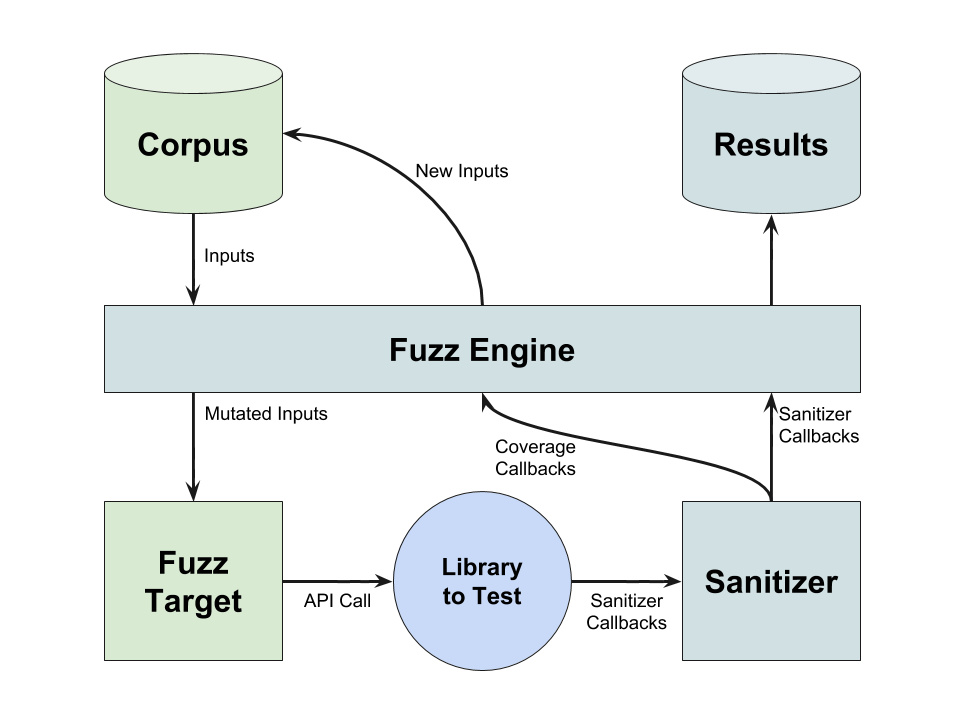
Fuzzing infrastructure
Fuzzing engines and instrumentation can make it easy to create new fuzzers. A fuzzing infrastructure can make running fuzzers just as easy. A fuzzing infrastructure may automate many of the processes around fuzzing, such as:
- Retrieving and deploying the latest version of the code being tested.
- Running fuzzers continuously.
- Synchronizing corpora when fuzzers are run in parallel.
- Reproducing software defects caused by specific inputs.
- Minimizing inputs required to trigger specific software defects.
- Isolating the version in which a software defect is first observed.
- Opening bug reports whenever an input uncovers a new reproducible software defect.
- Closing bug reports when a previously reproducible software defect is no longer observed.
Integrating a project with a fuzzing infrastructure requires considerable effort, but yields many advantages. With a complete fuzzing infrastructure, a fuzzer author needs only to provide a fuzz target function and how to build it in order to receive actionable bug reports in return.
Examples of fuzzing infrastructures include ClusterFuzz, syz-ci, and OSS Fuzz.
Effectiveness of fuzzing
The motivation to fuzz is fairly clear. As a methodology, it has proven surprisingly effective at finding bugs. Tens of thousands of bugs have been found by fuzzing with engines and infrastructures such as:
Fuzzing, and coverage-guided fuzzing in particular, is valuable for testing and finding bugs in code that:
- Receives inputs from untrusted sources and must be secure.
- Has complex algorithms with some equivalence, e.g. compress and decompress, and must be correct.
- Handles high volumes of inputs and/or unreliable dependencies and must be stable.
Unit tests and fuzzing
Another critical aspect is the low overall developer cost for writing and maintaining a fuzzer. If code is well unit-tested, it likely can be fuzzed with very little additional effort. The unit tests describe how to call an API, and can form the basis for a fuzz target function.
If code isn't well unit-tested, developing fuzzers is harder but still extremely beneficial. Writing fuzzers can make code easier to unit test:
- It may prompt refactoring code to expose an API that's easier to fuzz, such as turning a binary into a thin wrapper around a library. These changes also make the code easier to unit test.
- A coverage-guided fuzzer will produce a corpus, or set of "interesting" inputs. The corpus often includes edge cases and other unanticipated inputs that are useful when adding unit tests.
Fuzzing in Fuchsia
Fuchsia includes several guides for developers looking to fuzz Fuchsia software:
- To create a fuzzer, see Write a fuzzer.
- To build and package a fuzzer, see Build a fuzzer.
- To deploy and run a fuzzer, see Run a fuzzer.
- To manage bugs found by fuzzing, see Handling results found through fuzzing.