
如需详细了解 FIDL 的总体用途、目标和要求,请参阅概念概览。
核心概念
消息
FIDL 消息是一组数据。
该消息是一个连续的结构,由单个内嵌主对象和零个或多个非内嵌次对象组成。
对象以遍历顺序存储,并受填充限制。
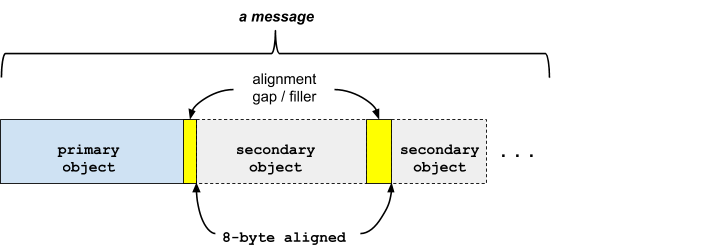
主要对象和次要对象
第一个对象称为主要对象。它是一种固定大小的结构,其类型和大小可从上下文中得知。读取消息时,需要知道要读取的预期类型,即格式不是自描述的。读取发生的上下文应明确这一点。举例来说,在作为 IPC 的一部分读取消息时(请参阅事务性消息标头),上下文完全由标头中包含的数据指定(特别是,序号允许接收者知道预期类型)。对于读取存储中的数据(静态数据),没有等效的描述符,但假设编码器和解码器都知道正在编码或解码的类型(例如,此信息已编译到编码器和解码器使用的相应库中)。
如果需要额外的可变大小或可选数据,主要对象可以引用次要对象(例如字符串、向量、联合等)。
次要对象以遍历顺序内嵌方式存储。
主对象和次对象都按 8 字节对齐,并且存储时没有间隙(对齐所需的间隙除外)。
主对象及其次对象统称为消息。
交易消息
事务性 FIDL 消息(简称事务性消息)用于将数据从一个应用发送到另一个应用。
事务性消息部分介绍了事务性消息的组成方式,即由标头消息(可选)后跟正文消息组成。
遍历顺序
消息的遍历顺序由其包含的所有对象的递归深度优先遍历确定,通过遵循引用链获得。
假设有以下结构:
type Cart = struct {
items vector<Item>;
};
type Item = struct {
product Product;
quantity uint32;
};
type Product = struct {
sku string;
name string;
description string:optional;
price uint32;
};
Cart 消息的深度优先遍历顺序由以下伪代码定义:
visit Cart:
for each Item in Cart.items vector data:
visit Item.product:
visit Product.sku
visit Product.name
visit Product.description
visit Product.price
visit Item.quantity
双重形式:编码与解码
同一消息内容可以采用以下两种形式表示:编码和解码。这些具有相同的大小和总体布局,但在指针(内存地址)或句柄(功能)的表示方面有所不同。
FIDL 的设计使得消息的编码和解码可以在内存中就地进行。
消息编码是规范的 - 对于给定的消息,只有一种编码。
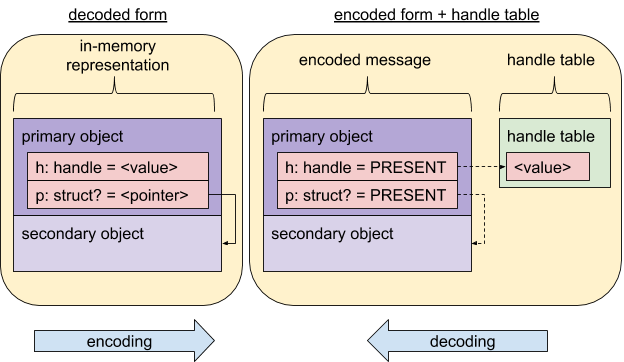
编码后的消息
已准备好要转移到另一进程的编码消息:不包含指针(内存地址)或句柄(功能)。
在编码期间...
- 消息中指向子对象的所有指针都会替换为标志,以指明其所指对象是否存在,
- 消息中的所有句柄都会提取到关联的句柄向量,并替换为指示其所指对象是否存在或不存在的标志。
然后,可以使用 zx_channel_write() 或类似的 IPC 机制将生成的编码消息和句柄向量发送到另一个进程。此类 IPC 还有其他限制。请参阅事务性消息。
解码后的消息
解码后的消息已准备好在进程的地址空间内使用:它可能包含指针(内存地址)或句柄(功能)。
在解码期间:
- 使用编码的“存在”和“不存在”标志重建消息中所有指向子对象的指针。
- 消息中的所有句柄都会使用编码的“存在”和“不存在”标志从关联的句柄向量中恢复。
生成的解码消息可直接从内存中获取。
内嵌对象
对象还可以包含内嵌对象,这些对象聚合在包含对象的正文中,例如嵌入式结构体和结构体的固定大小数组。
示例
在以下示例中,Region 结构包含一个 Rect 结构向量,每个 Rect 结构都包含两个 Point。
每个 Point 都包含一个 x 和一个 y 值。
type Region = struct {
rects vector<Rect>;
};
type Rect = struct {
top_left Point;
bottom_right Point;
};
type Point = struct {
x uint32;
y uint32;
};
按遍历顺序检查对象意味着我们从 Region 结构开始,它是主要对象。
rects 成员是 vector,因此其内容以内嵌方式存储。
这意味着 vector 内容紧跟在 Region 对象之后。
每个 Rect 结构体都包含两个 Point,它们以内嵌方式存储(因为它们的数量是固定的),并且每个 Point 的原始数据类型(x 和 y)也以内嵌方式存储。原因相同,即会员类型数量固定。
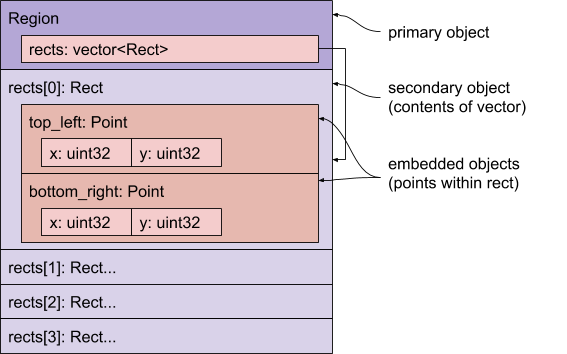
当从属对象的大小固定时,我们使用内联存储;当从属对象的大小可变时(包括 boxed 结构),我们使用外联存储。
类型详情
在本部分中,我们将展示所有 FIDL 对象的编码。
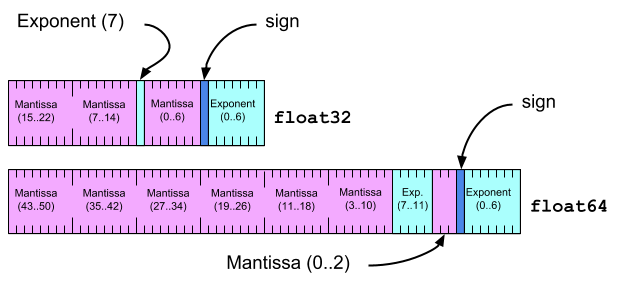
基元
- 以小端序格式存储的值。
- 包含自然对齐。
- 每个 m 字节基元都存储在 m 字节边界上。
- 不可选。
支持以下基本类型:
| 类别 | 类型 |
|---|---|
| 布尔值 | bool |
| 有符号整数 | int8、int16、int32、int64 |
| 无符号整数 | uint8、uint16、uint32、uint64 |
| IEEE 754 floating-point | float32、float64 |
| 字符串 | (不是基元,请参阅字符串) |
数字类型以其大小(以位为单位)作为后缀。
布尔值类型 bool 以单字节形式存储,并且只有 0 或 1 这两个值。
所有浮点值都表示有效的 IEEE 754 位模式。
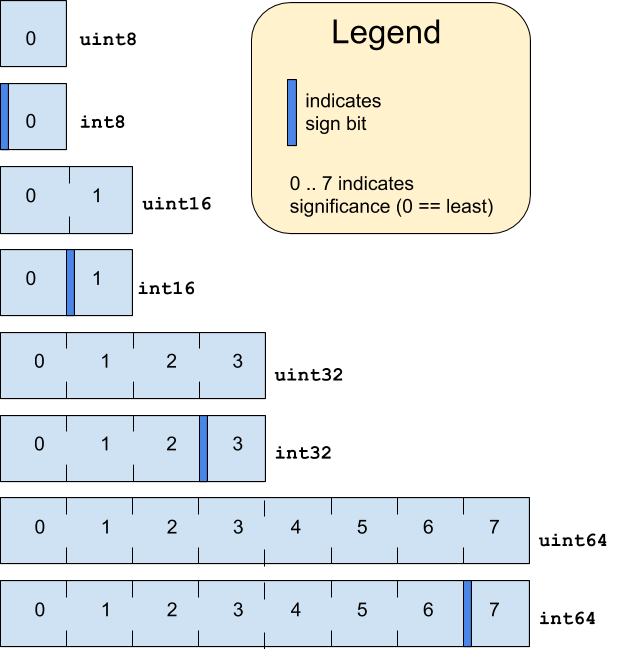
枚举和位
位字段和枚举会存储为它们的基础基元类型(例如 uint32)。
句柄
句柄是一个 32 位整数,但需要特殊处理。在编码以进行传输时,句柄的在线表示形式会被替换为存在和不存在指示,而句柄本身则存储在单独的句柄向量中。解码后,句柄存在指示会替换为零(如果不存在)或有效句柄(如果存在)。
句柄值本身不会从一个应用转移到另一个应用。
从这方面来看,句柄类似于指针;它们引用的是每个应用独有的上下文。 句柄从一个应用的上下文移至另一个应用的上下文。
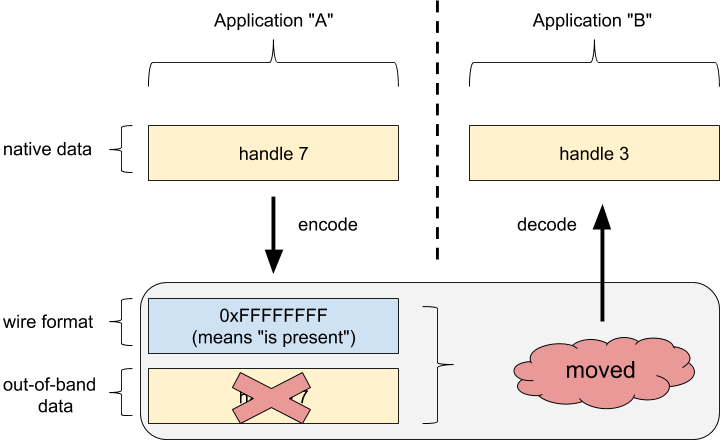
值 0 可用于表示可选句柄不存在1。
如需查看通过 FIDL 转移句柄的详细示例,请参阅句柄的生命周期。
聚合对象
聚合对象充当其他对象的容器。它们可能会以内嵌或外嵌方式存储相应数据,具体取决于其类型。
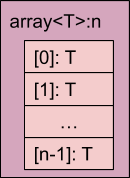
数组
- 由同类元素组成的固定长度序列。
- 包含元素的自然对齐方式。
- 数组的对齐方式与其元素的对齐方式相同。
- 每个后续元素都对齐到元素的对齐边界。
- 数组的步长正好等于元素的大小(包括满足元素对齐限制所需的填充)。
- 始终为必需。
- 对于布尔值数组,没有特殊情况。每个布尔元素都像往常一样占用一个字节。
数组的表示法:
array<T, N>:其中 T 可以是任何 FIDL 类型(包括数组),而 N 是数组中的元素数量。注意:数组的大小不得超过 232-1。 如需了解更多详情,请参阅 RFC-0059。
矢量
- 同构元素的可变长度序列。
- 可以是可选的;缺失向量和空向量是不同的。
- 可以指定最大大小,例如
vector<T>:40表示最多 40 个元素的向量。 - 存储为由以下内容组成的 16 字节记录:
size:64 位无符号元素数量 注意:向量的大小不得超过 232-1。 如需了解更多详情,请参阅 RFC-0059。data:64 位存在指示或指向内嵌元素数据的指针
- 在编码以进行传输时,
data表示存在内容:0:缺少向量UINTPTR_MAX:存在向量,数据是下一个带外对象
- 解码以供使用时,
data是指向内容的指针:0:缺少向量<valid pointer>:存在向量,数据位于指示的内存地址
- 对于布尔值向量,没有特殊情况。每个布尔元素都像往常一样占用一个字节。
向量的表示法如下:
vector<T>:必需的元素类型为 T 的矢量(如果缺少data,则会发生验证错误)vector<T>:optional:元素类型为 T 的可选向量vector<T>:N、vector<T>:<N, optional>:长度不超过 N 个元素的向量
T 可以是任何 FIDL 类型。

字符串
字符串实现为 uint8 字节的矢量,但必须满足字节是有效的 UTF-8 的约束条件。
结构
结构包含一系列类型化字段。
在内部,该结构会进行填充,以便所有成员都与所有成员的最大对齐要求保持一致。 在外部,结构按 8 字节边界对齐,因此可能包含最终填充以满足该要求。
以下是一些示例。
具有 int32 和 int8 字段的结构体的对齐方式为 4 字节(由于 int32),大小为 8 字节(int8 之后有 3 字节的填充):

具有 bool 和 string 字段的结构体的对齐方式为 8 字节(由于 string),大小为 24 字节(bool 之后有 7 字节的填充):
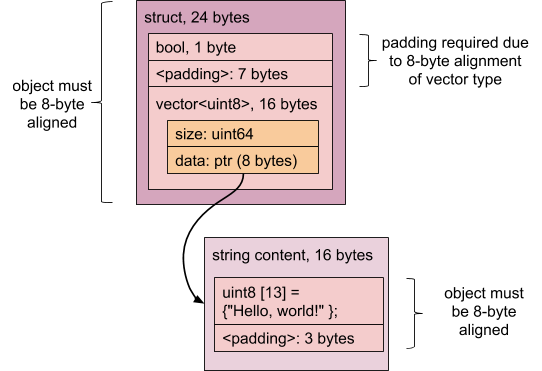
包含一个 bool 和两个 uint8 字段的结构体的对齐方式为 1 字节,大小为 3 字节(无填充!):
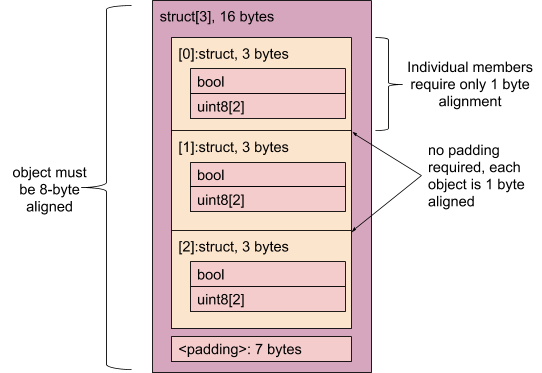
结构可以是:
- 空 - 没有字段。此类结构的大小为 1 字节,对齐方式为 1 字节,并且完全等同于包含值为零的
uint8的结构。 - 必需 - 结构的内容以内嵌方式存储。
- 可选 - 结构的内容存储在行外,并通过间接引用进行访问。
结构的存储取决于它在引用点是否已装箱。
- 非盒子结构:
- 内容以内嵌方式存储在其包含类型中,从而可以构建非常高效的聚合结构。
- 内联时,结构布局不会发生变化;其字段不会重新打包以填充容器中的空白。
- 盒装结构:
- 内容以带外方式存储,并通过间接引用进行访问。
- 在编码以进行转移时,存储的引用表示结构的存在:
0:缺少参考UINTPTR_MAX:存在引用,结构内容是下一个带外对象- 解码以供使用时,存储的引用是指针:
0:缺少参考<valid pointer>:存在引用,结构内容位于指示的内存地址
结构体由其声明的名称(例如 Circle)表示,并且可以装箱:
Point:必需Pointbox<Color>:加框,始终为可选Color
以下示例说明了:
- 结构布局(顺序、打包和对齐)
- 必需的结构 (
Point) - 盒装 (
Color)
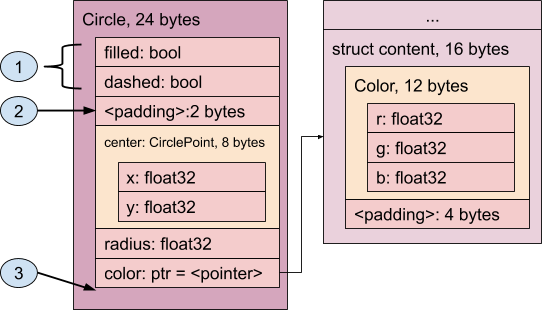
type Circle = struct {
filled bool;
center CirclePoint; // CirclePoint will be stored in-line
radius float32;
color box<Color>; // Color will be stored out-of-line
dashed bool;
};
type CirclePoint = struct {
x float32;
y float32;
};
type Color = struct {
r float32;
g float32;
b float32;
};
Color 内容填充到 8 字节的次要对象对齐边界。
详细了解布局:

- 第一个成员
filled bool占用一个字节,但由于下一个成员具有 4 字节对齐要求,因此需要三个字节的填充。 center CirclePoint成员是必需结构的示例。因此,其内容(x和y32 位浮点数)是内嵌的,整个内容占用 8 个字节。radius是一个 32 位项,需要 4 字节对齐。由于下一个可用位置已位于 4 字节对齐边界上,因此无需填充。color box<Color>成员是装箱结构的示例。由于color数据可能存在,也可能不存在,因此处理此问题的最有效方法是将指向该结构的指针作为内嵌数据保留。这样一来,如果color成员确实存在,指针会指向其数据(或者,如果是编码格式,则表示“存在”),而数据本身会存储在行外(在Circle结构的数据之后)。如果不存在color成员,则指针为NULL(或者,在编码格式中,通过存储零来指示“不存在”)。dashed bool不需要任何特殊对齐方式,因此接下来是它。 不过,现在我们已到达对象的末尾,所有对象都必须按 8 字节对齐。这意味着我们需要再添加 7 字节的填充。color的带外数据遵循Circle数据结构,包含三个 32 位float值(r、g和b);它们需要 4 字节对齐,因此可以彼此相邻,无需填充。不过,与Circle对象一样,我们需要对象本身是 8 字节对齐的,因此需要 4 字节的填充。
总而言之,此结构占用 48 字节。
不过,如果将 dashed bool 移到 filled bool 之后,您就可以节省大量空间 2:
- 两个
bool值“打包”在一起,放在原本会浪费的空间中。 - 填充减少到两个字节 - 这将是添加 16 位值或更多
bool或 8 位整数的好地方。 - 请注意,
Color框后无需留边衬区;所有内容都完美对齐到 8 字节边界。
该结构现在占用 40 个字节。
红包
信封是数据的容器,供表和并集在内部使用。它不会公开给 FIDL 语言。它采用固定的 8 字节格式。
全零的信封标头称为“零信封”。用于表示不存在的信封。否则,信封存在,并且其标志的第 0 位表示数据是内嵌存储还是非内嵌存储:
- 如果设置了第 0 位,则使用内嵌表示法。
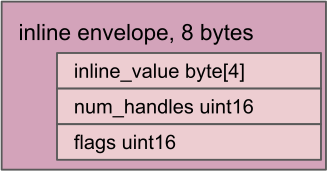
- 如果未设置位 0,则使用内嵌表示法。
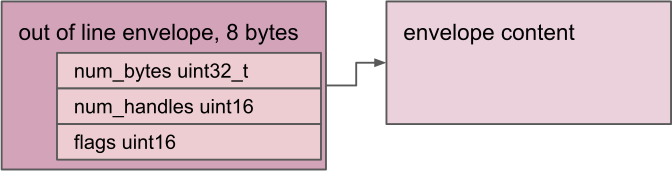
只有当载荷的大小小于或等于 4 字节时,才能设置位 0。只有在信封为零信封或载荷大小大于 4 字节时,才可以取消设置位 0。
有了 num_bytes 和 num_handles,我们就可以跳过未知的信封内容。
num_bytes 将始终是 8 的倍数,因为非内联对象是 8 字节对齐的。
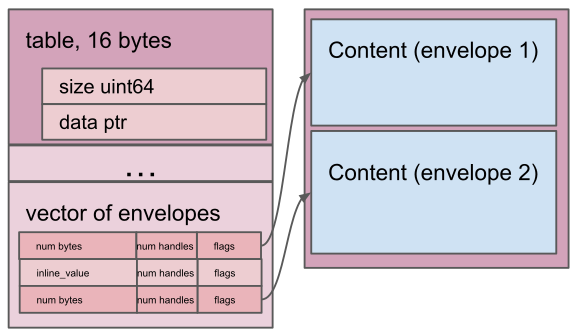
表格
- 包含元素数量和指针的记录类型。
- 指针指向一个信封数组,每个信封包含一个元素。
- 每个元素都与一个序数相关联。
- 序号是连续的,出现缺口会产生空信封费用,因此不建议这样做。
表由其声明的名称(例如 Value)表示,并且永远不是可选的:
Value:必需Value
以下示例展示了如何根据字段布局表格。
type Value = table {
1: command int16;
2: data Circle;
3: offset float64;
};
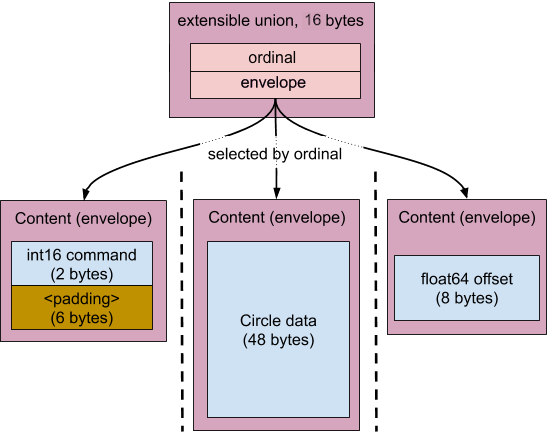
联合体
- 包含序号和信封的记录类型。
- 序号表示成员选择,并以 uint64 表示。
- 每个元素都与用户指定的序数相关联。
- 序数是按顺序排列的。与表不同,序号中的间隙不会产生有线格式空间费用。
- 缺少的可选联合使用
0序数和零信封表示。 - 不允许使用空联合。
联合由其声明的名称(例如 Value)和可选性表示:
Value:必需ValueValue:optional:可选Value
以下示例展示了如何根据联合的字段来布局联合。
type UnionValue = strict union {
1: command int16;
2: data Circle;
3: offset float64;
};
事务性消息
在事务性消息中,始终包含一个标头,后面是可选的正文。
标头和正文都是 FIDL 消息(如上所述),即数据的集合。
标头的格式如下:

zx_txid_t txid,交易 ID(32 位)- 高位已设置的
txid保留供 zx_channel_call() 使用 - 高位未设置的
txid保留供用户空间使用 txid的值0预留给不需要对方回复的消息。 注意:如需详细了解txid分配,请参阅 zx_channel_call()。
- 高位已设置的
uint8[3] flags,不得通过绑定进行检查。这些标志可用于实现线格式的软过渡。如需了解当前标志定义,请参阅标头标志。uint8 magic number,用于确定两种线格式是否兼容。uint64 ordinal- 零序数无效。
- 设置了最高有效位的序号预留用于控制消息和未来扩展。
- 未设置最高有效位的序号表示方法调用和响应。
事务性消息有三种:
- 方法请求,
- 方法响应,以及
- 活动请求。
在接下来的几个示例中,我们将使用以下界面:
type DivisionError = strict enum : uint32 {
DIVIDE_BY_ZERO = 1;
};
protocol Calculator {
Add(struct {
a int32;
b int32;
}) -> (struct {
sum int32;
});
Divide(struct {
dividend int32;
divisor int32;
}) -> (struct {
quotient int32;
remainder int32;
}) error DivisionError;
Clear();
-> OnError(struct {
status_code uint32;
});
};
Add() 和 Divide() 方法说明了方法请求(从客户端发送到服务器)和方法响应(从服务器发送回客户端)。
Clear() 方法是不包含正文的方法请求的一个示例。
说它具有“空”正文是不正确的:这会暗示 header 后面有 body。对于 Clear(),没有正文,只有标头。
方法请求消息
接口的客户端会向服务器发送方法请求消息,以调用相应方法。
方法响应消息
服务器向客户端发送方法响应消息,以指示方法调用已完成并提供(可能为空)结果。
只有在协议声明中定义为提供(可能为空)结果的双向方法请求才会引发方法响应。单向方法请求不得产生方法响应。
方法响应消息提供与之前的方法请求相关联的结果。消息正文包含方法结果,就好像这些结果打包在 struct 中一样。
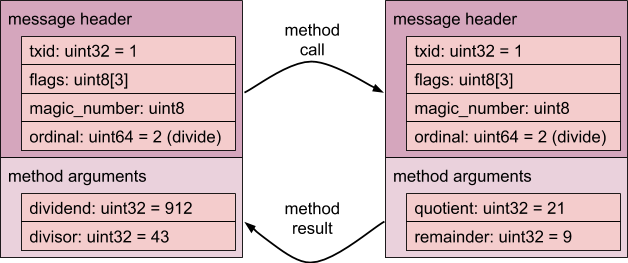
从上图可以看出,912 除以 43 的结果是 21,余数是 9。
请注意 1 的 txid 值,该值用于标识交易。
2 的 ordinal 值表示方法,在本例中为 Divide() 方法。
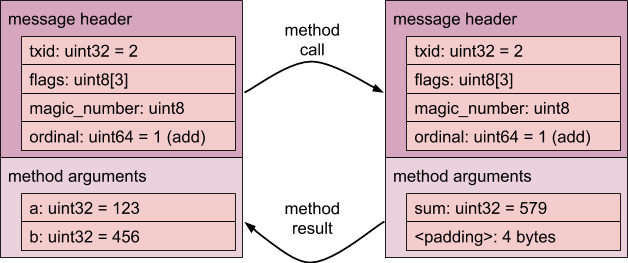
在下图中,我们可以看到 123 + 456 为 579。
此时,txid 的值为 2,这只是分配给交易的下一个交易编号。
ordinal 为 1,表示 Add(),请注意,结果需要 4 个字节的填充,才能使 body 对象的大小为 8 个字节的倍数。
最后,Clear() 方法在两个重要方面不同于 Add() 和 Divide():* 它没有正文(即,它仅由标头组成),并且* 它不会向接口请求响应(txid 为零)。

活动请求
一个事件示例是 Calculator 中的 OnError() 事件。
服务器向客户端发送未经请求的事件请求,以指示发生了异步事件(如协议声明中所指定)。
在 Calculator 示例中,我们可以想象,尝试除以零会导致在连接关闭之前发送 OnError() 事件,并附带“除以零”状态代码。这样一来,客户端就可以区分连接是因错误而关闭,还是因其他原因(例如计算器进程异常终止)而关闭。

请注意,txid 为零(表示这不是交易的一部分),而 ordinal 为 4(表示 OnError() 方法)。
正文包含事件实参,就像它们打包在 struct 中一样,与方法结果消息相同。 请注意,系统会填充正文,以保持 8 字节对齐。
墓志铭(控制消息序号 0xFFFFFFFFFFFFFFFF)
墓志铭是序号为 0xFFFFFFFFFFFFFFFF 的事件(交易 ID 为零)。服务器可能会在关闭连接之前发送一条墓志铭作为最后一条消息,以指示连接关闭的原因。在发送墓志铭后,不得再通过该连接发送任何消息。墓志铭不会从客户端发送到服务器。
墓志铭的线表示形式等效于以下 FIDL:
fidl
struct {
error zx.Status;
};
未来可能会在 FIDL 中正式定义墓志铭。
详细信息
大小和对齐
sizeof(T) 表示类型为 T 的对象的大小(以字节为单位)。
alignof(T) 表示用于存储类型为 T 的对象的对齐系数(以字节为单位)。
FIDL 基元类型存储在消息中偏移量为字节大小倍数的位置。因此,对于基元 T,alignof(T) ==
sizeof(T)。这称为自然对齐。它具有一个不错的特性,即满足现代 CPU 架构的典型对齐要求。
FIDL 复杂类型(例如结构体和数组)存储在消息中偏移量为所有字段的最大对齐系数的倍数的位置。因此,对于复杂类型 T,alignof(T) ==
max(alignof(F:T)) 是针对 T 中的所有字段 F 计算的。它具有一个很好的属性,即满足典型的 C 结构打包要求(可以使用生成的代码中的打包属性强制执行)。复杂类型的大小是存储其成员(适当对齐)所需的总字节数,加上填充字节数(直到达到类型的对齐系数)。
无论 FIDL 主对象和辅助对象的内容如何,它们在消息中都以 8 字节偏移量对齐。FIDL 消息的主要对象从偏移量 0 开始。作为消息中指针唯一可能指代的次要对象始终从 8 的倍数的偏移量开始。(因此,消息中的所有指针都指向 8 的倍数的偏移量。)
FIDL 内嵌对象(嵌入在主要对象或次要对象中的复杂类型)会根据其类型进行对齐。它们不会强制进行 8 字节对齐。
类型
注意:
- N 表示元素的数量,无论是明确声明(如
array<T, N>,一个包含 N 个 T 类型元素的数组),还是隐式声明(一个包含 7 个元素的table将具有N=7)。 - 离线大小始终填充为 8 字节。我们会在下方显示内容大小(不包括内边距)。
- 以下
vector条目中的sizeof(T)为
in_line_sizeof(T) + out_of_line_sizeof(T)。 - 下面
table条目中的 M 是当前字段的最大序数。 - 在下面的
struct条目中,边衬区是指使struct与最宽元素对齐所需的边衬区。例如,struct{uint32;uint8}有 3 个字节的填充,这与对齐到 8 字节边界的填充不同。
| 类型 | 大小(内嵌) | 大小(内嵌) | 对齐方式 |
|---|---|---|---|
bool |
1 | 0 | 1 |
int8、uint8 |
1 | 0 | 1 |
int16、uint16 |
2 | 0 | 2 |
int32、uint32、float32 |
4 | 0 | 4 |
int64、uint64、float64 |
8 | 0 | 8 |
enum、bits |
(基础类型) | 0 | (基础类型) |
handle 等 |
4 | 0 | 4 |
array<T, N> |
sizeof(T) * N | 0 | alignof(T) |
vector 等 |
16 | N * sizeof(T) | 8 |
struct |
sum(sizeof(fields)) + padding | 0 | 8 |
box<struct> |
8 | sum(sizeof(fields)) + padding | 8 |
envelope |
8 | sizeof(field) | 8 |
table |
16 | M * sizeof(envelope) + sum(aligned_to_8(sizeof(present fields)) | 8 |
union、union:optional |
16 | sizeof(所选变体) | 8 |
上述 handle 条目是指所有类型的句柄,具体包括 handle、handle:optional、handle:H、handle:<H, optional>、client_end:Protocol、client_end:<Protocol, optional>、server_end:Protocol 和 server_end:<Protocol, optional>。
同样,上面的 vector 条目是指所有类型的矢量,具体包括 vector<T>、vector<T>:optional、vector<T>:N、vector<T>:<N, optional>、string、string:optional、string:N 和 string:<N, optional>。
内边距
消息的创建者必须用零填充所有对齐填充间隙。
消息的消费者必须验证填充是否包含零(如果不是,则生成错误)。
最大递归深度
FIDL 向量、可选结构、表和联合可用于构建递归消息。如果不加检查,处理过深的消息可能会导致资源耗尽或出现未被检测到的无限循环。
为确保安全,所有 FIDL 消息的最大递归深度限制为 32 级间接寻址。FIDL 编码器、解码器或验证器必须通过在消息验证期间跟踪当前递归深度来强制执行此限制。
递归深度的正式定义:
- FIDL 消息的内嵌对象定义为位于递归深度 0。
- 每次通过指针或信封遍历间接引用时,递归深度都会增加 1。
如果递归深度在任何时候超过 32,则必须终止操作并引发错误。
例如,请考虑以下情况:
type InlineObject = struct {
content_a string;
vector vector<OutOfLineStructAtLevel1>;
table TableInlineAtLevel0;
};
type OutOfLineStructAtLevel1 = struct {
content_b string;
};
type TableInlineAtLevel0 = table {
1: content_c string;
};
对 InlineObject 的实例进行编码时,我们有相应的递归深度:
content_a的字节位于递归深度 1 处,即content_a字符串头内嵌在InlineObject结构体中,而字节位于可通过指针间接访问的非内联对象中。content_b的字节位于递归深度 2,即vector标头内嵌在InlineObject结构体中,因此OutOfLineStructAtLevel1结构体位于递归深度 1,content_b字符串标头内嵌在OutOfLineStructAtLevel1中,而字节位于可通过深度 1 的指针间接寻址访问的非内联对象中,因此位于深度 2。content_c的字节位于递归深度 3 处,即table标头内嵌在InlineObject结构体中,表信封位于深度 1 处,指向深度 2 处的content_c字符串标头,而字节位于可通过指针间接寻址访问的非内联对象中,因此位于深度 3 处。
验证
消息验证的目的是尽早发现线格式错误,以免它们有机会引发安全性或稳定性问题。
在解码从对等方收到的消息时,必须进行消息验证,以防止错误数据传播到服务入口点之外。
在对消息进行编码以发送给对等方时,建议(但并非强制)进行消息验证,以帮助定位违反完整性限制的情况。
为了最大限度地减少运行时开销,验证通常应作为单次传递消息编码或解码过程的一部分来执行,这样只需要一次遍历。由于消息是以深度优先遍历顺序编码的,因此遍历具有良好的内存局部性,应该相当高效。
对于简单消息,验证可能非常简单,仅涉及一些大小检查。虽然我们鼓励程序员依赖其 FIDL 绑定库来代表他们验证消息,但如果需要,也可以手动进行验证。
符合规范的 FIDL 绑定必须检查以下所有完整性限制:
- 消息的总大小(包括所有带外子对象)与包含该消息的缓冲区的总大小完全相同。所有子对象都会被纳入考虑范围。
- 消息引用的句柄总数与句柄表的总大小完全相等。所有句柄都已纳入考虑范围。
- 未超出复杂对象的最大递归深度。
- 所有枚举值都位于其定义的范围内。
- 所有并集标记值都位于其定义的范围内。
- 仅编码:
- 遍历期间遇到的所有指向子对象的指针都精确地指向预期出现子对象的下一个缓冲区位置。因此,指针永远不会指向缓冲区之外的位置。
- 仅解码:
- 被引用子对象的所有存在标志和不存在标志仅包含值 0 或 UINTPTR_MAX。
- 被引用句柄的所有存在和不存在标志仅包含值 0 或 UINT32_MAX。
标头标志
Flags[0]
| 位 | 当前使用率 | 过往使用情况 |
|---|---|---|
| 7 (MSB) | 未使用 | |
| 6 | 未使用 | |
| 5 | 未使用 | |
| 4 | 未使用 | |
| 3 | 未使用 | |
| 2 | 未使用 | |
| 1 | 指示是否使用 v2 有线格式 (RFC-0114) | |
| 0 | 未使用 | 指示是否应将静态联合编码为 xunion (RFC-0061) |
Flags[1]
| 位 | 当前使用率 | 过往使用情况 |
|---|---|---|
| 7 (MSB) | 未使用 | |
| 6 | 未使用 | |
| 5 | 未使用 | |
| 4 | 未使用 | |
| 3 | 未使用 | |
| 2 | 未使用 | |
| 1 | 未使用 | |
| 0 | 未使用 |
Flags[2]
| 位 | 当前使用率 | 过往使用情况 |
|---|---|---|
| 7 (MSB) | 未使用 | |
| 6 | 未使用 | |
| 5 | 未使用 | |
| 4 | 未使用 | |
| 3 | 未使用 | |
| 2 | 未使用 | |
| 1 | 未使用 | |
| 0 | 未使用 |
-
将零句柄定义为“没有句柄”意味着将线格式结构默认初始化为全零是安全的。零也是
ZX_HANDLE_INVALID常量的值。↩ -
如需深入了解此主题,请阅读结构体打包的失落艺术。↩