
This document is a high level overview of the Fuchsia Interface Definition Language (FIDL), which is the language used to describe interprocess communication (IPC) protocols used by programs running on Fuchsia. This overview introduces the concepts behind FIDL — developers familiar with these concepts already can start writing code by following the tutorials, or dive deeper by reading the language or bindings references.
What is FIDL?
While "FIDL" stands for "Fuchsia Interface Definition Language," the word itself can be used to refer to a number of different concepts:
- FIDL wire format: the FIDL wire format specifies how FIDL messages are represented in memory for transmission over IPC
- FIDL language: the FIDL language is the syntax by which
protocols are described in
.fidlfiles - FIDL compiler: the FIDL compiler generates code for programs to use and implement protocols
- FIDL bindings: the FIDL bindings are language-specific runtime support libraries and code generators that provide APIs for manipulating FIDL data structures and protocols.
The main job of FIDL is to allow diverse clients and services to interoperate. Client diversity is aided by decoupling the implementation of the IPC mechanism from its definition, and is simplified by automatic code generation.
The FIDL language provides a familiar (though simplified) C-like declaration syntax that allows the service provider to exactly define their protocols. Basic data types, like integers, floats, and strings, can be organized into more complex aggregate structures and unions. Fixed arrays and dynamically sized vectors can be constructed from both the basic types and the aggregate types, and these can all be combined into even more complex data structures.
Due to the number of client implementation target languages (C, C++, Rust, Dart, and so on), we don't want to burden the developer of the service with providing a protocol implementation for each and every one.
This is where the FIDL toolchain comes in. The developer of the service creates
just one .fidl definition file, which defines the protocol. Using this file,
the FIDL compiler then generates client and server code in any of the supported
target languages.
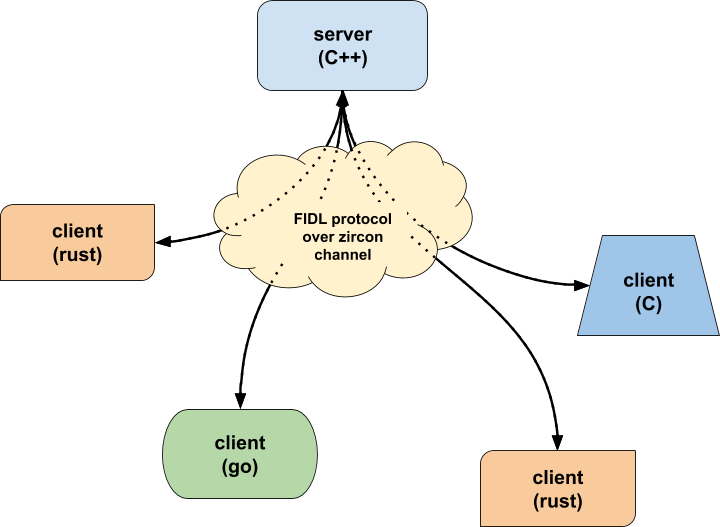
In many cases, there will only be one implementation of the server (for example, the particular service might be implemented in C++), whereas there could be any number of implementations of the client, in a multitude of languages.
Note that the Fuchsia operating system has no innate knowledge of FIDL. The FIDL bindings use a standard channel communication mechanism in Fuchsia. The FIDL bindings and libraries enforce a set of semantic behavior and persistence formats on how that channel is used.
FIDL architecture
From a developer's point of view, the following are the main components:
- FIDL definition file — this is a text file (ending in
.fidlby convention) that defines the values, and protocols (methods with their parameters), - client code — generated by the FIDL compiler (
fidlc) toolchain for each specific target language, and - server code — also generated by the FIDL compiler toolchain.
As a very simple example of a FIDL definition file, consider an "echo" service — whatever the client sends to the server, the server just echoes back to the client.
Line numbers have been added for clarity and are not part of the
.fidlfile.
1 library fidl.examples.echo;
2
3 @discoverable
4 protocol Echo {
5 EchoString(struct {
6 value string:optional;
7 }) -> (struct {
8 response string:optional;
9 });
10 };
Let's go through it line by line.
Line 1: The library keyword is used to define a namespace for this
protocol. FIDL protocols in different libraries might have the same name, so the
namespace is used to distinguish amongst them.
Line 3: The @discoverable attribute indicates that the
protocol that follows should be made available for clients to connect to.
Line 4: The protocol keyword introduces the name of the protocol, here
it's called Echo.
Lines 5-9: The method, its parameters, and return values. There are two unusual aspects of this line:
- Note the declaration
string:optional(for bothvalueandresponse). Thestringpart indicates that the parameters are strings (sequences of characters), while theoptionalconstraint indicates that the parameter is optional. - The parameters are wrapped in a
struct, which is the top level type containing the method parameters. - The
->part indicates the return, which appears after the method declaration, not before. Unlike C++ or Java, a method can return multiple values.
The above FIDL file, then, has declared one protocol, called Echo, with one
method, called EchoString, that takes a nullable string and returns a nullable
string.
The simple example above used just one data type, the string as both the input
to the method as well as the output.
The possible FIDL data types are very flexible:
type MyRequest = struct {
serial uint32;
key string;
options vector<uint32>;
};
The above declares a structure called MyRequest with three members: an
unsigned 32-bit integer called serial, a string called key, and a vector of
unsigned 32-bit integers called options
Messaging Models
In order to understand FIDL's messaging, we need to break things up into two layers, and clarify some definitions.
At the bottom (the operating system layer), there's an asynchronous communications scheme geared towards independent progress of a sender and a receiver:
- sender — the party that originates a message,
- receiver — the party that receives a message,
Sending a message is a non-blocking operation: the sender sends the message, and is then free to continue processing, regardless of what the receiver is doing.
A receiver can, if it wants to, block in order to wait for a message.
The top layer implements FIDL messages, and uses the bottom (asynchronous) layer. It deals with clients and servers:
- client — the party that is making a request (of a server),
- server — the party that is processing a request (on behalf of a client).
The terms "sender" and "receiver" make sense when we're discussing the messages themselves — the underlying communications scheme isn't concerned about the roles that we've assigned to the parties, just that one is sending and one is receiving.
The terms "client" and "server" make sense when we're discussing the roles that the parties play. In particular, a client can be a sender at one time, and a receiver at a different time; same for the server.
Practically speaking, in the context of a client / server interaction, that means that there are several models:
- blocking call — client sends to server, waits for reply
- fire and forget — client sends to server, doesn't expect reply
- callback or async call — client sends to server, but doesn't block; a reply is delivered asynchronously some time later
- event — server sends to client, without the client having asked for data
The first is synchronous, the rest are asynchronous. We'll discuss these in order.
Client sends to server, waits for a reply
This model is the traditional "blocking call" or "function call" available in most programming languages, except that the invocation is done over a channel, and thus can fail due to transport level errors.
From the point of view of the client, it consists of a call that blocks, while the server performs some processing.
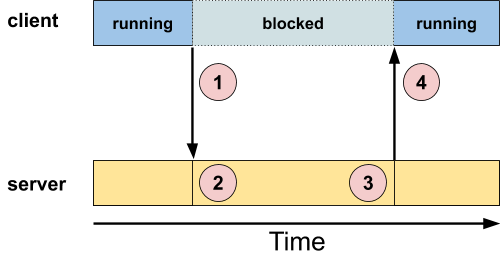
Here's a step-by-step description:
- A client makes a call (optionally containing data) and blocks.
- The server receives the client's call (and optional data), and performs some amount of processing.
- At the server's discretion, it replies to the client (with optional data).
- The server's reply causes the client to unblock.
To implement this synchronous messaging model over an asynchronous messaging scheme is simple. Recall that both the client-to-server and server-to-client message transfers are, at the bottom layer in the protocol, asynchronous. The synchronization happens at the client end, by having the client block until the server's message arrives.
Basically, in this model, the client and server have come to an agreement:
- data flow is initiated by the client,
- the client shall have at most only one message outstanding,
- the server shall send a message to the client only in response to a client's message
- the client shall wait for the server's response before continuing.
This blocking model is commonly used where the client needs to get the reply to its current request before it can continue.
For example, the client may request data from the server, and not be able to do any other useful processing until that data arrives.
Or, the client may need to perform steps in a specific order, and must therefore ensure that each step completes before initiating the next one. If an error occurs, the client may need to perform corrective actions that depend on how far the operation has proceeded — another reason to be synchronized to the completion of each step.
Client sends to server, no reply
This model is also known as "fire and forget." In it, the client sends the message to the server. and then carries on with its operation. In contrast to the blocking model, the client does not block, nor does it expect a response.
This model is used in cases where the client doesn't need to (or cannot) synchronize to the processing of its request.
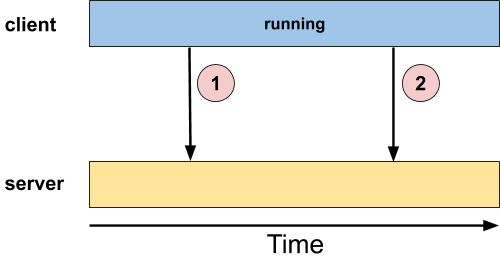
The classic example is a logging system. The client sends logging information to the logging server (circles "1" and "2" in the diagram above), but has no reason to block. A lot of things can go wrong at the server end:
- the server is busy and can't handle the write request at this moment,
- the media is full and the server can't write the data,
- the server has encountered a fault,
- and so on.
However, the client isn't in a position to do anything about those problems, so blocking would just create more problems.
Client sends to server, but doesn't block
This model, and the next one ("server sends to client, without client asking for data") are similar.
In the present model, the client sends a message to a server, but doesn't block. However, the client expects some kind of response from the server, but the key here is that it's not synchronous with the request.
This allows great flexibility in the client / server interaction.
While the synchronous model forces the client to wait until the server replies, the present model frees the client to do something else while the server is processing the request:
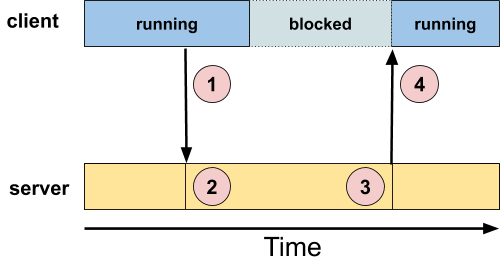
The subtle difference in this diagram vs. the similar one above is that after circle "1" the client is still running. The client chooses when to give up CPU; it's not synchronous with the message.
There are actually two sub-cases here — one in which the client gets just one response, and another in which the client can get multiple responses. (The one where the client gets zero responses is the "fire and forget" model, which we discussed earlier.)
Single request, single response
The single response case is the closest to the synchronous model: the client sends a message, and eventually, the server replies. You'd use this model instead of multi-threading, for example, when you know that the client could be doing useful work while waiting for the server's reply.
Single request, multiple response
The multiple response case can be used in a "subscription" model. The client's message "primes" the server, for example, requesting notification whenever something happens.
The client then goes about its business.
Some time later, the server notices that the condition that the client is interested in has happened, and thus sends the client a message. From a client / server point of view, this message is a "reply", with the client receiving it asynchronously to its request.
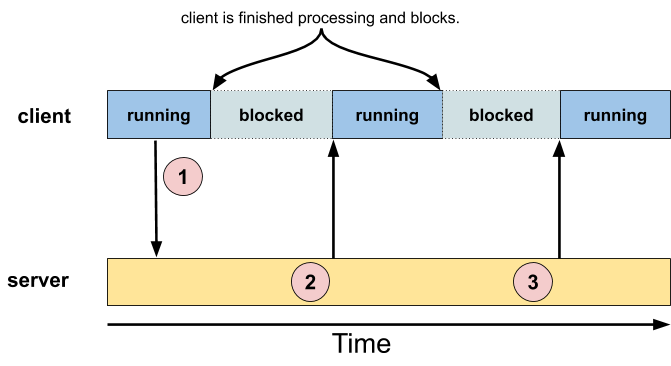
There's no reason why the server couldn't send another message when another event of interest occurs; this is the "multiple response" version of the model. Note that the second (and subsequent) responses are sent without the client sending any additional messages.
Note that the client doesn't need to wait for the server to send it a message. In the diagram above, we showed the client in the blocked state before circle "3" — the client could just as well have been running.
Server sends to client, without client asking for data
This model is also known as the "event" model.
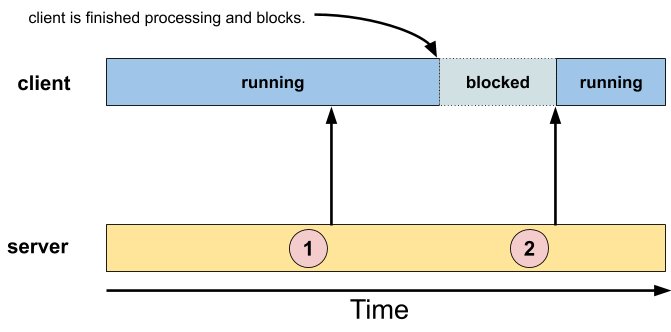
In it, a client prepares to receive messages from a server, but doesn't know when to expect them — the messages are not only asynchronous to the client, but are also (from a client / server point of view) "unsolicited", in that the client didn't explicitly request them (like it did in the previous model, above).
The client designates a function (the "event handling function") to be called when messages arrive from the server, but otherwise continues about its business.
At the server's discretion (circles "1" and "2" in the diagram above), messages are sent asynchronously to the client, and handled by the client's designated function.
Note that the client may already be running when a message is sent (as in circle "1"), or the client may have nothing to do and be waiting for a message to be sent (as in circle "2").
It is not a requirement that the client be waiting for a message.
Asynchronous messaging complexity
Breaking up asynchronous messaging into the above (somewhat arbitrary) categories is meant to show typical usage patterns, but isn't meant to be exhaustive.
In the most general case of asynchronous messaging, you have zero or more client messages loosely associated with zero or more server replies. It's this "loose association" that adds the complexity in terms of your design process.
IPC models in FIDL
Now that we have an understanding of the IPC models and how they interact with FIDL's asynchronous messaging, let's see how they're defined.
We'll add the other models (fire and forget, and async call or event) to the protocol definition file:
1 library fidl.examples.echo;
2
3 @discoverable
4 protocol Echo {
5 EchoString(struct {
6 value string:optional;
7 }) -> (struct {
8 response string:optional;
9 });
10
11 SendString(struct { value string:optional; });
12
13 ->ReceiveString(struct { response string:optional; });
14 };
Lines 5-9 are the EchoString method that we discussed above — it's a
traditional function call message, where the client calls EchoString with an
optional string, and then blocks, waiting for the server to reply with another
optional string.
Line 11 is the SendString method. It does not have the -> return
declaration — that makes it into a "fire and forget" model (send only),
because we've told the FIDL compiler that this particular method does not have a
return associated with it.
Note that it's not the lack of return parameters, but rather the lack of return declaration that's the key here — putting "
-> ()" afterSendStringwould change the meaning from declaring a fire-and-forget style method to declaring a function call style method that doesn't have any return arguments.
Line 13 is the ReceiveString method. It's a little different — it
doesn't have the method name in the first part, but rather it's given after the
-> operator. This tells the FIDL compiler that this is an "async call" or
"event" model declaration.
FIDL Bindings
The FIDL toolchain takes in FIDL protocol and type definitions, like the examples shown above, and generates code in each target language that can "speak" these protocols. This generated code is referred to as the FIDL bindings, which are available in various flavors depending on the language:
- Native bindings: designed for highly sensitive contexts such as device drivers and high-throughput servers, leverage in-place access, avoid memory allocation, but may require somewhat more awareness of the constraints of the protocol on the part of the developer.
- Idiomatic bindings: designed to be more developer-friendly by copying data from the wire format into easier to use data types (such as heap-backed strings or vectors), but correspondingly somewhat less efficient as a result.
Bindings offer several various ways of invoking protocol methods depending on the language:
- Send/receive: read or write messages directly to a channel, no built-in wait loop (C)
- Callback-based: received messages are dispatched asynchronously as callbacks on an event loop (C++, Dart)
- Port-based: received messages are delivered to a port or future (Rust)
- Synchronous call: waits for reply and return it (Go, C++ unit tests)
Bindings provide some or all of the following principal operations:
- Encode: in-place transform native data structures into the wire format (coupled with validation)
- Decode: in-place transform wire format data into native data structures (coupled with validation)
- Copy/Move To Idiomatic Form: copy contents of native data structures into idiomatic data structures, handles are moved
- Copy/Move To Native Form: copy contents of idiomatic data structures into native data structures, handles are moved
- Clone: copy native or idiomatic data structures (that do not contain move-only types)
- Call: invoke protocol method
Client implementation
Regardless of the target language, the fidlc FIDL compiler generates client
code that has the following basic structure.
The first part consists of the administration and background handling, and consists of:
- some means of connecting to the server is provided
- an asynchronous ("background") message handling loop is started
- async call style and event style methods, if any, are bound to the message loop
The second part consists of implementations of the traditional function call or fire and forget style methods, as appropriate for the target language. Generally speaking, this consists of:
- creating a callable API and declarations
- generating code for each API that marshals the data from the call into a FIDL formatted buffer suitable for transmission to the server
- generating code to transmit the data to the server
- in the case of function call style calls, generating code to:
- wait for the response from the server
- unmarshal the data from the FIDL formatted buffer, and
- return the data via the API function.
Obviously, the exact steps may vary due to language implementation differences, but that's the basic outline.
Server implementation
The fidlc FIDL compiler also generates server code for a given target
language. Just like the client code, this code has a common structure regardless
of the target language. The code:
- creates an object that clients can connect to,
- starts a main processing loop, which:
- waits for messages
- processes messages by calling out to the implementation functions
- if specified, issues an asynchronous call back to the client to return the output
In the next chapters, we'll see the details of each language's implementation of the client and server code.
Why Use FIDL?
Fuchsia extensively relies on IPC since most functionality is implemented in user space outside of the kernel, including privileged components such as device drivers. Consequently the IPC mechanism must be efficient, deterministic, robust, and easy to use:
IPC efficiency pertains to the computational overhead required to generate, transfer, and consume messages between processes. IPC will be involved in all aspects of system operation so it must be efficient. The FIDL compiler must generate tight code without excess indirection or hidden costs. It should be at least as good as hand-rolled code would be where it matters most.
IPC determinism pertains to the ability to perform transactions within a known resource envelope. IPC will be used extensively by critical system services such as filesystems, which serve many clients and must perform in predictable ways. The FIDL wire format must offer strong static guarantees such as ensuring that structure size and layout is invariant thereby alleviating the need for dynamic memory allocation or complex validation rules.
IPC robustness pertains to the need to consider IPC as an essential part of the operating system's ABI. Maintaining binary stability is crucial. Mechanisms for protocol evolution must be designed conservatively so as not to violate the invariants of existing services and their clients, particularly when the need for determinism is also considered. The FIDL bindings must perform effective, lightweight, and strict validation.
IPC ease of use pertains to the fact that IPC protocols are an essential part of the operating system's API. It is important to provide good developer ergonomics for accessing services via IPC. The FIDL code generator removes the burden of writing IPC bindings by hand. Moreover, the FIDL code generator can produce different bindings to suit the needs of different audiences and their idioms.
Goals
FIDL is designed specifically to optimize for these for characteristics. In particular, the design of FIDL aims to satisfy the following goals:
Specificity
- Describe data structures and protocols used by IPC on Zircon.
- Optimized for interprocess communication. Although FIDL is also used for persisting to disk and for network transfer, its design is not optimized for these secondary use cases.
- Efficiently transport messages consisting of data (bytes) and capabilities (handles) over Zircon channels between processes running on the same device.
- Designed specifically to facilitate effective use of Zircon primitives. Although FIDL is used on other platforms (e.g. via ffx), its design puts Fuchsia first.
- Offers convenient APIs for creating, sending, receiving, and consuming messages.
- Perform sufficient validation to maintain protocol invariants (but no more than that).
Efficiency
- Just as efficient (speed and memory) as using hand-rolled data structures would be.
- Wire format uses uncompressed native datatypes with little-endianness and correct alignment to support in-place access of message contents.
- No dynamic memory allocation is required to produce or to consume messages when their size is statically known or bounded.
- Explicitly handle ownership with move-only semantics.
- Data structure packing order is canonical, unambiguous, and has minimum padding.
- Avoid back-patching pointers.
- Avoid expensive validation.
- Avoid calculations that may overflow.
- Leverage pipelining of protocol requests for asynchronous operation.
- Structures are fixed size; variable-size data is stored out-of-line.
- Structures are not self-described; FIDL files describe their contents.
- No versioning of structures, but protocols can be extended with new methods for evolution.
Ergonomics
- Programming language bindings maintained by Fuchsia team:
- C, New C++, High-Level C++ (Old), Dart, Go, Rust
- Keeping in mind we might want to support other languages in the future, such
as:
- Java, JavaScript, etc.
- The bindings and generated code are available in native or idiomatic flavors depending on the intended application.
- Use compile-time code generation to optimize message serialization, deserialization, and validation.
- FIDL syntax is familiar, easily accessible, and programming language agnostic.
- FIDL provides a library system to simplify deployment and use by other developers.
- FIDL expresses the most common data types needed for system APIs; it does not seek to provide a comprehensive one-to-one mapping of all types offered by all programming languages.
Workflow
This section recaps the workflow of authors, publishers, and consumers of IPC protocols described using FIDL.
Authoring FIDL
The author of a FIDL based protocol creates one or more *.fidl files to describe their data structures, protocols, and methods.
FIDL files are grouped into one or more FIDL libraries by the author. Each library represents a group of logically related functionality with a unique library name. FIDL files within the same library implicitly have access to all other declarations within the same library. The order of declarations within the FIDL files that make up a library is not significant.
FIDL files of one library can access declarations within another FIDL library by importing the other FIDL module. Importing other FIDL libraries makes their symbols available for use thereby enabling the construction of protocols derived from them. Imported symbols must be qualified by the library name or by an alias to prevent namespace collisions.
Publishing FIDL
The publisher of a FIDL based protocol is responsible for making FIDL libraries available to consumers. For example, the author may disseminate FIDL libraries in a public source repository or distribute them as part of an SDK.
Consumers need only point the FIDL compiler at the directory that contains the FIDL files for a library (and its dependencies) to generate code for that library. The precise details for how this is done will generally be addressed by the consumer's build system.
Consuming FIDL
The consumer of a FIDL based protocol uses the FIDL compiler to generate code suitable for use with their language runtime specific bindings. For certain language runtimes, the consumer may have a choice of a few different flavors of generated code all of which are interoperable at the wire format level but perhaps not at the source level.
In the Fuchsia world build environment, generating code from FIDL libraries will be done automatically for all relevant languages by individual FIDL build targets for each library.
In the Fuchsia SDK environment, generating code from FIDL libraries will be done as part of compiling the applications that use them.
Getting Started
If you'd like to learn more about using FIDL, the Guides section has a number of developer guides and tutorials that you can try. If you are developing on Fuchsia and would like to learn about how to use bindings for an existing FIDL API, you can refer to the FIDL bindings reference. Finally, if you would like to learn more about FIDL or would like to contribute, check out the FIDL language reference, or the contributing doc.