| RFC-0124: Decentralized Product Integration: Artifact Description and Propagation | |
|---|---|
| Status | Accepted |
| Areas |
|
| Description | A mechanism to describe and propagate artifacts for decentralized product integration. |
| Gerrit change | |
| Authors | |
| Reviewers | |
| Date submitted (year-month-day) | 2021-03-30 |
| Date reviewed (year-month-day) | 2021-08-30 |
Summary
This RFC describes a mechanism to make source or prebuilt artifacts from the Fuchsia source tree or from petal repositories available for the assembly of a Fuchsia Product outside of the Fuchsia source tree.
The mechanism comprises two essential aspects:
- Description of the artifacts using metainformation suitable to select compatible or otherwise desirable versions and variants of each artifact into the product to be assembled.
- Propagation of the artifacts such that they can be identified, referenced, and accessed from both the source repository where they originate and the integration repository where they are used.
Motivation
As laid out in the Decentralized Product Integration roadmap document, it is desired to assemble products outside of the Fuchsia source tree. To accomplish this, it is necessary to execute the standalone image assembly tools outside of the Fuchsia source tree, and to supply them with the necessary source or prebuilt artifacts. The Fuchsia source tree supplies, among other artifacts, Zircon (the Fuchsia kernel) and system packages. Various petal repositories supply packages for additional components such as product specific components and runners.
The Fuchsia source tree artifacts are produced in a regular cadence of versions. At the same times, versions of the Fuchsia SDK are produced as well, which are regularly imported by the petal repositores and used in turn to produce their own Fuchsia artifacts in the petal repositories' cadence of versions.
The release cadences of the petal repositories in general are not aligned with the release cadence of the Fuchsia source tree, and identifiers of the versions differ. A petal may choose to align its release candence with Fuchsia and for example produce a release for every release of the Fuchsia SDK.
Each such artifact version is also potentially produced in different variants, for example executables for various processor architectures, debug vs. optimized variants, variants designated by some "stable" vs. "latest" labels to distinguish trunk releases from stabilization branch releases, or variants with build time features enabled or disabled.
In order to assemble a product from such artifacts in an integration repository that is separate from the Fuchsia source tree, the artifacts must be made available to the integration repository. Moreover, the artifacts needed by the product integration must, for each version and variant of the product, be selected at suitable versions and variants of the artifacts.
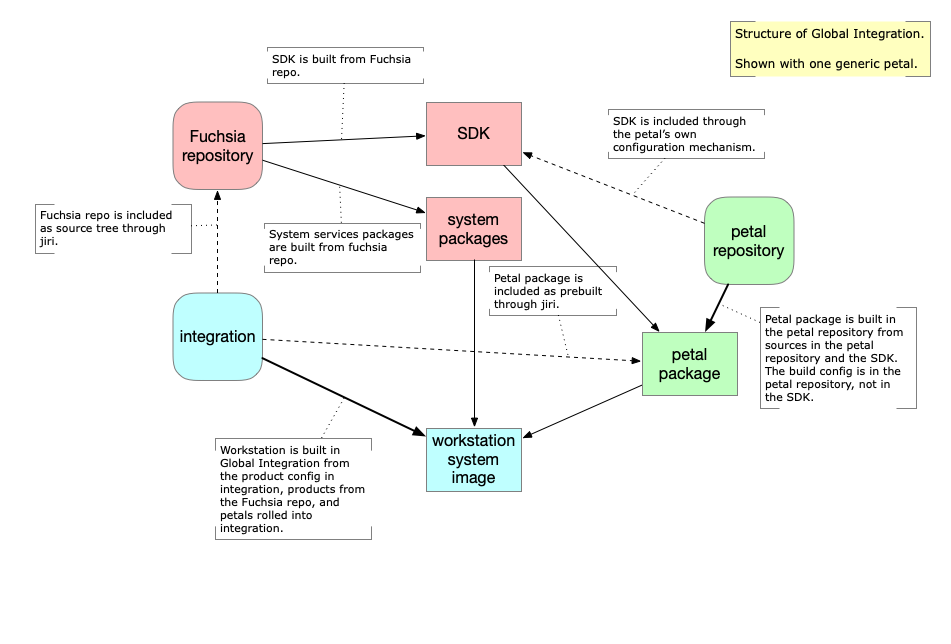
The current process of product integration is called Global Integration. The prebuilt artifacts from petal repositories are imported back into the Fuchsia source tree in a process called rolling. The Fuchsia products are then assembled as final build products from all artifacts from the Fuchsia source tree at the most recent source revision, together with the prebuilt packages from the petal repositories at the pinned version that has reached the integration repository. This process is shown in Figure 1.
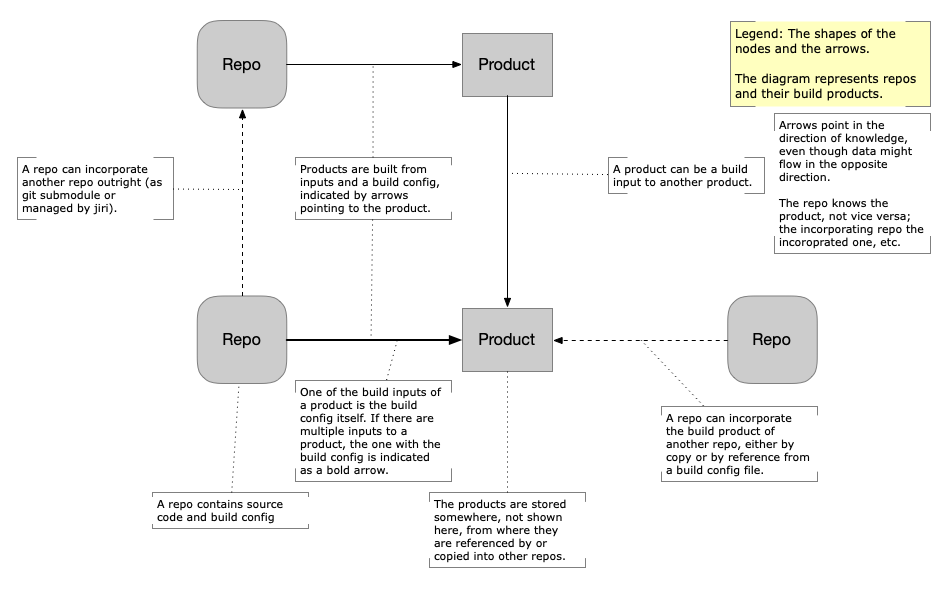
Figure 1 - Global Integration Process (legend)
This process has several drawbacks:
- Product assembly configuration is kept in the Fuchsia source tree, rather than under the control of the Product Owner .
- The version of the Fuchsia system is always ahead of the version of the Fuchsia SDK that any petal artifact was built with, because the Fuchsia system is built from the most recent source revision of the Fuchsia source tree, but the SDK of the petal artifacts had been built from an earlier revision.
- If artifacts from different petals have version compatibility requirements between each other (for example the Flutter runner and an aot-compiled Flutter application), these can only be maintained by specifically rolling them together in the same roller.
- Even if a petal artifact is under the control of a product owner, the version at which it is used for product integration is not, because the rolling process that makes a new version of an artifact available for product integration is coordinated with all other rollers for all other petal artifacts, and can be blocked by failing integration tests for any other product.
The proposed Decentralized Product Integration process improves upon those drawbacks as a direct conseqence of enabling product assembly outside the Fuchsia repository:
- Product assembly configuration is kept in a separate integration repository for each product, which can be controlled by the product owner.
- The Fuchsia artifacts can be selected at a version compatible with the Fuchsia SDK that the petal artifacts were built with, to achieve ABI compatibility between all the artifacts of the product. For example, something resembling ABI revision as stipulated in RFC-0002 and corresponding to the required 6 week ABI compatibility window is indicated by the first component of the Fuchsia release version number, which is incremented every time a Fuchsia release branch is created. Thus it will be possible to align all artifacts in a product on equal first components of Fuchsia release version numbers of the SDK they were built with.
- Artifact versions from different petal repositories can be selected directly such that they satisfy mutual compatibility requirements, and can be advanced to next versions according to directly specified constraints, without the need to set up a dedicated roller for the pair of artifacts. For example, a flutter app and the corresponding flutter runner can be selected on equal flutter and dart release version numbers directly.
- Products can select the version and variant of all contributing artifacts following their own release cadence without blocking on other products selecting that version too.
Stakeholders
Facilitator: abarth@google.com
Reviewers: aaronwood@google.com (Assembly), etryzelaar@google.com (SWD), wittrock@google.com (SWD), atyfto@google.com (Fuchsia Build Infrastructure), marvinpaul@google.com (TUF Server Infrastructure), jsankey@google.com (Security), enoharemaien@google.com (Security & Privacy), schilit@google.com (related RFC author).
Consulted: Members of Software Delivery team, Managed OS team, and Infrastructure team.
Socialization: A draft of this RFC was sent to the FEC discuss mailing list for comment, in addition to discussion with the consulted teams.
Design
Before the design overview is presented, some terminology and concepts are introduced or clarified.
Terminology
In the following paragraphs Bold Terms are the ones whose meaning is explained by the surrounding text.
The Fuchsia Source Tree comprises multiple different git repositories that are configured together into one source tree by a tool called jiri, based on configuration that is kept in a git repository called integration.git. The most important of those git repositories is fuchsia.git, but there are many others, including third party ones. The jiri configuration also controls the inclusion of prebuilt artifacts into dedicated parts of the source tree. The prebuilt artifacts themselves are stored under revision control in a storage service called CIPD, and the jiri configuration that describes the location and revision of the prebuilt artifacts in CIPD is under git revision control in the integration.git repository.
A regularly running build job called a Roller attempts to update the version of a prebuilt artifact included in the Fuchsia Source Tree. If all desired build products of the Fuchsia tree can be built and tested with the updated version of the artifact, the change to the Fuchsia tree is committed, and the updated-to version of the artifact is now the pinned one. There can be separate rollers for different prebuilt artifacts.
In the status quo, the Fuchsia Source Tree simultaneously takes the role of both the Source Repository for many of the artifacts used in Fuchsia Products and the Integration Repository where each Fuchsia Product is assembled from its parts.
Artifact refers to any ingredient used in the assembly of a product. Such artifacts are obtained from Source Repositories, either directly as one of the source items, or as a build product obtained from executing the build process in the repository. Most such artifacts are prebuilt Fuchsia packages, but they also comprise Zircon, the Fuchsia kernel, and may soon also comprise subassembly specification files. The Zircon kernel and prebuilt packages are prebuilt artifacts; a subassembly specification file is a source artifact.
The artifacts obtained from one Source Repository are eventually released to an Artifact Store. Such releases can be made manually, or they can happen automatically in a scheduled cadence. Either way the resulting artifacts are published to a dedicated Artifact Store for the source repository. The Artifact Store can be any place where the artifacts can be found from outside their source repository, without having to refer to the source repository, let alone execute its build process. As such, Artifact Stores can be e.g. a CIPD directory, a GCS bucket, or a TUF repository. For the process designed here, the specific kind of Artifact Store is not essential.
TUF Repositories are used for Software Delivery to Fuchsia devices, of newly rebuilt packages to developer Fuchsia devices or emulators in development, and of OTA updates to Fuchsia devices in production. The specific way of using TUF in Fuchsia on top of a content addressed storage service is especially suitable for storing Fuchsia packages, and since many of the artifacts are Fuchsia packages, there is a preference in this design to use TUF Repositories as the Artifact Store.
Attributes are key-value properties that describe artifacts such that their versions and variants can be discerned. The key describes a dimension of variability and the value is the place along that dimension the artifact is at. Attributes uniformly describe both versions and variants of artifacts. In most situations it's not necessary to distinguish attributes that describe versions from attributes that describe variants. The publisher of an artifact can specify attributes like the following:
- The CPU architecture variant,
x64vs.arm64. - The
debugvs.optimizedcompilation variant. - The commit version of the source repository from which the artifact was built.
- Build parameters with which the artifact was built.
- The Fuchsia SDK version the artifact was built with.
- The semantic version of the built artifact. For example, a Chromium release
version such as
M88.xxx, or a Cast release version such as1.56.xxx. - The API level and ABI revisions as stipulated by RFC-0002 of the Fuchsia system Artifacts, once implemented.
- The API level or SDK version provided by a petal, which are out of scope of RFC-0002 yet as important as the system ABI. For example, the release versions of the Flutter SDK a Flutter application was built with.
Transitive Attributes: Some attributes describe transitive properties of the artifacts, in that they pertain to properties of the inputs the artifacts were built from. For example, the Fuchsia SDK version, or the Flutter version are actually properties of precursor artifacts used to build the described artifact. It is anticipated that such transitive properties extend even further. Therefore, attribute values are allowed to be objects which contain key-value pairs in turn, recursively.
Dependency Attributes: Dependencies (including their versions and variants) of artifacts can be expressed as attributes too. However, Fuchsia packages are hermetic and as such already contain their dependencies. Therefore, dependencies will usually not appear often in attributes of Fuchsia artifacts.
Status Quo
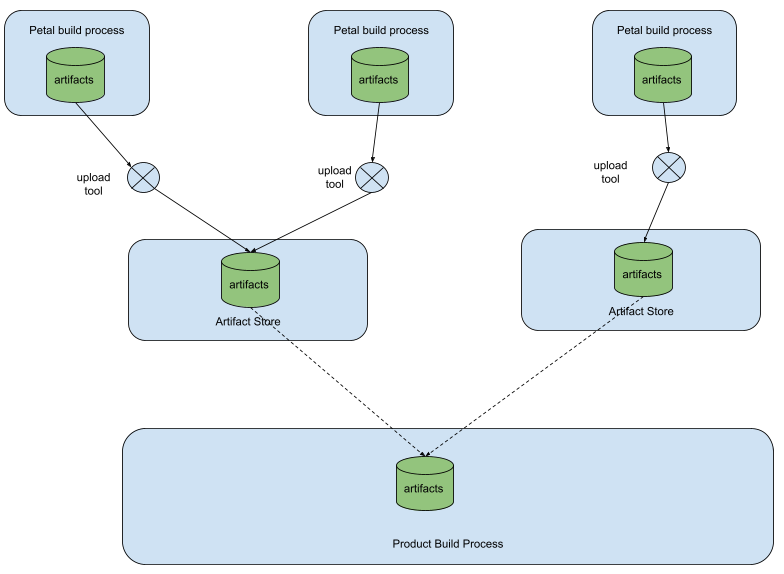
In the current Global Integration process, as illustrated in Figure 2, the petal build process uses a CIPD directory as its artifact store. The artifact store keeps the artifacts under a path name (called "package" in CIPD, with no direct relation to Fuchsia packages). CIPD supports the ability to store multiple "instances" under the same path name of the "package", and to attach "tags" and "refs" to the instances. The variant meta information is encoded in the pathname components of the stored artifact. The version metainformation is encoded in tags and refs of CIPD package instances. The product build process obtains the pinned version of the artifacts through rolling and always builds the product from the pinned versions of the petal artifacts.
Figure 2 - Current system structure
Propagation of extended metainformation through the artifact store
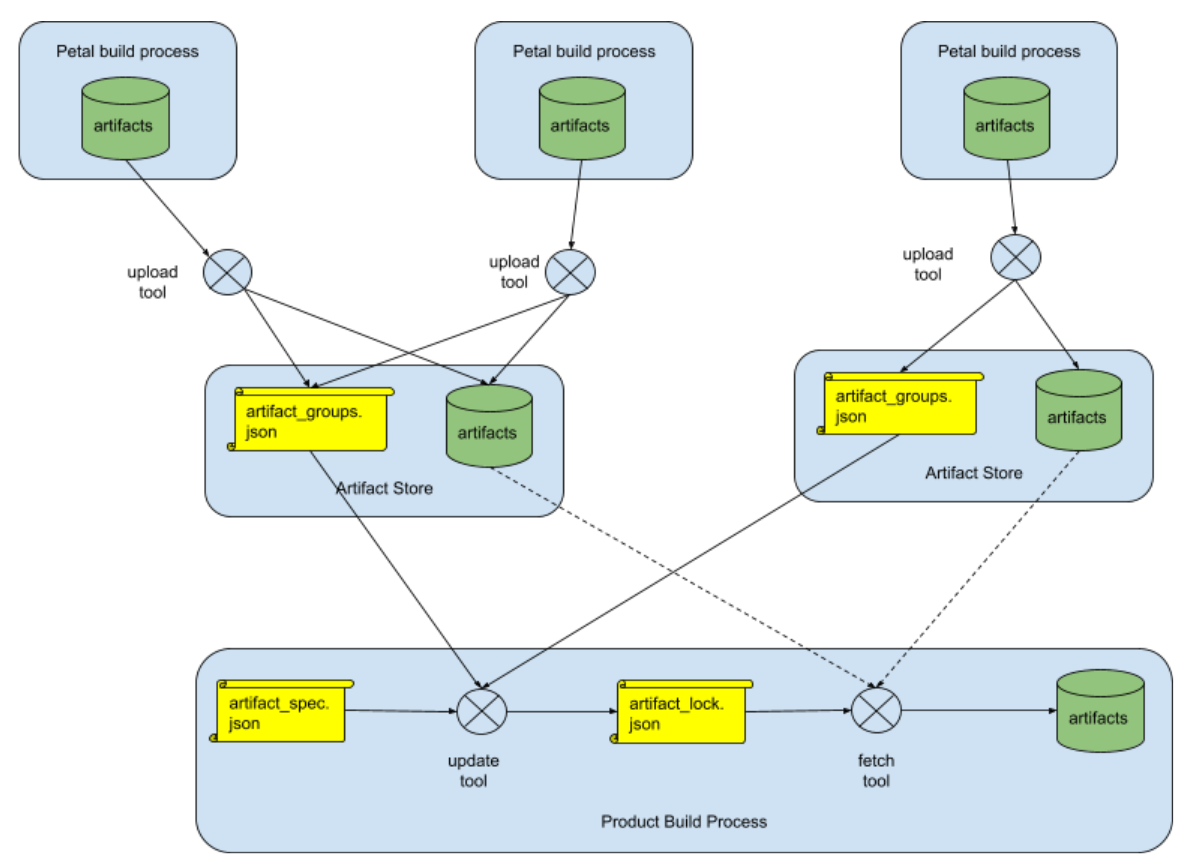
The design proposed here changes the structure of the artifact store in order to keep metainformation attributes of the released artifacts. Products can then select suitable artifacts based on criteria specified in terms of attribute values.
The design involves three additional config files, and three tools to operate on
the config files to interact with the artifact stores. The files are
artifact_groups.json, kept in the artifact store; artifact_spec.json and
artifact_lock.json, kept in the product integration repository. The tools
upload, update, and fetch operate on the files and the artifacts, as shown
in Figure 3, as follows:
- Each new release of a group of artifacts from a petal or Fuchsia Build
Process creates a new artifact group inside the artifact store associated
with the source repository. The attributes of the released artifacts are
recorded in the file
artifact_groups.json, which is also kept in the artifact store.- The Petal Build Process uses the
uploadtool to publish newly released artifacts to the artifact store and to update theartifact_groups.jsonfile.
- The Petal Build Process uses the
- In the product integration repository, an
artifact_spec.jsonfile keeps the lists from which artifact stores to obtain artifacts for a product assembly in this integration repository, and with what attributes.- The
updatetool is used to select the set of artifacts to actually be used for the assembly using theartifact_spec.jsonfile from the integration repository and theartifact_groups.jsonfiles from all artifact stores listed in theartifact_spec.jsonfile.
- The
- The set of artifacts selected by the
updatetool is stored in theartifact_lock.jsonfile.- The
fetchtool downloads all the artifacts mentioned in theartifact_lock.jsonfile in order to make them available to the Product Build Process in the integration repository.
- The
How these tools relate to the execution of build rules depends on the specific build system used in the product integration repository. See the implementation section for more discussion.
The tools allow the presence of multiple artifact_spec.json and
artifact_lock.json files in the integration repository.
Figure 3 - Relationship of all the cooperating parts
Logical structure inside the artifact store
The resulting logical structure of artifacts and artifact groups inside an artifact store looks like the following example:
└── artifact_groups
|
├── 92d483e5-ac7d-4029-a7db-e2ee6a8365c7
| |
| ├── web_engine
| |
| └── cast_runner
|
└── c907ff3f-cb15-4a7f-bb79-8cc23c0ff445
|
├── web_engine
|
└── cast_runner
Each release of a group of artifacts appears with an opaque name, and each artifact appears as an entry in the group with a recognizable name.
This structure is recorded, together with the associated attributes of the
release and of the individual artifacts as a JSON data structure in the
artifact_groups.json file, described in more detail below.
Uses of artifact and group names
The JSON data use the group names and artifact names to associate the recorded
attributes with the artifacts they describe. The names of both groups and
artifacts are used to reference them in expressions that select the artifacts
into a product assembly workspace, in the file artifact_spec.json. The
artifact names are also used as file names under which the fetch tool stores
their locally downloaded copies.
However, neither name is used to designate the storage location of an artifact
in the artifact store. Instead, all artifacts are stored under their content
addresses, and the content address is recorded for each artifact in
artifact_groups.json as the merkle property.
The content address used is the Fuchsia merkle root of
the immediate content of the artifact. Some artifacts, specifically Fuchsia
packages, are represented by further storage components ("blobs") that are
transitively contained in the immediate content of the artifact. These
additional components are stored under their content addresses, but not
explicitly mentioned in artifact_groups.json.
Uniqueness invariants
There are a few uniqueness invariants to be maintained in the Artifact Store. These invariants guarantee that artifacts can be unambiguously selected by referencing their names and attributes:
- The group name must be unique inside the artifact store over its entire history.
- The artifact name must be unique within each group.
- The attributes of each artifact in one group must be unique among all artifacts of the same name in all groups currently in the artifact store.
These uniqueness invariants are maintained by the upload tool when a new
artifact group is added to the artifact store. The update tool also checks the
uniqueness and refuses to compute an update if the invariants are not satisfied
for all the artifact_group.json files it accesses. The artifact store itself
does not need to play any role in maintaining these invariants.
Group names are opaque
It's tempting to name artifact groups after attribute values to make the artifact store more intelligible or navigable. However, this only works well when there are few attributes, and a fixed set of them. Once the attribute set scales to many attributes, and an open set of them, constructing names from them becomes tedious purely because of the combinatorial explosion of the number of possible permutations even of a single set of attribute values (i.e., is architecture first or last or in the middle?). Also reading such names is no longer easy on the eye, and maintaining the uniqueness invariant, especially across history, also is more cumbersome.
Therefore, since this design specifically aims to support large and open attribute sets, group names will be chosen to be opaque and to satisfy the required uniqueness invariants. In the example above the group names are random UUIDs. An alternative would be to use monotonically increasing padded integers.
The artifact_groups.json file
The artifact_groups.json file lists all the groups, the contained artifacts,
and the associated attributes inside that artifact store.
The following example shows the artifact_groups.json corresponding to the
artifact store example shown above. Attributes are associated with an artifact
group, in which case all the attributes apply to all artifacts in the
group. Attributes can also be applied to individual artifacts only.
The set of attributes itself is not prescribed by this design. All attributes are chosen and assigned by the build and release process that produces the artifacts in the source repository. Attributes assigned are merely required to maintain the uniqueness invariant above.
{
"schema_version": "https://fuchsia.dev/schemas/artifact_groups_schema.json",
"version": 15,
"artifact_groups": [
{
"name": "92d483e5-ac7d-4029-a7db-e2ee6a8365c7",
"attributes": {
"petal": "chromium.org",
"version": "chrominum_release_20210304",
"architecture": "arm64",
"sdk_version": "2.20210303.3.1",
"creation_time": "1622696983",
"commit": "b26e44e9910608a2d0aec9b38e003a04a2da06df"
},
"artifacts": [
{
"name": "web_engine",
"merkle":"90f67b10ded655852acb78a852ac5451486fc1e7378ce53368386244ce8f6e66",
"type": "package",
"attributes": {
"runner_version": "2.20210301.1.3"
}
},
{
"name": "cast_runner",
"merkle": "3394db36d228f4c719d055c394938c5a881ca6eea7ad3af0ad342e764cadc8b3",
"type": "package"
}
]
},
{
"name": "c907ff3f-cb15-4a7f-bb79-8cc23c0ff445",
"attributes": {
"petal": "chromium.org",
"version": "chrominum_release_20210402",
"architecture": "arm64",
"sdk_version": "2.20210303.3.4",
"creation_time": "1622157425",
"commit": "2dd76ad2298dfb869ef83c10b84b62485dc8a573"
},
"artifacts": [
{
"name": "web_engine",
"merkle": "acb78a852ac5451486fc1e7378ce53368386244ce8f6e6690f67b10ded655852",
"type": "package",
"attributes": {
"runner_version": "2.20210225.1.4"
}
},
{
"name": "cast_runner",
"merkle": "19d055c394938c5a881ca6eea7ad3af0ad342e764cadc8b33394db36d228f4c7",
"type": "package"
}
]
}
]
}
Each group object in the artifact_groups list contains 3 properties: name is
the name of the group, artifacts is the list of artifacts in the group, and
attributes are the attributes shared by all artifacts in the group.
Attributes that apply to only a single artifact are included in the object that represents that artifact directly. Attributes of this artifact are appended to attributes of the group to get the complete set of artifact attributes.
The version number is a monotonically increasing number. This number is used by
the update tool to protect against the accidental roll back to an older
version of the artifact_groups.json file.
Mutability of artifact groups and their attributes
In typical usage, each released build of a set of artifacts would be recorded as a new group. Thus group names, the set of artifacts in them, and most of their attributes are conceptually immutable. Exceptions would be attributes that reflect information about artifacts that arise after the artifacts are released. An example would be the changing test result status for artifacts from manual tests of the artifacts carried out after they are released. Attributes that reflect such information may be updated.
In principle, however, nothing precludes artifact group contents as well as names or attributes from changing over time. It is conceivable that this could be usefully employed in a product assembly pipeline, but no use will be made of it in the proposed application (see the implementation section below).
Product Build Process
The Product Build Process in the integration repository establishes an
artifact_spec.json file, called "spec file" below. This file lists the
artifacts needed by the product to be assembled in the integration repository,
the artifact stores to obtain them from, and the patterns and constraints of the
attributes of the artifacts. The type of the artifact store is described as
well, and multiple different types of artifact stores can co-exist in one spec
file.
Specifically, prebuilt artifacts can be stored in the integration repository itself, and can be referenced in the spec file as from an artifact store of type "local".
The Product Build Process in the integration repository employs the update
tool to match the artifact_groups.json files in all the artifact stores
mentioned in the spec file, and compute the set of specific artifact variants
and versions to use. This set is recorded in an artifact_lock.json file. This
file is meant to be committed as a source file in the repository.
The fetch tool reads the artifact_lock.json file and downloads all artifacts
to the integration repository. The artifacts are not meant to be submitted as a
source file to the repository. However, the artifacts are identified in the
artifact_lock.json file by their content addresses taken from the
artifact_groups.json files. This ensures that the committed content of
artifact_lock.json fully determines the content of the artifacts supplied to
the build, and thus that the product assembly build is hermetic and reproducible
with regard to the artifacts selected in the artifact_lock.json file.
Implementation
The design proposed here will first be implemented to move the workstation product integration to a separate repository.
The required details of the artifact_spec.json and how it is processed
against the artifact_groups.json files in order to produce the
artifact_lock.json file is described in another RFC.
Migration of existing petals and products
As long as petal prebuilts are still needed in the Fuchsia source tree (set up from integration.git), they need to be uploaded to both CIPD for consumption by the gn build rules in the Fuchsia source tree and to the artifact store used by out of tree products. Eventually some petal prebuilts will no longer be needed in the Fuchsia source tree and the upload to CIPD can stop.
There is no intention to replace the mechanisms to setup the Fuchsia source tree itself using jiri, as all the Fuchsia platform artifacts as well as the SDK and some products continue to be built from the Fuchsia source tree.
Artifact Store
The implementation for workstation and its petals will use TUF repositories as
the artifact stores. The only entry in the targets.json file of the TUF
repository is for the artifact_groups.json file. The artifacts themselves are
stored in the content addressed blob store maintained by the TUF server
infrastructure used for Fuchsia, and their corresponding blob addresses recorded
in the artifact_groups.json file.
Additionally, the artifacts could also be listed in targets.json under the
directories and artifact names, but nothing in this design requires it. (This is
just mentioned for historical completeness because it used to be done in case
someone would expect the targets.json entries. See the
alternatives section below.)
Fuchsia package structure dependencies
The three tools proposed here that interact with the artifact stores (upload,
update, fetch) operate on Fuchsia packages and as such, make assumptions about
the structure of Fuchsia packages. Specifically it is assumed that a Fuchsia
package consists of a meta.far blob that contains the content addresses,
expressed as merkle roots, of the other blobs that also
belong to the package. The list of blobs referenced in the meta.far is
obtained using tools supplied by the Fuchsia SDK, and thus the artifact storage
tools (upload, update, fetch) do not depend on the internal structure of the
meta.far.
Relation of tools with build rules
How the upload, update, and fetch tools relate to the execution of build
rules depends on the specific build system in the source repository, and the
product integration repository, as well as on what infastructure the build
executes on.
The upload tool is expected to be executed after the build system finished
building.
Usually, the update tool is expected to be used outside of build rules, before
the build executes.
The fetch tool may either be used before build rules execute, or if the build
system supports it, as part of the build system execution. For the workstation,
bazel is used as the build system, which supports setting up the
input file set in so called "workspace rules".
Names of the tool executables
The tools upload, update, fetch may eventually be implemented under other
names than the conceptual names used in this design. Specifically, they may be
implemented as plugins to the ffx tool, or as tools to be produced by bazel
build rules. An initial prototype implements them as python scripts called
artifact_upload.py, artifact_update.py, and artifact_fetch.py.
File syntax
The Syntax of the artifact_groups.json file is given by the
following JSON schema. The JSON schemata of the artifact_spec.json and
artifact_lock.json files are documented in a separate RFC.
{
"$schema": "https://json-schema.org/draft/2019-09/schema",
"$id": "https://fuchsia.dev/schemas/artifact_groups_schema.json",
"type": "object",
"additionalProperties": false,
"required": [
"contents",
"schema_version",
"version"
],
"properties": {
"schema_version": {
"type": "string"
},
"version": {
"type": "integer"
},
"artifact_groups": {
"type": "array",
"items": {
"type": "object",
"additionalProperties": false,
"properties": {
"name": {
"type": "string"
},
"attributes": {
"type": "object"
},
"artifacts": {
"type": "array",
"items": {
"type": "object",
"additionalProperties": false,
"required": [
"name",
"merkle",
"type",
],
"properties": {
"name": {
"type": "string"
},
"merkle": {
"type": "string"
},
"attributes": {
"type": "object"
},
"type": {
"type": "string"
}
}
}
}
}
}
}
}
}
File semantics
The file format semantics for artifact_groups.json is described here. The
detailed semantics of artifact_spec.json and artifact_lock.json are again
documented in a separate RFC.
{
"schema_version": SCHEMA_VERSION,
"version": VERSION,
"artifact_groups": [
ARTIFACT_GROUP,
...
]
}
SCHEMA_VERSION
A string that indicates the url of JSON schema of the
artifact_groups.json.
VERSION
An integer that indicates the version number of the
artifact_groups.json. This number should increase when a newer version is published.
ARTIFACT_GROUP
Each ARTIFACT_GROUP is an object whose format is the following:
{
"name": NAME,
"attributes": ATTRIBUTES,
"artifacts": [
ARTIFACT,
...
]
}
NAME
A String that provides a means to reference this artifact group.
ATTRIBUTES.
An object defined by publisher.
ARTIFACT
Each ARTIFACT is an object whose format is the following:
{
"name": NAME,
"merkle": MERKLE,
"type": TYPE,
"attributes": ATTRIBUTES
},
NAME
A String that contains the name of this artifact.
MERKLE
A String of the merkle root of the artifact.
TYPE
A String that contains the type of this artifact. If the
TYPEis"package", then this artifact in the blob referenced by its merkle root is themeta.farof a fuchsia package, and the blobs transitively referenced in themeta.farare always handled together with the meta.far blob. Otherwise, the artifact consists only of the single blob whose merkle is listed.
ATTRIBUTES
An object similar to ATTRIBUTES defined above. This is where the artifact specific attributes are defined.
Security Considerations
The design in this RFC does not change the trust model between the existing actors. This mechanism only changes the storage structure, not the trust relationship between the actors using the artifact stores, or between the actors and the artifact stores.
Trust Model
As in the status quo using CIPD as artifact store, the product build process needs to trust the artifact store. This trust is currently based on the access control and authentication the artifact store applies to the petal and Fuchsia build processes whence the artifacts are supplied to the store, and on the reliance on the build infrastructure and environment to resolve the configured names of the artifact stores to access the right artifact stores.
Once more artifact stores and product integration repositories are established, the bases for trust in them need to be assessed, and trustworthiness of the assembled product needs to be assessed correspondingly.
In the future, additional mechanisms above the currently used ones may be established, for example validation of signatures such as the ones on the TUF repositories. The mechanism designed here can support the propagation of relevant information based on which to assess trustworthiness, but the creation of such information is orthogonal.
Regarding TUF signatures specifically, it is important to note that such a signature only ever supplies evidence supporting the trustworthiness of the repository that hosts the artifacts. By itself it does not constitute a complete basis to assess the trustworthiness of the artifacts obtained from it, because that additionally depends on the control of the signing keys, the trustworthiness of the build process that produces the artifacts, and the trustworthiness of the transitive sources and tools the build process uses as inputs. In the case of the TUF implementation currently used for Fuchsia products, which signs any artifact uploaded to a service that maintains the repository, it also depends on the integrity of the ACLs and the authentication mechanism that let clients access that service.
Multiple petal build processes publish to same artifact store
Publishing source repositories are recommended to not share an artifact store, so they don't have to share trust relationship with the server, no matter how it is established. One example is for TUF implementation, publishers don't have to share signing keys.
There are also potential compromises introduced by multiple petal build processes publishing to the same artifact store. One example is one publisher might overwrite an artifact published by another. But this is out of the scope of this RFC, as in this RFC all the petal build processes publishing to an artifact store are operated by the same organization and thus can be coordinated properly. If we want to expand this to multiple organizations, a different coordination model needs to be designed.
Performance
As the number of items in the artifact_groups.json file gets larger, the time
complexity of finding the group that matches all the required attributes
increases at least linearly. If there are constraints across artifacts, it might
be supra-linear because the update tool needs to join multiple
artifact_groups.json files to do the selection. Artifact publishers may need
to evict artifact groups that are too old to help improve performance of the
client side update tool.
Download times for artifacts once selected may be considerable for large
products. This is no different from the status quo. The design presented here
has the advantage over the Global Integration that only prebuilt artifacts for
one product at a time need to be downloaded by the fetch tool to any one
integration repository. In current Global Integration, the union of prebuilt
artifacts for all known products needs to be downloaded during a jiri update.
Privacy considerations
The only new data being stored in the artifact store is the
artifact_groups.json file. It is up to the publisher of the artifact store to
not publish PII in the artifact_groups.json file.
Testing
The libraries used by the tools, e.g. for matching attribute patterns in
artifact_spec.json files against artifact_groups.json files, will be tested
by unittests.
For the operation of the tools as executables there will be integration tests operating from locally kept golden files.
For the end-to-end testing, there will be a "Hello World" product in its own repository that continuously exercises the machinery and can be monitored for failures.
Drawbacks, Alternatives, and Unknowns
Using other types of artifact store
Aside from TUF, there are other artifact stores that can be used. Examples are:
- CIPD,
- static HTTPS Server,
- GCS bucket,
- Git repository.
The appropriate structures to locate the artifacts under names that are their
content addresses can be created inside all these artifact stores, and metadata
can be maintained in an artifact_groups.json file, in the same way as in the
TUF repository used in the implementation proposed above.
TUF repository per release
Another alternative that was pursued in an earlier version of this design is a
TUF repository for each release of artifacts. Instead of creating a group for
all the artifacts of a release, the upload tool creates a new TUF repository
to host the artifacts. A well known lookup repository contains the
artifact_groups.json file recording the attributes. Instead of group names, it
would contain repository names for each artifact group.
The advantage of this method would have been the support for products that use ephemeral packages that are delivered to the device only when they are first used. Instead of or in addition to including packages in such release repositories in the product assembly, the repository would have been included as a package source in the product, used to resolve package URLs at runtime.
This use of the design was rejected because such products don't currently exist, and the current mechanisms for software delivery both on device and in the TUF infrastructure, although designed for such use, have never been proven to be usable in production in this way, and are expected to evolve further before this would be feasible. So there was a strong desire to create no lock-in to the current state of software delivery. Likewise, the TUF infrastructure was not believed to handle a large number of TUF repositories well.
All artifacts listed in targets.json of the TUF repository
Originally it was envisoned that all artifacts (and especially all Fuchsia
packages) would be listed in the targets.json file of the TUF repository, and
the directories that group artifacts in one release were actual directories
containing TUF repository targets. That information was duplicative with the
information already recorded in artifact_groups.json and served no purpose, so
it was dropped for clarity, as well as to evade a size limit imposed on
targets.json that is not imposed on files merely listed in targets.json.
Unknowns
There are currently unanswered questions about possible extensions of the application of the presented design.
- Can this mechanism also be applied to the Fuchsia SDK? The Fuchsia SDK is a
prerequisite artifact for the creation of petal components as well as out of
tree products in the same way as prebuilt artifacts are prerequisite for
creation of products, and it needs to be selected very similarly according to
variant and version based on attributes that describe both. So the question
poses itself whether petal build processes should declare their use of the SDK
in an
artifact_spec.jsonfile, and whether the product build process should include the Fuchsia SDK in itsartifact_spec.jsonfile. - Can this mechanism also be applied to petal SDKs, i.e. the SDKs that one petal provides to other petals, such as the Flutter SDK? This is not required to enable decentralized product integration, but could simplify the resulting distributed build process. For example, by checking the fetched Flutter SDK version in the lock file of a petal repository, the upload tool can figure out the correct Flutter SDK version attribute values of the uploaded artifacts.
- Can this mechanism also be used to publish built products? In the workstation implementation, fuchsia workstation product could be released to an artifact store. This uploaded product could later be used for differential assembly.
- Can the description mechanism be used to transitively establish binary transparency for all binary artifacts involved in the creation of a product, going back to the prebuilt artifacts included in the product, the prebuilt artifacts of the tools used to assemble the product, the tools to create the prebuilt artifacts, etc. recursively.
Documentation
This document serves as the initial documentation. There will be tools, and they will have help pages. The workstation repository setup will serve as blueprint and demonstration for subsequent use.
Prior art and references
Product integration for other operating systems usually happens from source trees with less extensive use of prebuilts, and thus fewer requirements to concurrently propagate multiple variants and versions of such prebuilts between repositories.
Build systems "select" the compatible "version" of a dependency by just rebuilding it at the current version, in the variant determined by the currently applied build parameters. The design presented here can be understood as the generalization of a build system to operate asynchronously and distributed.
Related documents
- Decentralized Product Integration Fuchsia Roadmap entry.
- Platform Versioning RFC
- Standalone Image Assembly Tool RFC
- Workstation Out Of Tree RFC
- Out-Of-Tree Bazel SDK RFC Draft
- Decentralized Product Integration, Artifacts Selection Specification RFC Draft
- Product Assembly From Subassemblies RFC Draft
Appendix
Figure 4 - Legend of Global Integration Figure