
| RFC-0117: Component fuzzing framework | |
|---|---|
| Status | Accepted |
| Areas |
|
| Description | A Fuchsia-native, cross-process fuzzing framework. |
| Issues | |
| Gerrit change | |
| Authors | |
| Reviewers | |
| Date submitted (year-month-day) | 2021-05-24 |
| Date reviewed (year-month-day) | 2021-07-28 |
Summary
Guided fuzzing is an effective way of reducing bugs and increasing confidence in a platform, but there currently is no fuzzing framework available that can fuzz across multiple process boundaries as found in Fuchsia component topologies. This document proposes a design for such a framework that shares coverage and test inputs across processes and within test realms, allowing components to be fuzzed in their most typical configurations.
Motivation
Program testing can be used to show the presence of bugs, but never to show their absence!
Guided fuzzing is a process of testing software in a feedback loop with generated data:
- A fuzzer generates some test input data and uses it to test the target software.
- If the test results in a failure, the fuzzer records the input and exits.
- Target software produces feedback that is collected by the fuzzer.
- The fuzzer uses the feedback to generate additional test inputs, and repeats.
Guided fuzzing is extremely useful for finding software errors that are unrelated to project requirements (and therefore often untested). By automating test coverage, it can also improve developers' confidence of critical portions of the system that have security, correctness, and/or stability considerations.
Guided fuzzing frameworks can be described using the following taxonomy:
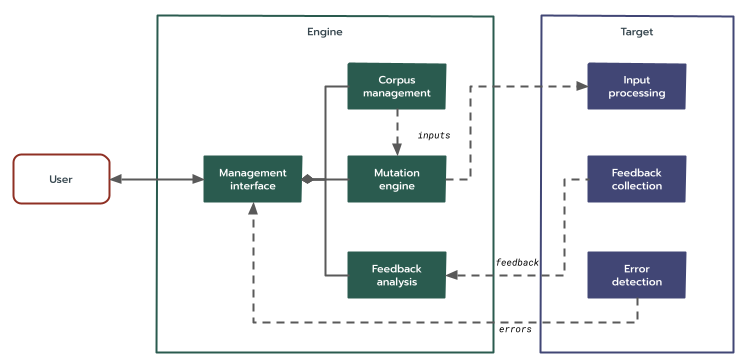
- Engine: The target-agnostic feedback loop.
- Corpus management: Maintains a collection of fuzzing inputs (a
corpus). Records new inputs and modifies existing ones (e.g. merging).
- The seed corpus is a set of handcrafted initial inputs.
- The live corpus is a continually updated set of generated inputs.
- Mutators: A set of mutation strategies and a source of deterministic pseudo-randomness used to create new inputs from the corpus.
- Feedback analysis: Dispositions an input based on its feedback.
- Management interface: Interacts with the user to coordinate workflows:
- Exercising the target with a specific input, i.e. performing a single fuzzer run.
- Fuzzing a target, i.e. performing a (possibly indefinite) sequence of fuzzer runs.
- Analyzing or manipulating a given corpus.
- Responding to a detected error and/or processing the artifact that caused it.
- Corpus management: Maintains a collection of fuzzing inputs (a
corpus). Records new inputs and modifies existing ones (e.g. merging).
- Target: The specific target realm being fuzzed.
- Input processing: Maps the fuzzer input for a single run to the code under test, e.g. via a specific function, an I/O pipe, etc.
- Feedback collection: Observes the behavior caused by an input. May collect hardware or software traces, code-coverage data, timings, etc.
- Error detection: Determines when an input has caused an error. Collects and records test artifacts, e.g. the input, logs, backtraces, etc.
Several of these aspects may require specific support from the OS and/or its toolchain, such as feedback collection and error detection. Currently on Fuchsia, the most fully supported fuzzing framework is libFuzzer, which is delivered via the prebuilt clang toolchain as a compiler runtime. Support has been added both to the sanitizer_common runtime used to collect code coverage feedback, and to libFuzzer itself to detect exceptions. Along with a set of GN templates and host tools, these allow developers to quickly develop fuzzers for libraries on Fuchsia.
Unlike Linux, however, on Fuchsia the basic executable units of software are components, not libraries. Using existing guided fuzzing frameworks to fuzz components is cumbersome, as the granularity of their feedback is either too narrow (e.g. libFuzzer in a single process), or too broad (e.g. TriforceAFL on an instance of qemu).
An ideal framework for fuzzing components in Fuchsia has the following features:
- Integration with existing continuous fuzzing infrastructures, such as ClusterFuzz.
- A modular approach that can leverage platform-agnostic portions of other fuzzing frameworks, e.g. mutation strategies.
- A high performance, cross-process code coverage mechanism.
- Integration with existing Fuchsia workflows, such as
ffx. - A hermetic environment that can isolate the components under test and/or provide mock components for their dependencies.
- Unmodified source for target components.
- A robust and flexible approach to analyzing execution and detecting errors.
- A developer story similar to other styles of testing within Fuchsia.
Design
This design tries to:
- Be idiomatic to Fuchsia.
- Reuse existing implementations.
At a high-level the design leverages the test runner framework and adds:
- A
fuzzer_engineto drive fuzzing. - An
ffxplugin and fuzz manager to interact with and manage fuzzers. - A
fuzz_test_runnerto connect thefuzzer_engineto the fuzz manager.
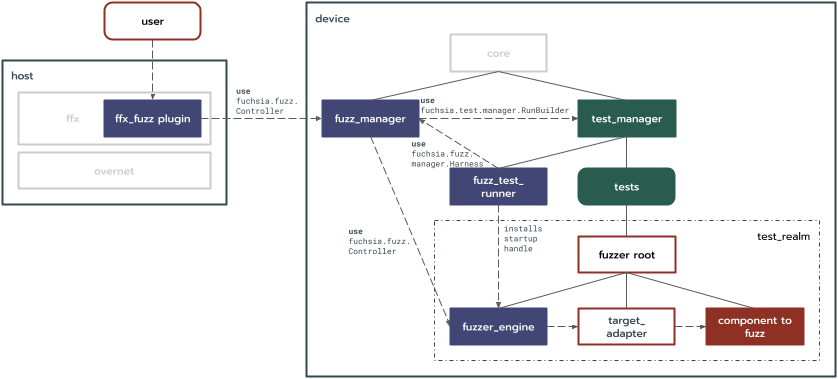
This section of the document is organized roughly according to control flow; i.e. it starts with a human or bot desiring to perform a fuzzing task and works towards the target realm being fuzzed. The reader should be aware that some sections refer to concepts described in detail in subsequent sections.
ffx fuzz host tool
Users (both humans and bots) interact with the framework via an
ffx plugin. This plugin will be able to communicate with a
fuzz_manager service via:
- The
fuchsia.fuzzer.Managerprotocol. - The data transfer protocol.
The subcommands of ffx fuzz mirror those of fx fuzz, e.g.:
analyze: Report coverage info for a given corpus and/or dictionary.check: Check on the status of one or more fuzzers.coverage: Generate a coverage report for a test.list: List available fuzzers in the current build.repro: Reproduce fuzzer findings by replaying test units.start: Start a specific fuzzer.stop: Stop a specific fuzzer.update: Update the BUILD.gn file for a fuzzer corpus.
Fuzz manager
The test runner framework provides two important features:
- It makes it easy to create complex yet hermetic test realms and drive them with customizable test runners.
- It provides the means to collect important diagnostics such as logs and backtraces.
Moreover, a single fuzzing run can be naturally expressed in the terminology of the component testing framework: the code is exercised with a given test input, and can be thought of as having passed or failed depending on whether an error occurred.
However, fuzz testing does differ from other forms of testing, and this difference is amplified when comparing continuous fuzzing to continuous testing:
- The test inputs are not known a priori.
- Test inputs are generated as a result of fuzzing.
- A continuous fuzzing infrastructure such as ClusterFuzz will have many instances of a fuzzer and will "cross-pollinate" their test inputs while fuzzing is ongoing.
- Fuzz test execution is open-ended. Fuzz tests never really "pass", they only
fail or are stopped early.
- A consequence is the need to provide on-demand status that includes details not typically provided by other tests, such as execution speed, total feedback collected, memory consumed, etc.
- This status needs to be provided on an ongoing basis to the human or fuzzing infrastructure bot that is monitoring the fuzzer's execution.
- Fuzz test results are richer than simply pass/fail.
- On failure, outputs need to include the triggering input as well as any associated logs and backtraces.
- On early termination, outputs may include accumulated feedback and recommended parameters (e.g. dictionaries) for future fuzzing.
- A fuzzed realm can be used for several different workflows that the fuzzing infrastructure chooses to perform in succession, e.g. "Fuzz for a while. If an error is found, cleanse it, otherwise, merge and compact the corpus". Representing each step as a test suite leads to significant work extracting state from one step only to restore it on the next.
Some of these can be addressed by extending the test runner framework, e.g. it
could provide structured outputs. However, using this approach for all the
fuzzing needs would add significant capabilities to other tests that do not need
them. For this reason, the design adds a new fuzz_manager that:
- Provides the management interface to users via
ffx. - Interacts with the
test_managerto launch fuzzers within a fuzzed realm in the test runner framework. - Provides a
fuchsia.fuzzer.manager.Harnessfor those fuzzers to connect back and service user requests. - Provides a data transfer protocol to facilitate injecting data into or extracting data from fuzzers.
The test runner framework is then modified as follows:
- A new
fuzz_test_runneris added. This runner builds on the existingelf_test_runnerto start thefuzzer_engineand pass it the fuzzer URL. - The
test_manageris modified to route thefuchsia.fuzzer.manager.Harnesscapability to thefuzz_test_runner. This capability is not routed to tests, and the hermeticity of non-fuzzers is unaffected. - The
fuzz_test_runnercreates a channel pair for thefuchsia.fuzzer.Controllerprotocol. It installs one end as a startup handle in thefuzzer_engineand usesfuchsia.fuzzer.manager.Harnessto pass the other to thefuzz_manager.
Fuzzer engine
The fuzzer_engine is a component of fuzzed realm. In terms of the
fuzzer taxonomy, it:
- Implements the
fuchsia.fuzzer.Controllerprotocol to provide the management interface. - Creates and uses a storage capability to manage each corpus.
- Mutates inputs from the corpus to create new test inputs. (e.g. links against libMutagen).
UsesanAdaptercapability to send new inputs to be processed.Exposesafuchsia.fuzzer.ProcessProxycapability that instrumented remote processes in the fuzzed realm can use to provide collected feedback and report errors.- Analyzes the feedback.
If fuzzing is considered as a series of tests with different input, then one approach is to having the fuzzer engine instantiate a fresh test realm for each input, i.e. have a test runner perform each fuzzing run in succession. The major problem with such an approach is the performance of the feedback analysis and mutation loop. Fuzzer quality is directly tied to throughput, and the main loop must be extremely fast: the overhead of "mutate, process input, collect feedback, and analyze feedback" should be on the order of microseconds.
For this reason, the fuzzer engine is included in the test realm itself in a manner similar to the test driver used for testing complex topologies. Shared VMOs coordinated by eventpairs are used to transfer test inputs to the fuzz target adapter and feedback from instrumented remote processes with the lowest possible latency.
The fuzzer engine is started by a fuzz_test_runner. This runner is extremely
similar to the existing elf_test_runner, with one significant addition:
It creates a channel pair for the fuchsia.fuzzer.Controller protocol. It
installs one end of this pair as a startup handle in the fuzzer_engine. It
passes the other to the fuzz_manager using the fuchsia.fuzz.manager.Harness
capability routed to it by the test_manager. This allows test_manager to
provide the Harness capability only to the fuzz_test_runner and the fuzzers
it starts, rather than to all tests.
Target adapter
The fuzz target adapter performs the input processing role in the fuzzer taxonomy. Using the shared VMO and eventpair described above, it takes the test inputs generated by the fuzzer engine and maps them to specific interactions with the instrumented remote processes of the target realm being fuzzed.
These specific interactions are provided by the fuzzer author and are typically the contribution referred to as "writing a fuzzer".
A fuzzer author can provide their own custom implementation of a fuzz target adapter, or use one of the provided scaffolds.
Examples of possible adapter scaffolds include:
llvm_fuzzer_adapter: Expects authors to implement LLVM's fuzz target function.- For C/C++, authors implement:
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size);- For Rust, authors implement a method with
#[fuzz]proc_macroattribute. - For Go, authors implement:
func Fuzz(s []byte);realm_builder_adapter: In addition to the LLVM fuzz target function, authors implement a method that modifies a providedRealmBuilder. The adapter provides a default builder to this function and uses the result to build the realm of components to be fuzzed. Authors can modify it by adding additional routes, capabilities, mocks, etc.:pub trait FuzzedRealmBuilder { fn extend(builder : &mut RealmBuilder); }libfuzzer_adapter: Similar expectations tollvm_fuzzer_adapter, but its component manifest omits the fuzzer engine, exposes theControllercapability itself, and links directly against libFuzzer. This distinctly different component topology allows conventional library fuzzing with libFuzzer in this framework.honggfuzz-persistent-adapter: Expects fuzzer authors to implement:extern HF_ITER(uint8_t** buf, size_t* len);honggfuzzitself is not currently supported, but fuzz target functions written for it can still integrate with this framework.
Note that the target adapter can and should also link against the remote library and act as an instrumented remote process along with those in the instrumented target.
Instrumented remote processes
In order to collect feedback and detect errors, all processes within the target
realm being fuzzed need to be built with additional instrumentation (e.g.
SanitizerCoverage). For fuzzers built in-tree, this can be achieved via a
toolchain variant that propagates flags and deps to a GN target's
dependencies. Required flags, e.g. -fsanitize-coverage=inline-8bit-counters,
will be documented to also allow out-of-tree compilation.
Additionally, the processes also need a fuchsia.fuzzer.ProcessProxy client
implementation. The same toolchain variant described above can automatically add
a dependency to link processes for in-tree fuzzers against a remote library.
The remote library provides, in terms of the fuzzing taxonomy:
- Feedback collection via callbacks, e.g.
__sanitizer_cov_inline_8bit_counters_init. - Early startup connection to the
fuzzer_engine'sProcessProxy. - Background threads that can detect errors, e.g. by monitoring exceptions, memory usage, etc.
Out-of-tree fuzzers can provide their own client implementations. Adding the
fuchsia.fuzzer.ProcessProxy FIDL interface and remote library implementation
to the SDK will make writing out-of-tree fuzzers easier.
Finally, the needed compile-time modifications are only transformations on LLVM IR. All other modifications are link-time only. This enables service providers to provide "fuzzing as a service" to SDK consumers who are willing to provide LLVM bytecode for their components, without requiring source code.
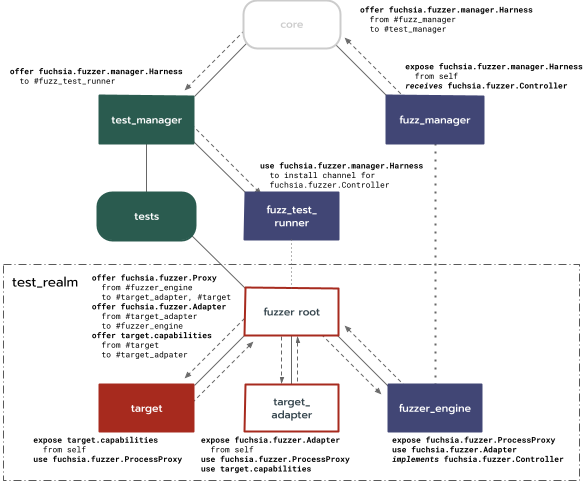
Component Topology
Putting all of the above together, fuzzer component topology includes:
core: The system root component.fuzz_manager: Bridge in the root realm between the fuzzer and the host tool.test_manager: As in the test runner framework.target_fuzzer: Fuzzed realm entry point.fuzzer_engine: Target-agnostic fuzzing driver.target_adapter: Target-specific component with user-provided input processing code.instrumented_target: Component being fuzzed.
The adapter and target components may have additional children, such as
mocks and the target realm being fuzzed.
The interactions of the pieces described above can be illustrated as follows:
FIDL interfaces
The framework adds two FIDL libraries: one for interacting with the
fuzz_manager, and another for interacting with the fuzzers themselves.
fuchsia.fuzzer.manager
Types defined by fuchsia.fuzzer.manager include:
LaunchError: An extensibleenumlisting errors related to finding and launching a fuzzer.
Protocols defined by fuchsia.fuzzer.manager include:
fuchsia.fuzzer.manager.Coordinator: Served byfuzz_managerto the user viaffx. Includes a method to start a fuzzer and connect afuchsia.fuzzer.Controller, and a method to stop fuzzers.fuchsia.fuzzer.manager.Harness: Served byfuzz_managerto thefuzz_test_runner, via static routing throughcoreandtest_manager. The runner uses this protocol to pass one end of a channel to the manager that can be used for thefuchsia.fuzzer.Controllerprotocol.
fuchsia.fuzzer
Types defined by fuchsia.fuzzer include:
Options: An extensibletablewith parameters to configure execution, error detection, etc.Feedback: A flexibleunionrepresenting target feedback, e.g. code coverage, traces, timings, etc.Status: An extensibletablewith various fuzzing metrics, e.g. total coverage, speed, etc.,FuzzerError: An extensibleenumlisting error categories, e.g. those recognized by ClusterFuzz.
Protocols defined by fuchsia.fuzzer include:
fuchsia.fuzzer.Controller: Provided by thefuzzer_engine, and passed to thefuzz_managervia thefuzz_test_runner. Proxied by thefuzz_managerto the user. Includes methods to transfer inputs to or artifacts from the fuzzer, and perform workflows on a fuzzer like input minimization, corpus merging, and normal fuzzing.fuchsia.fuzzer.CorpusReader: Requested fromfuchsia.fuzzer.Controller. Used to get inputs from a specific seed or live corpus.fuchsia.fuzzer.CorpusWriter: Requested fromfuchsia.fuzzer.Controller. Used to add inputs to a specific seed or live corpus.fuchsia.fuzzer.Adapter: Provided to thefuzzer_engineby the developer-providedtarget_adapter. Includes a method to register the coordinating eventpair and the shared VMO used to send test inputs.fuchsia.fuzzer.ProcessProxy: Provided by thefuzzer_engineto each instrumented process in the fuzzed realm. Includes methods to register the coordinating eventpair and to register shared VMOs used to provide feedback.
Build utilities
The framework provides a fuchsia_fuzzer_package GN template to developers.
This allows them to:
- Automatically include the fuzzer_engine.
- Produce metadata that can be used by tooling, e.g. the location of a seed corpus.
- Build integration tests instead of fuzzers when a non-fuzzing toolchain variant is selected, as described in the Testing section.
- Reuse the build rules for the components under test from relevant integration tests.
The framework also includes a component manifest shard that includes
common elements needed for fuzzers, e.g. the fuzzer_engine and its
capabilities, the fuzz_test_runner, etc. A component manifest for a fuzzer
consists of:
- The default fuzzer shard.
- A URL to the target-adapter component.
- A URL to manifest of the component(s) being fuzzed. This should typically be reusable from a relevant integration test.
Together, these build utilities designed to make the fuzzer development
experience similar to the integration test development experience.
Compare:

Implementation
The implementation plan is straightforward: develop and unit test individual classes in a series of changes, then assemble integration tests derived from libFuzzer as discussed in the Testing section.
Language
The fuzzer_engine and remote_library are implemented in C++ to facilitate
their idiosyncrasies:
- The
fuzzer_engineandremote_libraryboth must integrate with other C ABIs, e.g. libMutagen, SanitizerCoverage, etc. - Most
remote_libraryfunctionality happens "beforemainand afterexit", i.e. when LLVM modules are constructed and/or loaded, whenatexithandlers are run, or when a fatal exception has been raised. As a result, the framework needs explicit control over subtle details of ELF executables' lifecycles.
Other pieces, e.g. the realm_builder_adapter, are written in Rust.
Data transfer protocol
There are several situations in which users need to be able to provide or retrieve arbitrary amounts of data, including:
- Providing specific test inputs to execute, cleanse, or minimize.
- Synchronizing a fuzzer corpus with one on a developer's host, or across many ClusterFuzz instances.
- Extracting the test input that triggered an error.
To minimize maintenance burden, it is desirable to transfer this data using
overnet. However, any single transfer may exceed the size of a
single FIDL message over a Zircon channel. Instead, the Controller
protocol includes several methods that provide zx_socket objects which the
fuzzer engine uses to stream data to or from VMOs and/or locally stored files.
The data is streamed using a minimal protocol to read or write a named sequence of bytes. The protocol is not FIDL, as the data being sent may exceed the maximum length of a FIDL message. Still the named bytes sequences are conceptually equivalent to the following FIDL struct:
struct NamedByteSequence {
uint32 name_length;
uint32 size;
bytes:name_length name;
bytes:size data;
};
Stack unwinding
Currently, libFuzzer uses an unwinder from LLVM that assumes it is called from a POSIX signal handler executing on the thread that triggered the signal. For Fuchsia, this has necessitated a complex approach to handling exceptions that includes modifying the stack of a crashed thread and injecting a backtrace- preserving assembly trampoline to "resurrect" the thread in the unwinder.
None of this is needed if errors are not being handled by libFuzzer. Instead, different types errors are handled whichever way is most convenient and effective, e.g.:
- Exceptions are handled by the fuzzer engine, which receives an exception channel from the fuzz test runner that it created from its handle to the test job.
- Timeouts are also managed by the fuzzer engine.
- Sanitizer callbacks and OOMs are handled by the remote library, which notifies the fuzzer engine.
Performance
Fuzzing is not performed on production systems, and therefore has no impact on the performance of any shipping code. While the inclusion of fuzzing toolchain variants does have a minor impact on the performance of building Fuchsia, this framework will reuse the existing variants and should add no new impacts.
Similarly, the generation of unit tests from fuzzer on uninstrumented builds mirrors the current approach and is not expected to add any significant per-fuzzer testing costs over the current approach.
For the fuzzers themselves, the most critical metric for determining fuzzer quality is coverage per unit time, which can be derived by measuring two additional metrics:
- The total coverage of a fuzzer running over a fixed amount of time.
- The total number of runs performed in a fixed amount of time.
ClusterFuzz already monitors and publishes these metrics for each fuzzer on its dashboard.
Ergonomics
Ergonomics is an important facet of this design, as its impact depends on adoption by developers.
This framework attempts to make fuzzing as easy as possible in several ways. It allows developers to:
- Write fuzzers in both familiar and flexible ways, as noted in the target adapter section.
- Build fuzzers using the existing family of GN fuzzing templates.
- Run fuzzers using familiar workflows. The usage of
ffx fuzzis intentionally similar tofx fuzz. - Get actionable results. By integrating with ClusterFuzz bugs are filed automatically with symbolized backtraces and reproduction instructions.
Backwards Compatibility
Existing libFuzzer-based fuzzers implement the fuzz target function. By providing a libFuzzer-specific fuzz target adapter, these fuzzers will be able to work in this framework without any source modification.
Security considerations
This framework will not be used on a shipping product configuration. For devices
built in a fuzzing configuration, communication to and from the device will use
the existing authentication and secure communication features provided by
overnet and ffx.
The fuzzer outputs may have security considerations, e.g. a test input may cause an exploitable memory corruption. These concerns MUST be handled by the fuzzer operator (human or fuzzing infrastructure) in the same manner as any other exploitable bug report (e.g. correct labelling, prevention of unauthorized disclosure, etc.).
Privacy considerations
When considering privacy implications, no assumptions are made about how the fuzzer operator handles fuzzer outputs. These outputs consist of symbolized logs, error-causing inputs, generated dictionaries, and generated corpora. The logs are assumed to already be free of user data, as that is a separate and closely monitored privacy concern. The remaining outputs are all directly derived from test inputs. Thus, keeping fuzzer inputs free of user data is necessary and sufficient to keep fuzzer outputs free of user data.
There are three ways inputs are added to a fuzzer's corpora:
- As seed inputs. The seed corpus should be checked in to the source repository. The usual restrictions against including user data in the source repository apply.
- As manual addtions to the live corpus.
- This will most typically be done by the fuzzing infrastructure, e.g. ClusterFuzz, as it "cross-pollinates" fuzzers with inputs produced by other instances. In this case, the other instances will not contain user data, and the added inputs will not either.
- It is also possible for a human operator to add inputs via
ffx. The tool will display warnings about user data when adding manual inputs in this manner.
- As generated additions to the live corpus. These inputs are mutated from existing inputs. Since those inputs are user-data free, the generated ones are as well. It is possible some inputs may match some user-data by pure chance, e.g. the fuzzer manages to generate a valid username. However, in this case there is no clear association to user data.
No other data is included in the corpus, even if the fuzzer is non-hermetic (and non-deterministic!) and uses data from sources exposed by the test realm. The framework will not consider that data as part of the test input and will not save it.
The worst-case scenario is a fuzzer that is designed to be intentionally non-hermetic and uses exposed capabilities to send data out of the test realm to some other service that validates PII, e.g. return whether a username is valid. This would require a noticeable amount of effort to circumvent the fuzzing and test frameworks attempts to encourage hermeticity. And, since the external service is uninstrumented, this is no better than random guessing.
Additionally, in practice the fuzzers will be completely hermetic. They will not be run on product configurations with user data, but only locally when developing fuzzers and on ClusterFuzz.
Testing
The fuzzer engine, and target adapter libraries, and remote library are unit
tested using the usual approaches (e.g. GoogleTest, #[cfg(test)],
etc.). Additionally, integration tests use the default ELF test runner to run a
set of fuzzing workflows with purpose-built example targets, based on the
applicable subset from compiler-rt.
For fuzzers written using the framework, the framework will adopt the same approach as currently supported by the GN fuzzer templates: When building fuzzers in an uninstrumented build, the engine will be replaced by a test driver that simply executes each input in the seed corpus. This mitigates "bit-rot" by ensuring all fuzzers can build and run. It also acts as a regression test, especially if fuzzer authors maintain their seed corpora by adding inputs when fixing defects found by fuzzing.
Documentation
The fuzzing documentation tree will need to be updated with specific examples of using the new GN templates. Any other planned documentation changes (e.g. code-labs, etc.) should reflect this framework as well.
Drawbacks and alternatives
Potential drawbacks to the proposed approach include:
- Risk of performance degradation, mitigated by the implementation closely imitating performance-critical sections of highly-optimized fuzzers.
- Maintenance burden, offset by the savings of not needing to maintain awkward integrations, e.g. POSIX emulations.
- Coupling risk, e.g. the Test Runner Framework may change in a way that breaks
this design in the future, or may not be able to because of this design. If
this becomes a problem in the future, it could be addressed by incorporating
more of
test_manager's functionality directly intofuzz_manager, e.g. have the latter create isolated test realms directly.
These drawbacks are not as consequential as those of other alternatives that have been explored:
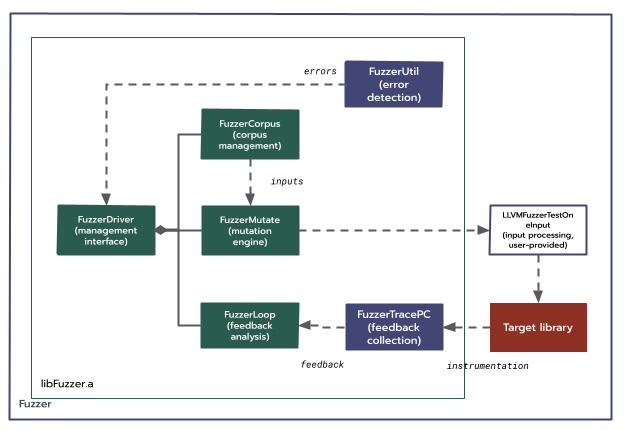
Library fuzzing only with libFuzzer.
Sufficient Fuchsia support has been added to libFuzzer to build fuzzers with it on Fuchsia. These have been successful in finding hundreds of bugs over the last few years.
At the same time, they are limited to single processes structured as libraries. Since components are the unit of executable software on Fuchsia, and components communicate extensively through FIDL, this leaves a large and growing amount of Fuchsia code "unfuzzable" by this approach.
In-process FIDL fuzzing.
Projects such as Chrome have tried to address RPC fuzzing by running client and server threads in a single process. This requires modifying both and client and server to run in a new, non-standard configuration. This can be reusable between services, but tends towards inflexible assumptions about component lifecycles and/or per language-binding re-implementations.
More fundamentally, it becomes increasingly difficult to fuzz the closure of interacting components. Many components have a non-trivial topology. To either run or mock the entire closure quickly becomes unsustainable in terms of complexity, overhead, and performance.
This approach is already available on Fuchsia, but has not seen widespread adoption due at least in part to these limitations.
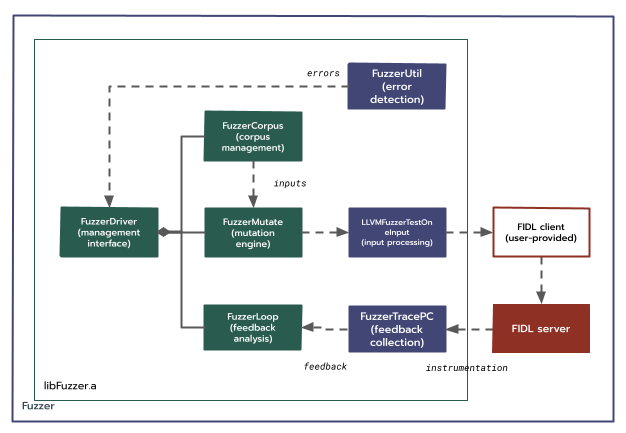
Single-service FIDL fuzzing.
An initial attempt at designing a cross-process FIDL fuzzing framework considered a single client and service. In this design, libFuzzer was linked against the service, and the client was maintained as a simple proxy. By retaining the FIDL interface between the client and server, it could keep the target in a more typical configuration, allowing for more flexible service lifecycles and less code needing to be reimplemented.
However, it does not address the problem of fuzzing component closures, and therefore provides very limited benefit over in-process FIDL fuzzing.
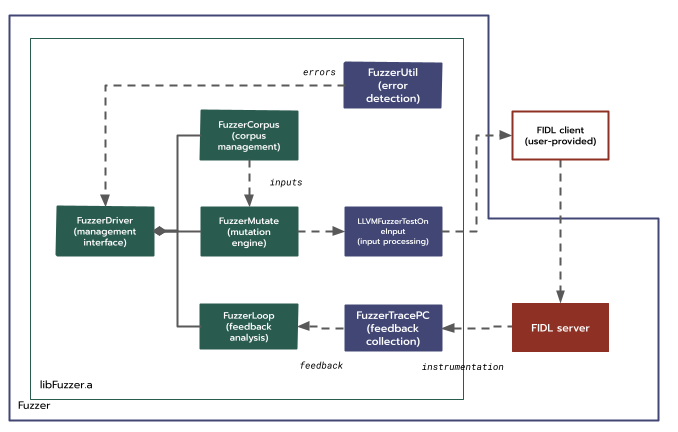
LibFuzzer with support for cross-process fuzzing.
As a general principle, reusing code has several advantages over reimplementing
it: the code is typically more "mature", with better performance and fewer bugs,
and has a lower and shared maintenance cost. For these reasons, another prior
attempt sought to extend libFuzzer rather than design and implement a new
fuzzing framework. A new compiler runtime, clang_rt.fuzzer-remote.a, would act
as the remote library above, while libFuzzer itself could be used as the engine.
Both of these compiler runtimes would use a pair of OS-specific IPC transport
libraries to proxy method calls to the other process.
In coordination with libFuzzer's maintainers, a series of changes implemented both runtimes and published them for review. Additionally, implementations of the IPC transport libraries were developed for both Linux and Fuchsia. The maintainers explicitly requested Linux support to allow for continuous testing, and it was again sent for review.
- On Linux, the shared memory was created as an anonymously mapped file, i.e.
via
memfd_create, and the signals were simply messages passed via Unix domain sockets. These sockets were also used to transfer the shared memory file descriptors, i.e. viasendmsgandrecvmsg. - On Fuchsia, the shared memory was implemented using VMOs, the signals via eventpairs, and the exchange via FIDL messages in a manner similar to the design in this proposal.
Unfortunately, during extended review, this approach became infeasible not for technical reasons but for process ones: Over time, the libFuzzer maintainers became increasingly concerned at the scope of the necessary changes required to make libFuzzer act in a way it was not originally designed for. Eventually, the team decided to defer landing the proposed changes indefinitely.
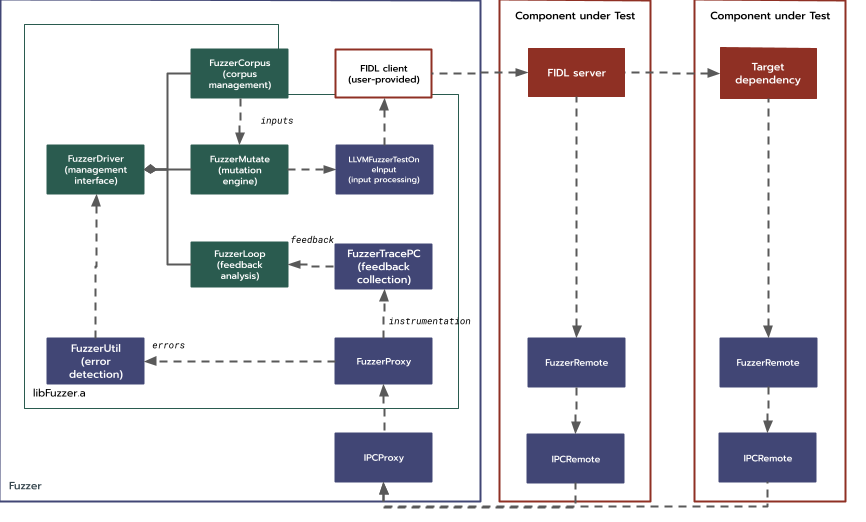
AFL
LibFuzzer is by no means the only fuzzing framework. Some, such as AFL, were explicitly designed to be cross-process from the start. However, there are a few reasons AFL would require more investment than might otherwise be assumed:
- AFL assumes it is fuzzing a single process, so it still faces the closure problem.
- AFL makes heavy use of certain Linux and/or POSIX features for feedback and
error detection. These include POSIX signals, but even more significantly,
considerable use of the
/procfilesystem, for which there is (correctly) no analogue on Fuchsia. - AFL uses a modified GCC to instrument the code, which is not part of Fuchsia's toolchain.
AFLplusplus is an improved fork of AFL maintained by a set of security researchers and CTF competitors. It has excellent performance on FuzzBench, and has modularized AFL. Unfortunately, the first version is deprecated, and the second is not ready yet (or at least is not mature enough to force altering the design above). Still, several pieces align with this proposal's design, and there are future opportunities to integrate them to improve the framework's coverage, speed, or both.
AFL with qemu
Additionally, there have been a few projects that combine AFL with qemu:
- afl-unicorn combines AFL with Unicorn, a project that exposes
the CPU emulation core of qemu with a fairly clean interface. This allows
fuzzing opaque binaries without source by collecting coverage feedback from
the CPU emulation. It is not suitable for a component framework for a few
reasons:
- The integration with qemu's core CPU emulation is complex enough that Unicorn has decided to forgo following qemu development and is locked to v2.1.2 (compared with current version 6.0.0 of qemu). Code that expects more recent emulation features is unlikely to function correctly.
- There is no significant need for opaque binary fuzzing. In fact, the design only requires the target code to be instrumented and linked against the remote library; LLVM byte code is sufficient to achieve this.
- TriforceAFL uses AFL on a complete, instrumented qemu instance. This
again allows fuzzing opaque binaries without source by collecting coverage
from qemu itself. It is not suitable for similar reasons as afl-unicorn:
- Again, there is no significant need for opaque binary fuzzing.
- Additionally, since the coverage collected is of the entire instance, fuzzing with TriforceAFL tends to be very noisy, especially with many components running. It typically is only useful for fuzzing extremely constrained configurations, such as a USB driver immediately after booting.