
| RFC-0196: FIDL large messages | |
|---|---|
| Status | Accepted |
| Areas |
|
| Description | Support for sending large messages over FIDL protocols. |
| Issues | |
| Gerrit change | |
| Authors | |
| Reviewers | |
| Date submitted (year-month-day) | 2022-06-28 |
| Date reviewed (year-month-day) | 2022-10-27 |
Summary
Currently, the FIDL language limits the size of messages over zircon-based
transports like channels and sockets to 64KiB. This document proposes a
high-level design for handling arbitrarily large messages, even if they overflow
the maximum message byte limit their underlying transport. This is achieved by
elevating a solution similar to a well-worn existing pattern,
the use of fuchsia.mem.Data, to first-class, automatically deduced FIDL
language support.
Motivation
All FIDL messages sent over the wire are today limited to a size of
ZX_CHANNEL_MAX_MSG_BYTES, currently equivalent to 64KiB and derived from the
maximum size of messages that may be sent over a zircon channel. Messages that
exceed this limit fail to encode.
The common solution to this problem today is to send arbitrarily large data as a
blob over zx.handle:VMO, or alternatively fuchsia.mem.Data, with the
underlying VMO itself containing the data blob being sent. Often, these blobs
contain structured data that end users would like to represent in and
encode/decode as FIDL, but cannot and are forced into manual casting themselves.
There are a large number of uses of these wrapper types in fuchsia.git today.
There are a few issues caused by the lack of large message support. The foremost
among these is the large number of bugs caused by protocols that rarely need to
send large messages, but are technically capable of doing so. Examples include
very large URLs, or very large lists of networks produced during WiFi scans.
Every API that needs to take a :MAX sized vector or string is vulnerable
to this problem, among other edge cases, like table layouts that only very
rarely have all their fields populated. In the general case, anything that needs
to accept user data in the form of messages that are not provably under 64KiB
may be affected by this failure mode.
Sending untyped blobs of data over a VMO is unergonomic because it loses all
type information, which must be manually reconstructed at the receiving end.
Instead of leveraging FIDL to describe the shape of the data and abstract away
the encode->send->decode->dispatch pipeline, users are forced to encode the
message themselves, package it into another FIDL message, and then repeat this
process in reverse on the opposite end. For instance, the ProviderInfo
API has child types InspectConfig and InspectSource
which are today represented by fuchsia.mem.Buffer and zx.handle:VMO,
respectively, but represent structured data that could be described and handled
by FIDL.
The use of zx.handle:VMO or fuchsia.mem.Data creates a situation where a
data-only FIDL type is forced to carry the resource modifier. This has
downstream effects on binding APIs, causing generated types in languages like
Rust to be unable to derive the Clone trait even when they reasonably should.
The bugs and ergonomics problems caused by inadequate large message support are pervasive. A survey undertaken during the drafting of this RFC revealed at least thirty cases past and present where more robust large message support would have helped FIDL users.
Stakeholders
Facilitator: hjfreyer@google.com
Reviewers: abarth@google.com, chcl@google.com, cpu@google.com, mseaborn@google.com, nickcano@google.com, surajmalhotra@google.com
Consulted: bprosnitz@google.com, geb@google.com, hjfreyer@google.com, jmatt@google.com, tombergan@google.com, yifeit@google.com
Socialization: Five teams (Component resolver, DNS resolver, driver development, WLAN SME, and WLAN policy) have reviewed prototypes using this design:
- Component resolver: geb@google.com
- DNS resolver: dhobsd@google.com
- Driver development: dgilhooley@google.com
- WLAN policy: nmccracken@google.com
- WLAN SME: chcl@google.com
Additionally, over thirty users of the existing fuchsia.mem.Data and
fuchsia.mem.Buffer types have been interviewed for design feedback and use
case suitability.
Design
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in IETF RFC 2119.
Message overflow is a transport-level concern. What constitutes a large message, and how best to handle a message that meets that definition, varies greatly between zircon channels, the driver framework, overnet, and so on. This means that calling a particular method request or response "large" is not an abstract statement: there MUST always be a well-defined definition of "large" for that method's owning protocol.
The following specifies how a message can declare, "I am large relative to the
expectations of the transport carrying me, and therefore require special
handling". This declaration MUST be legible both at interface definition
time in the *.fidl file specifying the protocol and at runtime for any given
message instance that actually overflows.
Concretely: before this design, a sender could send an otherwise perfectly valid
message that exceeded the underlying transport's maximum message byte limit,
thereby causing a surprising and difficult-to-debug PEER_CLOSED runtime
failure. After these changes, the fidlc compiler will statically check to see
if the payload type could possibly be greater than the transport's maximum
message byte limit and, if so, will generate special "overflowing" handling code
to account for this. This mode enables a secondary runtime message delivery
mechanism for large messages, whereby unbounded side channels (in the case of
zircon channels, a VMO) are used to store the contents of the message. This new
message delivery path is added entirely in the "guts" of the generated binding
code, thereby maintaining both API and ABI compatibility. FIDL method
implementors can now be confident that no allocatable message will trigger
PEER_CLOSED due to hitting arbitrary byte size limitations.
Wire format changes
A new bit, known as the byte_overflow flag, is added to the dynamic
flags portion of the FIDL transactional message
header. This flag, when flipped, indicates that the currently
held message contains only the control plane of the message, and that the
remainder of the message is stored in a separate possibly non-contiguous buffer.
The location of this separate buffer, and how the buffer may be accessed, is
transport dependent. If the byte_overflow flag is active, the in-transport
control plane message MUST contain the 16 byte transactional message header
followed by an additional 16 byte addendum message describing the size of the
large message. That means that this message MUST be exactly 32 bytes: the
default FIDL message header followed by a so-called message_info struct
containing three pieces of data: a uint32 for flags, a uint32 reserved for
potentially specifying the number of handles attached to the message when
excluding the overflow buffer, and a uint64 indicating the size of the data in
the VMO itself:
type MessageInfo = struct {
// Flags pertaining to large message transport and decoding, to be used for
// the future evolution and migration of this feature.
// As of this RFC, this field must be zeroed out.
flags uint32;
// A reserved field, to be potentially used for storing the handle count in
// the future.
// As of this RFC, this field must be zeroed out.
reserved uint32;
// The size of the encoded FIDL message in the VMO.
// Must be a multiple of FIDL alignment.
msg_byte_count uint64;
};
Because an extra handle needs to be generated to point to the overflow buffer, a large FIDL message may only have 63 handles attached, rather than the usual 64. This behavior is inelegant and surprising to users, and will only be reported via a runtime error. This unfortunate corner case is offset by the commitment to develop kernel improvements to fix the sharp edge in the future.
The byte_overflow flag MUST occupy bit #6 (ie, the penultimate most
significant bit) in the dynamic flags bit array. Bit #5 is reserved for a
potential future handle_overflow bit, though this bit is currently unused.
This bit MUST NOT be used for another purpose.
Runtime requirements
There are a number of conditions that, when violated during decoding, MUST
result in a FIDL transport error, and an immediate closure of the communication
channel. If the byte_overflow flag is set, the size of the control plane
message MUST be exactly 32 bytes, as described above - the body of the
message MUST be transported over some other medium.
In the case of the zircon channel transport, the medium for the byte overflow
buffer MUST be a VMO. This means that the number of accompanying handles on
the control plane message MUST be at least one. The kernel object pointed to
by that last handle MUST be a VMO, and the amount of bytes read out from
that VMO by the receiver MUST be equal to the value of the msg_byte_count
field of the message_info struct. If the message is known to be bounded,
this value MUST be less than or equal to the statically-deduced maximum size
for the payload in question.
Message senders MUST mint a new VMO via the zx_vmo_create syscall,
followed immediately by a zx_vmo_write to populate it with the body of the
message. They MUST ensure that the handle representing the overflow VMO does
not have the right ZX_RIGHT_WRITE.
On the receiving side, recipients of the message MUST read out the data it
holds using zx_vmo_read. Thus, while a regular FIDL message sent over a zircon
channel only needs two syscalls (zx_channel_write_etc for the sender and
zx_channel_read_etc for the receiver), a byte overflowing message needs
several more (zx_channel_write_etc, zx_vmo_create, and zx_vmo_write for
the sender, and zx_channel_read_etc, zx_vmo_read, and zx_handle_close for
the receiver). This is a steep penalty, though future optimizations, like
improvements to the zx_channel_write_etc API, will likely claw back some of
these costs. Message receivers MUST NOT attempt to write to the received
overflow VMO.
Code generation changes
FIDL binding implementations MUST generate overflow handlers for any payload message whose maximum byte count could possibly be larger than its protocol transport's limit. For this purpose, FIDL messages may be broadly split into three categories:
- Bounded: Messages whose maximum cumulative byte counts are always known.
This category includes most FIDL messages. For such messages, bindings
generators MUST use the calculated maximum byte count of the message to
determine whether or not include the ability to set the
byte_overflowflag at encode time, and whether or not to check it at decode time. Specifically, if the maximum cumulative byte count is greater than that allowed by the protocol transport's limit (64KiB in the case of zircon channels), the ability to set thebyte_overflowflag at encode-time and mandatory decode-time flag checking MUST be included in the generated code; otherwise, they MUST NOT be. - Semi-bounded: Messages whose maximum cumulative byte counts are only
known at encode time. This category includes any message that would otherwise
be bounded, but transitively includes a
flexible unionortabledefinition. For such messages, bindings generators MUST use the calculated maximum byte count of the message to determine whether or not to include the ability to set thebyte_overflowflag at encode time, but this flag MUST always be checked at decode time. - Unbounded: Messages whose maximum cumulative byte counts are by
definition always unknowable. This category includes any message that
transitively include a recursive definition or an unbounded
vector. For such messages, generated bindings code MUST always include the ability to set thebyte_overflowflag on encode and, and MUST always check it on decode.
@transport("Channel")
protocol Foo {
// This request has a well-known maximum size at both encode and decode time
// that is not larger than 64KiB limit for its containing transport. The
// generated code MUST NOT have the ability to set the `byte_overflow` on
// encode, and MUST NOT check it on decode.
BoundedStandard() -> (struct {
v vector<string:256>:16; // Max msg size = 16+(256*16) = 4112 bytes
});
BoundedStandardWithError() -> (struct {
v vector<string:256>:16; // Max msg size = 16+16+(256*16) = 4128 bytes
}) error uint32;
// This request has a well-known maximum size at both encode and decode time
// that is greater than the 64KiB limit for its containing transport. The
// generated code MUST have the ability to set the `byte_overflow` on encode,
// and MUST check it on decode.
BoundedLarge() -> (struct {
v vector<string:256>:256; // Max msg size = 16+(256*256) = 65552 bytes
});
BoundedLargeWithError() -> (struct {
v vector<string:256>:256; // Max msg size = 16+16+(256*256) = 65568 bytes
}) error uint32;
// This response's maximum size is only statically knowable at encode time -
// during decode, it may contain arbitrarily large unknown data. Because it
// is not larger than 64KiB at encode time, the generated code MUST NOT have
// the ability to set the `byte_overflow` on encode, but MUST check for it on
// decode.
SemiBoundedStandard(struct {}) -> (table {
v vector<string:256>:16; // Max encode size = 32+(256*16) = 4128 bytes
});
SemiBoundedStandardWithError() -> (table {
v vector<string:256>:16; // Max encode size = 16+32+(256*16) = 4144 bytes
}) error uint32;
// This response's maximum size is only statically knowable at encode time -
// during decode, it may contain arbitrarily large unknown data. Because it
// is larger than 64KiB at encode time, the generated code MUST have the
// ability to set the `byte_overflow` on encode, and MUST check for it on
// decode.
SemiBoundedLarge(struct {}) -> (table {
v vector<string:256>:256; // Max encode size = 32+(256*256) = 65568 bytes
});
SemiBoundedLargeWithError(struct {}) -> (table {
v vector<string:256>:256; // Max encode size = 16+32+(256*256) = 65584 bytes
}) error uint32;
// This event's maximum size is unbounded. Therefore, the generated code MUST
// have the ability to set the `byte_overflow` on encode, and MUST check for
// it on decode.
-> Unbounded (struct {
v vector<string:256>;
});
};
ABI and API compatibility
This design, once fully rolled out, is completely ABI and API compatible. It is
always ABI-safe because any change that converts previously bounded payload to
an unbounded or semi-bounded one, like changing a struct to a table, or
altering vector size bounds, is already an ABI-breaking change.
For unbounded or semi-bounded payloads, the byte_overflow flags are always
checked during message decode regardless of size. This means that any message
that may be encoded at one end of a connection may be decoded at the other, even
if an evolution has added unknown data that causes the message to be, from the
decoder's view of the payload type, unexpectedly large.
In the intermediate period during the rollout, where it is likely that one party to a connection has a FIDL binding that knows about large messages while the other does not, large messages will fail to decode. This is similar to the situation today, where such messages would fail during encode, though the failure will now be slightly further away from the source.
The risk from decode failures during the intermediate rollout period is deemed to be low, as most APIs that would send large messages already have protocol level mitigations, like chunking, in place. The major risk vector is if protocols start sending now-allowed large messages over existing methods. Such protocols SHOULD instead prefer to introduce new, large-message-capable methods instead.
Design principles
This design upholds several key principles.
Pay for what you use
A major design principle of the FIDL language is that you only pay for what you use. The large message feature described in this document strives to uphold this ideal.
Methods that use bounded payloads are rendered no less performant for this RFC having existed. Methods that use semi-bounded or unbounded payloads, but do not send messages larger than the protocol transport's bye count limit, only pay the cost of a single bit flag check on the receiving end. Only messages that actually use the large message overflow buffer will see their performance impacted.
Users that do not need large message support (that is, most methods/protocols that are likely to be expressed in FIDL) do not need to pay anything, both in terms of runtime performance costs and of mental overhead incurred when writing FIDL APIs.
No migration
Large messages are now enabled everywhere for any payload that could plausibly
use them, with no migration of existing FIDL APIs or their client/server
implementations. Cases that would have previously caused a PEER_CLOSED runtime
error now "just work".
Transport tailored
This design is flexible to the needs of different transports, both existing and
speculative. For example, conventions such as multi-packet messages over a
network are possible as long as the byte_overflow bit is flipped and the
transport knows how to order the overflow containing packets.
Implementation
This feature will be rolled out behind an experimental fidlc flag. Each
binding backend will then be modified to handle large messages as specified by
this RFC for inputs that specifically specify the experimental flag. Once the
feature is considered stable, the flag will be removed, allowing for general
use.
This attribute should not require additional fidlc support, as it will merely
pass the information necessary to perform overflowing checks through to the
selection of backends that will be taught how to support large messages.
Prior to this RFC, bindings universally place encode/decode buffers onto the
stack. Going forward, the recommendation is that bindings SHOULD continue
this behavior for messages that do not have the byte_overflow flag flipped.
For messages that do, bindings SHOULD allocate on the heap instead.
Performance
The performance impact of the proposed delivery method can be estimated using the kernel microbenchmarks in a slightly customized scenario, summing and comparing two cases: sending a single channel message of size B versus the sum of sending a 16 byte channel message and sending a VMO of size B - 16, for the following values of B: 16KiB, 32KiB, 64KiB, 128KiB, 256KiB, 512KiB, 1024KiB, 2048KiB, and 4096KiB.
Listing 1: Table showing the estimated1 delivery time performance "tax" paid when sending B bytes of data as a 16 byte channel message and a VMO of size B - 16 rather than as a channel message of size B.
| Message Size / Strategy | Channel Only | Channel + VMO | VMO Usage Tax |
|---|---|---|---|
| 16KiB | 2.5μs | 5.9μs | 136% |
| 32KiB | 4.5μs | 7.7μs | 71% |
| 64KiB | 7.9μs | 13μs | 65% |
| 128KiB | 16.5μs | 23.3μs | 41% |
| 256KiB | 35.8μs | 54.4μs | 52% |
| 512KiB | 71.3μs | 107.4μs | 51% |
| 1024KiB | 157.0μs | 223.4μs | 42% |
| 2048KiB | 536.2μs | 631.8μs | 18% |
| 4096KiB | 1328.2μs | 1461.8μs | 10% |
Listing 2: Graph showing the estimated delivery time performance "tax" paid when delivering B bytes of data as a 16 byte channel message and a VMO of size B - 16 rather than as a channel message of size B.
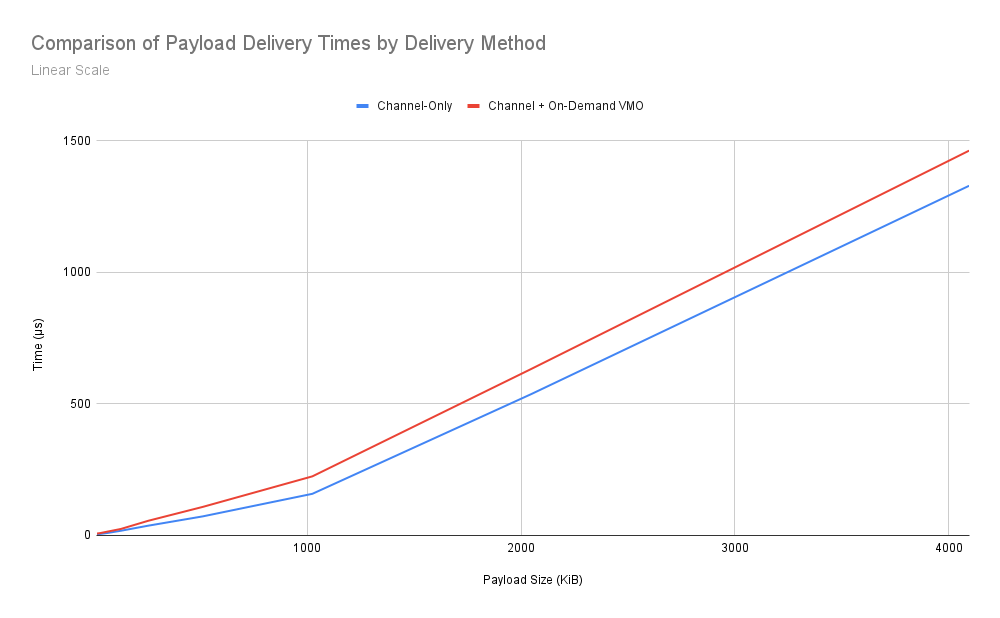
Listing 3: Linear scale comparison of delivery time performance between delivering B bytes of data as a 16 byte channel message and a VMO of size B - 16 rather than as a channel message of size B.
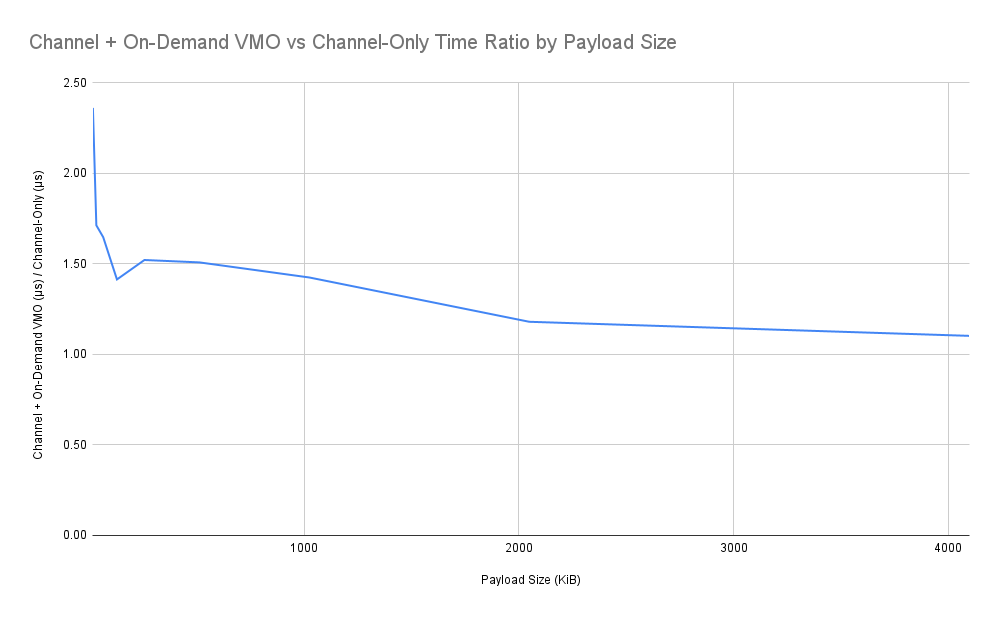
This data yields a few interesting observations. We can see that the relationship between data size and time to deliver is roughly linear. There is clearly a gap in performance between the two methods, though interestingly the gap seems to narrow as message size grows.
Combining these results, we can model the expected performance of sending FIDL large messages using the method specified in this design. We can expect that the the so-called "VMO tax" at a given size over using a plain old channel message of the same size (were it allowed) to be roughly a 20-60% increase in end-to-end delivery time. Interestingly, the percent-wise gap marginally decreases as the size of the message being sent increases, indicating that the VMO tax grows slightly sub-linearly with respect to payload size.
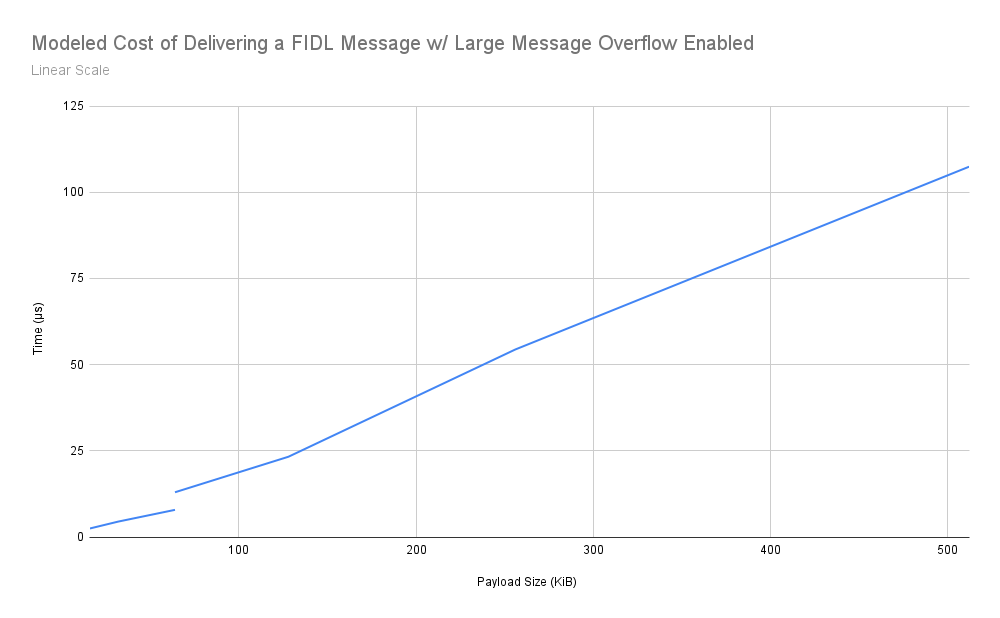
Listing 4: Table showing the modeled delivery time performance of the design described in this document.
| Message Size / Strategy | Channel Only | Message + VMO |
|---|---|---|
| 16KiB | 2.5μs | -- |
| 32KiB | 4.5μs | -- |
| 64KiB | 7.9μs | 13μs |
| 128KiB | -- | 23.3μs |
| 256KiB | -- | 54.4μs |
| 512KiB | -- | 107.4μs |
| 11024KiB | -- | 223.4μs |
| 2048KiB | -- | 631.8μs |
| 4096KiB | -- | 1461.8μs |
Listing 5: Linear scale graphs showing the modeled delivery time performance of the design described in this document. Note the discontinuity at the 64KiB switch from regular to large messages.
Ergonomics
This change constitutes a major improvement to ergonomics, as basically all
current use cases of zx.handle:VMO, fuchsia.mem.Buffer and
fuchsia.mem.Data can now be described using first-class FIDL concepts instead.
Downstream binding code benefits as well, as data that would previously have to
be sent over the wire untyped can be handled using the usual FIDL pathways. In
essence, the generated FIDL APIs for large messages are now identical to their
non-large message counterparts.
Backwards compatibility
These changes will be fully backwards compatible. Existing APIs have their semantics changed slightly (from being bounded at 64KiB per message, to unbounded), but since this is a loosening of the previous restriction, no existing APIs are affected.
Security considerations
These changes will have minimal impact on security. The pattern being elevated
to "first-class" status is already possible using the fuchsia.mem.Data
structure, with no observed negative effect on security. It is still important,
however, to ensure that its implementation is secure in all cases.
This design also expands the denial of service risks
associated with FIDL protocols. Before, the attack vector of sending a VMO that
allocates so much memory it crashes the receiver was only available to protocols
that explicitly sent fuchsia.mem.Data/fuchsia.mem.Buffer/zx.handle:VMO
containing types. Now, all protocols that contain at least one method with an
unbounded or semi-bounded payload are exposed to this risk. This is considered
tolerable for now simply because of the many denial of service vectors present
in zircon. A more holistic solution resolving this problem will pursued outside
of the confines of this design.
This design introduces an additional denial of service vector by not mandating
that ZX_INFO_VMO be checked on the receive side. This allows a pager-backed
VMO to cause the server to hang by never furnishing the pages it has promised to
provide. The risk of this happening by accident is judged to be low in practice,
since only a relatively small number of programs use the pager-backed VMO
mechanism. Similar to the reasoning above, this denial of service vector is
tolerated until a more holistic solution can be implemented in a future design.
Privacy considerations
An important privacy consideration is that message senders MUST ensure that they use a freshly-created VMO for each VMO-based message. They MUST NOT reuse VMOs between messages, otherwise they risk leaking data. Bindings are required to enforce these constraints.
Testing
The standard FIDL testing strategies of unit tests for fidlc and goldens for
downstream and binding outputs will be extended to accommodate large message use
cases.
Documentation
The FIDL wire format specification will need to be updated to describe the wire format changes introduced by this document.
Drawbacks, alternatives, and unknowns
Drawbacks
There are a number of disadvantages to this design. While these are judged to be minor, especially relative to the cost of doing nothing or of implementing the considered alternatives, they are still worth pointing out.
Performance cliff
As elaborated in the performance exploration, the strategy
described in this RFC results in a performance "cliff" at the
ZX_CHANNEL_MAX_MSG_BYTES cutoff point where the user starts paying a "tax" to
send messages of larger sizes. Specifically, a message one byte larger than
64KiB will take roughly 60% longer (13μs instead of 7.9μs) to be received than a
message that is exactly 64KiB. While such a cliff is unideal, it is relatively
small, and possible to ameliorate via future kernel changes.
Denial of service
Any protocol that has at least one method that takes an unbounded or
semi-bounded payload is now susceptible to denial of service with regards to
memory: a malicious attacker can send an overflowing message with a very large
value in the msg_byte_count field of the message_info struct, with a
similarly large VMO attached. The receiver would then be forced to allocate a
sufficient amount of memory deal with this payload, inevitably crashing if the
malicious payload is large enough.
As discussed in the security considerations enumerated above, this is a very real risk, one that this design punts on solving until a more holistic solution can be found at a future date.
Handle overflow edge cases
This design does not entirely eliminate the possibility of experiencing a
surprising PEER_CLOSED at runtime due to a message being unexpectedly large: a
regular message with more than 64 handles, or a large one with more than 63,
will still trigger the error state. This is considered acceptable for now, as
the author is aware of no such payloads being used in practice. This edge case
can be dealt with as the need arises. The inclusion of the reserved field on
the message_info struct ensures that there will be flexibility in the future
design of handle overflow support.
Context dependent message properties
The byte_overflow and flag will be the first header flags that mean different
things to different transports (with the arguable exception of the at-rest
flags, depending on whether we consider at-rest FIDL a "transport"
or not). This introduces some ambiguity: merely looking at a wire-encoded FIDL
transactional message without knowing which transport sent it may no longer be
fully sufficient to process the message. There is now a "pre-processing" step
needed where, depending on both the header flags and the transport the message
was sent over, we do a special procedure to assemble the full message content.
For instance, a non-handle carrying message that overflows on a zircon channel
transport will now get a handle in its handles array, while an fdf message
that overflows may not.
Rejected alternatives
A large number of alternative solutions were considered during the design of this RFC. The most interesting proposals are listed below.
Raise the zircon message size limit
The most pressing need for large messages is over the zx.channel transport,
which currently has message size limit of 64KiB. One obvious solution here is to
just increase this limit.
This is undesirable for a few reasons. The first is that it simply punts the problem down the road. This is complicated by the fact that ABI-breaking kernel limit migrations such as this are not trivial, as careful management is required to ensure that binaries compiled after the limit is raised do not accidentally send more data than binaries compiled before the increase can handle.
Many FIDL implementations also make useful assumptions based around the limit.
Some bindings, such as those for Rust, employ a "guess and check" allocation
strategy for received messages. They allocate a small buffer and try
zx_channel_read_etc. If that syscall fails with ZX_ERR_BUFFER_TOO_SMALL, it
returns the actual message size. This allows the binding to allocate an
appropriately large buffer and retry.
Other bindings, like those for C++, just throw caution to the wind and always allocate 64KiB for incoming messages, avoiding the possibility of multiple syscalls at the cost of larger allocations. The latter strategy does not scale to arbitrarily large messages.
Finally, using VMOs is a well-tested solution: it has already been the go to
option for large message transport for years via the fuchsia.mem.Data and
fuchsia.mem.Buffer types. Raising the kernel limit is less proven solution
with more potential unknowns.
Use zx_vmar_map instead of zx_vmo_read
An optimization to the current design would have the FIDL encoder read directly
from the VMO buffer using zx_vmar_map. There are two problems to this
approach.
The main issue is simply that this method is insecure, a problem which would
require modifications to kernel primitives to remedy. The issue here is that
mapping memory creates a situation where the message sender may modify message
contents while the receiver is reading it, creating TOCTTOU
risks. The reader could try to read the data directly from the mapped and
potentially mutable VMO without copying first, but even if a defensive copy were
performed, it is difficult to do this safely. These security
risks could be mitigated by the received by enforcing the VMO's immutability via
a zx_vmo_create_child call, at the cost of additional syscall and worst-case
copying overhead.
Additional issues around the performance of memory mapping, as well as complications for the wire C++ bindings, like deciding when the memory could be released, make this option a poor fit.
Packetization
The idea here is to take very large messages and split them over many messages, each chunk being no larger than 64KiB, and then assemble them on the other end. The transactional message header would have some sort of continuation flag indicating whether it expects "more data" to follow or not. This has the advantage of built-in flow control, and of familiarity to programmers coming from languages with streaming primitives in their standard libraries.
The downside of this approach is that it does not obviously help in cases where messages are not easily chunkable. It is also much more complex: when multiple threads are sending, a bewildering array of partial message chunks will clog up the transport needing to be re-assembled on the other end.
Most worryingly, this strategy presents a denial of service risk, one that could not later be fixed via new kernel primitives alone or the future addition of bounded protocols: a malicious or buggy client could send a very long stream of message packets, but then fail to send the "closing" packet. The receiver is compelled to hold all of the remaining packets in memory while it waits for the last packet, allowing the client to "book" a potentially unlimited persistent memory allocation on the server. There are ways around this of course, like timeouts and policy limits, but this quickly devolves into re-implementing TCP over FIDL.
Explicit overflow
The design proposed in this document abstracts away the details of how large messages are deliver from end users. Users simply define their payloads, and the bindings do the rest behind the scenes.
An alternative design could allow users to declaratively specify when a VMO is
specifically used, either at a per-payload or per-payload-member level. In
essence, this would just entail modifying the FIDL language to provide a cleaner
spelling for fuchsia.mem.Data.
The existing design takes the tradeoff of improved performance and API compatibility for less determinism and granular control, which is deemed to be a worthwhile exchange.
Only allow value types
An early version of this design proposed only enabling overflowing for value
types. The reasoning here was simple: none of the existing use cases
were resource types, and it is quite unlikely that a single FIDL message would
need to send more than 64 handles at once, so this was judged to be a low
priority.
In the process of prototyping this solution for the
fuchsia.component.resolution library, a wrinkle
was discovered. Certain methods already use tables to carry their payloads, and
rather than replacing the method wholesale, would prefer to extend the table to
gradually deprecate the use of fuchsia.mem.Data. Concretely:
// Instead of adding a new method to support large messages, the preferred
// solution is to extend the existing table and keep the current method.
protocol Resolver {
Resolve(struct {
component_url string:MAX_COMPONENT_URL_LENGTH;
}) -> (resource struct {
component Component;
}) error ResolverError;
};
type Component = resource table {
// Existing fields - note the two uses of `fuchsia.mem.Data`.
1: url string:MAX_COMPONENT_URL_LENGTH;
2: decl fuchsia.mem.Data;
3: package Package;
4: config_values fuchsia.mem.Data;
5: resolution_context Context;
// Proposed additions for large message support.
6: decl_new fuchsia.component.decl.Component;
7: config_values_new fuchsia.component.config.ValuesData;
};
These methods present an interesting problem: even though the case where the payload is large and the case where it carries handles are in practice mutually exclusive, this is not known to the fidlc compiler. From its perspective, these are just resource types. While certain kludges could be imagined for teaching compiler about this specific case, it was judged simpler to just allow 63 handles on large messages until a more suitable kernel primitive can be developed.
The overflowing modifier
An early iteration of this design allowed users to set overflowing buckets in
the FIDL defining their protocol methods, like so:
// Enumerates buckets for maximum zx.channel message sizes, in bytes.
type msg_size = flexible enum : uint64 {
@default
KB64 = 65536; // 2^16
KB256 = 262144; // 2^18
MB1 = 1048576; // 2^20
MB4 = 4194304; // 2^22
MB16 = 16777216; // 2^24
};
@transport("Channel")
protocol Foo {
// Requests up to 1MiB are allowed, responses must still be less than or equal
// to 64KiB.
Bar overflowing (BarRequest):zx.msg_size.MB1
-> (BarResponse) error uint32;
};
This was ultimately deemed too complex and subtle, as it allowed several options with no obvious guidance on which to pick. Ultimately, most users will likely want to answer a simple yes/no question ("Will I need large message support?"), rather than worrying about the minute performance implications of specific limits.
An alternative was also considering with a lone overflowing keyword, with no
buckets, to make clear to users to they were accepting a potentially less
performant API. The performance gap was ultimately decided to not be large
enough, and in any case shrinkable enough, to not warrant such a callout in the
language itself.
Potential future work
There are a number of companion efforts which, while not strictly required to enable large message functionality, are important complements and optimizations to this effort.
Kernel changes
There are number of possible kernel changes that, while not on the critical path
to implementing this feature, will no doubt help reduce syscall thrashing and
optimize performance. The user-facing API of large messages is such that it
SHOULD NOT change when these additional optimizations are implemented. Most
existing users of fuchsia.mem.Data are not particularly latency sensitive
(otherwise they wouldn't be using fuchsia.mem.Data!), so the main utility of
modifying the kernel is in improving performance for emergent use cases that pop
up once large messages are enabled in FIDL.
First-class streams
Whenever a large message use case arises, the question inevitably gets asked, "could this not be resolved by implementing first-class streams in FIDL?" To answer this for any specific case, there are two useful properties on which a large amount of data can be classified that should be considered: chunkability and appendability.
Chunkability refers to whether or not the data in question can be split into
useful sub-parts, and, more importantly, if the receiver of the data can do
useful work on only a subset. In essence, it is the difference between data of
type T on the one hand, and data of type vector<T> or array<T>, where a
partial view of the list is still actionable, on the other. A paginated list is
chunkable, while a list of items being sent for sorting is not. Similarly, a
tree is not chunkable, either: there's generally not much one can do with an
(arbitrary) portion of a tree.
Appendability concerns whether or not the data may be modified after it is sent. The classic example of an appendable API is a Unix pipe: while data is being read from the reading end, it is possible, even expected, that more will be added from the writing end. Data which may be added to after it is sent is appendable. Data which is immutable at send time, even when in list form, is not.
Listing 6: A matrix of the preferred large data handling strategies for all possible combinations of chunkability and appendability.
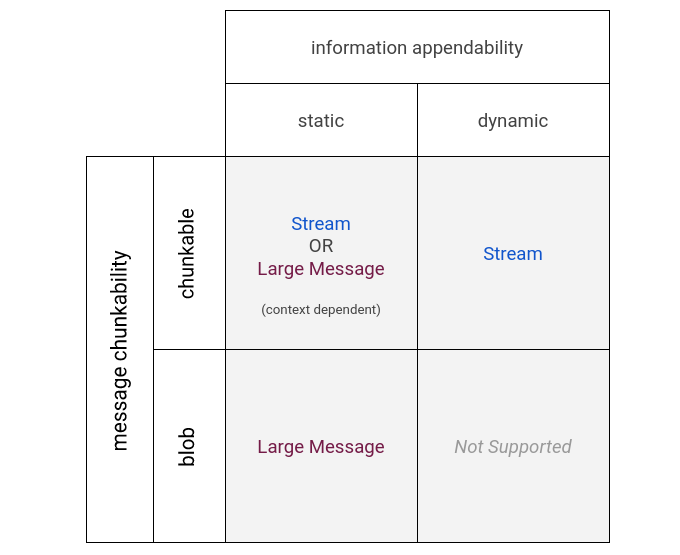
These two distinctions are useful, because combining them in a matrix provides good guidance on which of large messages or streams are more appropriate.
For a static blob, like a data dump, B-tree, or large JSON string, users don't want to stream: to them it's a single message, and the fact that it is (or at least may be) too large for FIDL is a bit of accidental complexity usually quite far from their concerns. In this case, they want a way to tell the system "do whatever it takes to get all but the most unreasonable size of this message across the wire". Once the data has been materialized to memory somewhere on the device, it does not make much sense to move it between processes piecemeal.
For a chunkable and dynamic data structure, like a stream of network packets, streams are the obvious choice (it's right in the name!). Users already make custom iterators to handle this case, writing libraries that handle setting up the stream on the sending side and cleanly exposing it on the receiving side, so it seems like a good candidate for first-class treatment. It's also a very natural pattern that has robust support and programmer familiarity in most of the languages FIDL has bindings in (C++, Dart, Rust).
What about messages that are chunkable but mostly static, like a snapshot listing the peripherals connected to the device? It would be pretty easy to chunk these and expose them as a stream, but it's not obvious that this is beneficial: there are several cases of APIs that expose this kind of information where the authors view pagination as a kludge they've included to please FIDL, not as a core feature. In this case it seems very context dependent whether a stream or large message is the better choice.
All this to say: large messages are just one instrument in the toolbox of potential methods for getting large amounts of data over the wire. FIDL very likely has a first-class streaming implementation in its future, one which will complement, rather than supersede, the capabilities offered by large messages.
Bounded protocols and flexible envelope size limits
This design has a very real denial of service risk that
some protocols, particularly those shared among many otherwise separate clients,
may wish to avoid. To this end, one may imagine adding a bounded modifier to
protocols, providing compile-time enforcement that all of their methods use only
bounded types:
// Please note that this syntax is very speculative!
bounded protocol SafeFromMemoryDoS {
// The payload is bounded, so this method compiles.
MySafeMethod(resource struct {
a bool;
b uint64;
c array<float32, 4>;
d string:32;
e vector<zx.handle, 64>;
});
};
One consequence of this design is that FIDL protocol authors are faced with a
"bifurcating" choice: adding bounded renders a protocol safe from possible
denial of service due to unboundedly large messages, but prevents that method's
payloads from transitively using table or flexible union types. This is an
unfortunate trade off, as evolvability and ABI compatibility are central aims of
the FIDL language. By forcing users into ABI stable types, we greatly restrict
their ability to evolve the payload in the future.
One possible compromise is to introduce explicit size limits for flexible
enveloped layouts. This provides ABI compatibility as the flexible definition is
altered over time, but still enforces a hard, ABI-breaking limit on the type's
maximum size:
// Please note that this syntax is very speculative!
@available(added=1)
type SizeLimitedTable = resource table {
1: orig vector<zx.handle>:100;
// Version 2 still compiles, as it contains <=4096 bytes AND <=1024 handles.
@available(added=2)
2: still_ok string:3000;
// Version 3 fails to compile, as its maximum size is greater than 4096 bytes.
@available(added=2)
3: causes_compile_error string:1000;
}:<4096, 1024>; // Table MUST contain <=4096 bytes AND <=1024 handles.
Size limits of this kind provide a sort of "soft" flexibility: payloads still have the ability to change over time, but there are hard (that is, ABI-breaking) limits placed on the scope of that growth when the payload is first defined.
Prior art and references
This proposal is well precedented as fuchsia.mem.Data, and before it,
fuchsia.mem.Buffer and zx.handle:VMO, are widely used and supported across
the fuchsia.git codebase. This decision is essentially a "first-class" evolution
of this well-tested pattern.
A previous abandoned RFC described somewhat similar to this one, also using VMOs as the underlying transport mechanism for large messages.
Appendix A: Boundedness of FIDL payloads in fuchsia.git
The following table shows the distribution in boundedness between overflowing
(greater than 64KiB) and standard payloads in the fuchsia.git codebase as of
early August 2022. The data was collected by building an
"everything" build of fuchsia.git. The resulting JSON IR was then analyzed via a
series of jq queries.
Listing 7: Table showing measured frequency of each kind of payload boundedness and size in the fuchsia.git repository.
| Boundedness / Message Kind | Standard | Overflowing | Total |
|---|---|---|---|
| Bounded | 3851 (76%) | 45 (%) | 3896 (77%) |
| Semi-bounded | 530 (10%) | 70 (1%) | 600 (11%) |
| Unbounded | 0 (0%) | 602 (12%) | 602 (12%) |
| Total | 4381 (86%) | 717 (14%) | 5098 (100%) |
-
It may be tempting to compare the performance of a potential packetization solution for, say, a 4MiB message by multiplying the send time for a 64KiB message by 64, but this is incorrect. Processor cache effects on the machine doing the performance comparison ensure that transfers of <=1MiB perform relatively faster than they would if used in sequence to transfer more than 1MiB; this can be seen in the "notch" at 1MiB in the graph shown in Listing 2. The only valid comparison enabled by this benchmarking method is directly between messages of the same size. ↩