
| RFC-0050: FIDL Syntax Revamp | |
|---|---|
| Status | Accepted |
| Areas |
|
| Description | We establish guiding principles for syntactic choices, and make a few syntax changes following these principles. |
| Authors | |
| Date submitted (year-month-day) | 2020-02-26 |
| Date reviewed (year-month-day) | 2019-06-04 |
Summary
We establish guiding principles for syntactic choices, and make a few syntax changes following these principles.
Changes
- Placing types in second position, e.g. in method parameter names precede their respective types, in table declarations member names precede their respective types;
- Changing types to separate layout from constraints to place layout
related type information on the left hand side of the
:separator with constraints information on the right hand side, e.g.array<T, 5>vsvector<T>:5more clearly conveys that an array's size is layout impacting, whereas it is a constraint for vectors. - Introduction of anonymous layouts. For instance
table { f1 uint8; f2 uint16; }can be used directly within a method parameter list. - Declaration of top-level types is done by using anonymous layouts with the
help of the type introduction declarations of the form
type Name = Layout;. - Lastly, for a protocol
P, renamingPandrequest<P>toclient_end:Pandserver_end:Prespectively. Note that the protocol is a constraint of the client or server end, rather than the previous position which would incorrectly indicate a layout related concern.
Relation to other RFCs
- This RFC subsumes RFC-0038: Separating Layout from Constraints and RFC-0039: Types Come Second i.e. accepting RFC-0050 means rejecting both RFC-0038 and RFC-0039 as "obsolete".
- This RFC proposes an alternative solution to RFC-0044: Extensible Method Arguments, i.e. accepting RFC-0050 means rejecting RFC-0044 as "obsolete".
This RFC was later amended by:
- RFC-0086: Updates to RFC-0050: FIDL Attributes Syntax
- RFC-0087: Updates to RFC-0050: FIDL Method Parameter Syntax
- RFC-0088: Updates to RFC-0050: FIDL Bits, Enum, and Constraints Syntax
Motivation
Introductory Examples
Algebraic Data Types
The syntax is versatile enough that representing algebraic data types (ADTs) can be done fluently, without requiring any more sugar. Consider for instance:
/// Describes simple algebraic expressions.
type Expression = flexible union {
1: value int64;
2: bin_op struct {
op flexible enum {
ADD = 1;
MUL = 2;
DIV = 3;
};
left_exp Expression;
right_exp Expression;
};
3: un_op struct {
op flexible enum {
NEG = 1;
};
exp Expression;
};
};
Pattern wise, we choose to use a union of struct: the union offers
extensibility, and it is therefore not needed (and preferable) to use a more
rigid variant. Should we need to change a variant, we can instead add a new one
wholesale, and migrate to using this new variant. (In other places where
evolvability is needed, e.g. the list of binary or unary operators, a
flexible enum is chosen.)
Supporting ADTs requires much more than ergonomic syntax to describe data types. One of the key features expected, for instance, is easy construction and destruction (e.g. via pattern matching or visitor pattern).
This RFC does not introduce new functionality to FIDL, and limitations on recursive types would prevent the example to compile today. We plan to add support for generalized recursive types, and this extension will be the object of a future RFC.
Combining non-evolvable messages with evolvable messages more easily
For instance, expressing an "extensible struct" which has both struct elements (compact, inline, fast encoding/decoding), as well as the possibility to be extended:
type Something = struct {
...
/// Provide extension point, initially empty.
extension table {};
};
As an example, the fuchsia.test.breakpoints library needs to define an
extensible event dubbed Invocation. These events all share common values, as
well as specific payload for each variant of the event. This can now be more
directly and succinctly expressed as:
type Invocation = table {
1: target_moniker string:MAX_MONIKER_LENGTH;
2: handler Handler;
3: payload InvocationPayload;
};
type InvocationPayload = union {
1: start_instance struct{};
2: routing table {
1: protocol RoutingProtocol;
2: capability_id string:MAX_CAPABILITY_ID_LENGTH;
3: source CapabilitySource;
};
};
Extensible method arguments
For instance, extensible method arguments:
protocol Peripheral {
StartAdvertising(table {
1: data AdvertisingData;
2: scan_response AdvertisingData;
3: mode_hint AdvertisingModeHint;
4: connectable bool;
5: handle server_end:AdvertisingHandle;
}) -> () error PeripheralError;
};
Using a table for arguments is not a "best practice". It may be appropriate,
but comes with its set of issues, e.g. 2N possibilities with N
fields, possibly adding a lot of complexity on recipients.
Guiding principles
FIDL is primarily concerned with defining Application Binary
Interface (ABI)
concerns, and second with Application Programming Interface (API) concerns. This
can result in a syntax that is more verbose than one may be accustomed to, or
may be expecting when comparing to other programming languages. For instance, a
unit variant of a union would be expressed as an empty struct as can be seen
in the InvocationPayload example above. We could choose to introduce syntactic
sugar to elide this type, but that would go against making ABI concerns
front-and-center.
Separating Layouts from Constraints
Align on the syntax
layout:constraint
For types, i.e. anything that controls layout is before the colon, anything that controls constraint is after the colon. The layout describes how the bytes are laid out, vs how they are interpreted. The constraint restricts what can be represented given the layout, it is a validation step done during encoding/decoding.
This syntax provides a simplified way to consider ABI implications of a change, and in particular leads to two shorthand rules:
- If two types have a different layout, it is not possible to soft transition from one to the other, and vice versa 1, i.e. changing the left hand side breaks ABI
- Constraints can evolve, and as long as writers are more constrained than readers, things are compatible, i.e. it is possible to evolve the right hand side and preserve ABI
Here are example changes following this principle:
array<T>:Nbecomesarray<T, N>handle<K>becomeshandle:Kvector<T>?becomesvector<T>:optionalStruct?becomesbox<Struct>Table?becomesTable:optionalUnion?becomesUnion:optional
Those changes are discussed in the design section of this RFC.
Binary wire format first
While many formats can represent FIDL messages, the FIDL Wire Format (or "FIDL Binary Wire Format") is the one which has preferential treatment, and is catered to first.
This means that syntax choices meant to align syntax consistency with ABI consistency should consider ABI under the binary wire format (and not, say, other formats like JSON).
As an example, names do not matter when it comes to types' ABI — names do matter for protocols and methods. While names might matter for a possible JSON format we choose to over rotate towards the binary ABI format when making syntax choices, and would not alter the syntax to advantage a textual representation if it hinders the understanding of ABI rules.
Fewest features
Wright's "form and function should be one"
makes us strive for similar looking constructs to have similar looking meaning,
and vice versa. As an example, all extensible data, which internally leverage
envelopes, are always presented with ordinal:.
layout {
ordinal: name type;
};
We strive to have the fewest features and rules, and aim to combine features to
achieve use cases. In practice, when considering new features, we should first
try to adapt or generalize other existing features rather than introduce new
features. As an example, while special syntax can be designed for extensible
method arguments (and returns) as discussed in
RFC-0044: Extensible Method Arguments
we prefer leveraging table and the normal syntax for those.
One could argue that we should even require anonymous struct layouts for
methods requests and responses rather than the current syntactic sugar for
arguments borrowed from most programming languages. However, a competing design
consideration is to help library authors in aggregate achieve consistency: in
enum layout declaration, we prefer syntactic sugar over explicitly choosing a
wrapped type, as having a sensible default provides greater consistency for enums
across FIDL libraries. This in turn provides a migration path to switch enums
down the road, e.g. should a library define a general purpose ErrorStatus
enum, it could be replaced later by another 'better' general purpose
ErrorStatusV2.
Design
Types
Types follow the general form:
Name<Param1, Param2, ...>:<Constraint1, Constraint2, ...>
Empty type parameterization must omit < and >, i.e. uint32 (notuint32<>).
A type with no constraints must omit both the : separator, and <, >, i.e.
uint32 (not uint32:<>, nor uint32:).
A type with a single constraint may omit < and >, i.e.vector<uint32>:5
and vector<uint32>:<5> are both allowed, and equivalent.
Built Ins
The following primitive types are supported:
- Boolean
bool - Signed integer
int8,int16,int32,int64 - Unsigned integer
uint8,uint16,uint32,uint64 - IEEE 754 Floating-point
float32,float64
Fixed sized repeated values:
array<T, N>
Which can be thought of as a struct with N elements of type T.
Variable sized repeated values:
vector<T>
vector<T>:N
i.e. the size N can be omitted.
Variable sized UTF-8 strings:
string
string:N
i.e. the size N can be omitted.
References to kernel objects, i.e. handles:
handle
handle:S
Where the subtype S is one of bti, buffer, channel, debuglog, event,
eventpair, exception, fifo, guest, interrupt, iommu, job, pager,
pcidevice, pmt, port, process, profile, resource, socket,
suspendtoken, thread, timer, vcpu, vmar, vmo.
Handles with rights introduced in RFC-0028: Handle Rights:
handle:<S, R>
Where the rights R are either a rights value, or a rights expression.
References to protocols objects, i.e. channel handles of targeted use:
client_end:P
server_end:P
i.e. client_end:fuchsia.media.AudioCore or server_end:fuchsia.ui.scenic.Session.
Specifically, it is not legal to reference a protocol by itself: protocol declarations do not introduce a type, only what can be thought of as a kind of client or server ends. This is discussed at greater length in the Transport generalization section.
Layouts
In addition to the built in layouts, we have five layouts which can be configured to introduce new types:
enumbitsstructtableunion
Finite layout
Both enum and bits layout are expressed in similar ways:
layout : WrappedType {
MEMBER = expression;
...;
};
Where the : WrappedType is optional[^2], and defaults to uint32 if omitted.
An example enum:
enum {
OTHER = 1;
AUDIO = 2;
VIDEO = 3;
...
};
An example bits:
bits : uint64 {
TOTAL_BYTES = 0x1;
USED_BYTES = 0x2;
TOTAL_NODES = 0x4;
...
};
Flexible layouts
Both table and union layouts are expressed in similar ways:
layout {
ordinal: member_name type;
...;
};
Here, the ordinal: can be thought of as syntactic sugar to describe an
envelope<type>.
For tables, members are often referred to as fields. For unions, members are often referred to as variants. Additionally, members may be reserved:
layout {
ordinal: reserved;
...
};
Rigid layouts
The only rigid layout struct is expressed in a way that is close to flexible
layouts, without the flexible notation:
layout {
member_name type;
...;
};
For structs, members are often referred to as fields.
Attributes
A layout may be preceded by attributes for that layout:
[MaxBytes = "64"] struct {
x uint32;
y uint32;
};
This makes it possible to unambiguously attach attributes to both the member of a layout, and the type of that member:
table {
[OnMember = "origin"]
1: origin [OnLayout] struct {
x uint32;
y uint32;
};
};
In the case of the introduction of a new type that is a layout, there are two possible placements for attributes on the newly introduced type:
- On the new type:
[Attr] type MyStruct = struct { ... }. - On the layout:
type MyStruct = [Attr] struct { ... }.
fidlc will consider these equivalent, and raise an error if attributes are
specified in both places.
Regardless of which placement is used to specify the attributes, the attributes are conceptually attached to the layout itself rather than the type stanza as a whole. An example of a practical application of this is that in any IR the preference would be to lower attributes on the type stanza down to the layout rather than hoist the attributes on the layout up to the type stanza.
Naming context and use of layouts
Layouts themselves do not carry names, in a way all layouts are "anonymous". Instead, it is a specific use of a layout which determines the name it will have in the target language.
For instance, the most common use of layouts is to introduce a new top-level type:
library fuchsia.mem;
type Buffer = struct {
vmo handle:vmo;
size uint64;
};
Here, the struct layout is used in a "new type" declaration within the top-level library.
An example use in an anonymous context was covered in the introductory notes to express extensible method arguments:
library fuchsia.bluetooth.le;
protocol Peripheral {
StartAdvertising(table {
1: data AdvertisingData;
2: scan_response AdvertisingData;
3: mode_hint AdvertisingModeHint;
4: connectable bool;
5: handle server_end:AdvertisingHandle;
}) -> () error PeripheralError;
};
Here, the table layout is used within the request of the StartAdvertising
method, in the Peripheral protocol declaration.
We refer to the list of names, from least specific to most specific, which
identifies the use of a layout as its "naming context". In the two examples
above, we have respectively fuchsia.mem/Buffer and
fuchsia.bluetooth.le/Peripheral, StartAdvertising, request as the two naming
contexts.
In the JSON IR, layout declarations will include their naming context, i.e. the hierarchical list of names described above.
Naming contexts
Within a library some.library, a type Name = declaration introduces a
naming context for some.library/Name.
A use within a request (respectively a response) of a Method within
Protocol introduces a naming context of some.library/Protocol, Method,
request/response
A use within a layout adds the field name (or variant name) to the naming context. For instance:
type Outer = struct {
inner struct {
...
};
};
The first outer struct layout's naming context is some.library/Outer, and the
second inner struct layout's naming context is some.library/Outer, inner.
Generated flattened name
Many target languages can represent naming context hierarchically. In C++ for instance, a type can be defined within an enclosing type. However, some target languages do not have this ability, and we must therefore consider name clashing caused by flattening naming contexts.
Consider for instance the naming context some.library/Protocol, Method,
request. This may be flattened to some.library/MethodRequestOfProtocool in
Go. If some other definition happens to use the naming context
some.library/MethodRequestOfProtocool then the Go bindings are faced with a
conundrum: one of the two declarations must be renamed. Worst, should a library
with one declaration (no name clash) evolve into a library with the two
declarations (with a name clash), then the Go bindings must be consistent with
what was generated before in order to avoid a source breaking change.
Our experience has shown that these decisions are best left to the core FIDL compiler, rather than delegated down the toolchain to FIDL bindings. We will therefore compute and guarantee a stable flattened name.
In the JSON IR, naming contexts will include a generated flattened name which the compiler guarantees is unique in global scope, i.e. the frontend compiler is responsible for generating flattened names, and verifying that flattened names do not clash with other declarations (be it other flattened names, or top-level declarations).
Take the example before, should a library author add a declaration type
MethodRequestOfProtocool = ... which clashes with the generated flattened name of
another declaration, compilation will fail.
Use of naming contexts by bindings
Bindings can be split in roughly two categories:
- Ability to represent naming context scoping in the target language, e.g. bindings for the C++ language;
- Inability to represent naming context and fallback to the use of the generated flattened nuse flattened name, e.g. bindings for the Go language.
That's an improvement over the situation today because we'll at least be consistent between bindings, and have compiler help on the frontend. Today, we have to generate some of the names late in the game (in the backend), which is a hazardous and error prone approach.
For instance, consider the definition:
type BinOp = union {
add struct {
left uint32;
right uint32;
};
};
In C++ bindings, we could end up:
class BinOp {
class Add {
...
};
};
The accessor to the variant add would be:
BinOp.add();
which does not clash with the class definition.
Or in Go, with the use of flattened names:
type BinOp struct { ... };
type BinOpAdd struct { ... };
Should the library author later decide to introduce a top-level declaration
named BinOpAdd, this would be caught by the frontend compiler and reported as
an error. The library author is put in control to think through the
ramifications of this change, and would have the option to decide to break
source compatibility for the introduction of this new declaration. Again, this
is an improvement over the current situation where such source compatibility
breakages are discovered later, and farther from where the decision was made.
Type Aliasing, and New Type
In RFC-0052: Type Aliasing and New Types we evolved type aliasing and new type declarations.
Aliases are declared as:
alias NewName = AliasedType;
i.e. unchanged from syntax proposed in RFC-0052.
New types are declared as:
type NewType = WrappedType;
i.e. the syntax for new types is the same whether the wrapped type is another existing type (wrapping) or some layout (new top-level type). This differs from the initially proposed syntax in RFC-0052.
Optionality
Certain types are inherently capable of being optional: vectors, strings,
envelopes, and layouts using such constructs i.e. table which is a vector (of
envelopes) and a union which is a tag plus an envelope. As a result, whether
these types are optional or not is a constraint, and can be evolved into
(becoming nullable, by relaxing the constraint), or evolved out of (becoming
required, by tightening the constraint).
On the other hand, types such as int8 or struct layout are not inherently
capable of being optional. In order to have optionality, one needs to introduce
an indirection, for instance via an indirect reference in the struct case. As a
result, unlike types which are inherently optional, no evolutionary path is
possible.
To distinguish between these two cases, and following the principle of keeping ABI concerns "on the left" and evolvable concerns "on the right" have:
| Naturally optional | Not naturally optional |
|---|---|
string:optional |
box<struct> |
vector:optional |
|
union:optional |
Naming wise, we prefer the terms "optional", "required", "present", "absent".
(We should avoid "nullable", "not nullable", "null fields".) In line with that
naming preference, we choose box<T> rather than pointer<T>. A box is
an optional by default structure, i.e. box<struct> in the new syntax is
equivalent to struct? in the old syntax, and box<struct>:optional is
redundant and may trigger a warning from the compiler or linter. This is to
better match the use case we expect: users generally box structs to get
optionality rather than to add indirection.
Constants
Constants are declared as:
const NAME type = expression;
Constraint ordering
When parameterizing a type based on layouts and constraints, the ordering of these arguments is fixed for a given type. This RFC defines the following orders for constraints (no type has multiple layout arguments yet):
- Handles: subtype, rights, optionality.
- Protocol client/server_end: protocol, optionality.
- Vector: size, optionality.
- Unions: optionality.
As a guiding principle, optionality always comes last, and, for handles, subtype before rights.
As an example, consider this struct with all possible constraints defined on its members:
type Foo = struct {
h1 zx.handle,
h2 zx.handle:optional,
h3 zx.handle:VMO,
h4 zx.handle:<VMO,optional>,
h5 zx.handle:<VMO,zx.READ>,
h6 zx.handle:<VMO,zx.READ,optional>,
p1 client_end:MyProtocol,
p2 client_end:<MyProtocol,optional>,
r1 server_end:P,
r2 server_end:<MyProtocol,optional>,
s1 MyStruct,
s2 box<MyStruct>,
u1 MyUnion,
u2 MyUnion:optional,
v1 vector<bool>,
v2 vector<bool>:optional,
v3 vector<bool>:16,
v4 vector<bool>:<16,optional>,
};
Future Direction
In addition to changes to the syntax to features which currently exist, we look and set the direction for features which are expected to see the light of day in the near future. Here, the focus is on intended expressivity and it's syntactic rendering (not on the precise semantics, which warrants separate RFCs). For instance, while we describe transport generalization, we do not discuss various thorny design issues (e.g. extent of configurability, representation in JSON IR).
This section is also expected to be read as directional, and not as a future specification. As new features are introduced, their corresponding syntax will be evaluated along with the precise workings of those features.
Contextual name resolution
E.g.
const A_OR_B MyBits = MyBits.A | MyBits.B;
Would be simplified to:
const A_OR_B MyBits = A | B;
E.g.
zx.handle:<zx.VMO, zx.rights.READ_ONLY>
Would be simplified to:
zx.handle:<VMO, READ_ONLY>
Constraints
Declaration site constraints
type CircleCoordinates = struct {
x int32;
y int32;
}:x^2 + y^2 < 100;
Use site constraints
type Small = struct {
content fuchsia.mem.Buffer:vmo.size < 1024;
};
Standalone constraints
constraint Circular : Coordinates {
x^2 + y^2 < 100
};
Constraints on envelopes
The syntax of tables and extensible unions hides the use of envelopes:
- A
tableis avector<envelope<...>>, and - A
unionis astruct { tag uint64; variant envelope<...>; }.
Right now, the ordinal: which appears in table and union declarations are
the only places where envelopes exist, and it's useful to think of this syntax
as the "sugared" introduction of an envelope. Essentially, we can de-sugar as
follows:
| Desugaring tables and flexible unions | |
table ExampleTable { 1: name string; 2: size uint32; }; |
table ExampleTable { @1 name envelope |
union ExampleUnion { 1: name string; 2: size uint32; }; |
union ExampleUnion { @1 name envelope |
Should we want to constrain the envelope, say to require an element, we
would place this constraint on the ordinal ordinal:C such as:
| Desugaring tables and flexible unions | |
table ExampleTable { 1:C1 name string:C2; 2:C size uint32; }; |
table ExampleTable { @1 name envelope<string:C2>:C1; @2 size envelope |
union ExampleUnion { 1:C1 name string:C2; 2:C size uint32; }; |
union ExampleUnion { @1 name envelope<string:C2>:C1; @2 size envelope |
Properties
FIDL's type system is already one which has the concept of constraints. We have
vector<uint8>:8 to mean that a vector has at most 8 elements, or string:optional
to relax the optionality constraint and allow the string to be optional.
Various needs are pushing towards both more expressive constraints, and an opinionated view of how these constraints are unified and handled.
For instance, fuchsia.mem/Buffer notes "This size must not be greater than the physical size of the VMO." Work is ongoing to introduce RFC-0028: Handle Rights, i.e. constraining handles. Or idea of requiring table fields, i.e. constraining the presence on otherwise optional envelopes.
Right now, there is no way to describe runtime properties of the values or
entities being manipulated. While a string value has a size, it is not
possible to name this. While a handle has rights associated with it, it is not
possible to name these either.
To properly solve the expressivity problem associated with constrained types, we must first bridge the runtime aspects of values, with the limited view which FIDL has of these values. We plan to introduce **properties **which can be thought of as virtual fields attached to values. Properties have no impact on the wire format, they are purely a language level construct, and appear in the JSON IR for bindings to give runtime meaning to them. Properties exist for the sole purpose of expressing constraints over them. Each and every property would need to be known to bindings, in a similar fashion that built ins are known to bindings.
Continuing the example above, a string value may have a uint32 size
property, a handle may have a zx.rights rights property.
For instance:
layout name {
properties {
size uint32;
};
};
Transport generalization
Declaring a new transport would at least require defining a new name, specifying constraints for the messages the transport supports (e.g. "no handles", "no tables"), and specifying constraints for the protocol (e.g. only "fire-and-forget methods", "no events").
The envisaged syntax resembles a configuration expressed in untyped FIDL Text:
transport ipc = {
methods: {
fire_and_forget: true,
request_response: true,
},
allowed_resources: [handle],
};
And then used as:
protocol SomeProtocol over zx.ipc {
...
};
Handle generalization
Right now, handles are a purely Fuchsia specific concept: they are directly tied
to the Zircon kernel, map to zx_handle_t (or equivalent in other languages
than C), and their kinds are only the objects exposed by the kernel such as
port, vmo, fifo, etc.
When considering other cases (e.g. in process communication), one desirable extension point is to be able to define handles in FIDL directly, rather than have that be a part of the language definition.
As an example, defining zircon handles:
library zx;
resource handle : uint32 {
properties {
subtype handle_subtype;
rights rights;
};
};
type handle_subtype = enum {
PROCESS = 1;
THREAD = 2;
VMO = 3;
CHANNEL = 4;
};
type rights = bits {
READ = ...;
WRIE = ...;
};
Which would allow handle or handle:VMO (or in another library
zx.handle:zx.handle.VMO).
An experimental implementation exists, and will be used to break the cyclic dependency between Zircon and FIDL (until this change, Zircon's API was described in FIDL, but FIDL was partly defined in terms of Zircon's API).
Implementation Strategy
A temporary "version declaration" will be added to the top of all .fidl files
to be used by fidlc to detect whether a .fidl file is in the prior or new
syntax.
This token will be immediately preceding the library statement:
// Copyright notice...
deprecated_syntax;
library fidl.test;
...
An explicit marker is preferred in order to simplify the role of fidlc in
detecting the syntax and to improve readability. An example of a challenge from
detecting syntax is the case where interpreting as either syntax leads to
compilation errors. These scenarios would require a heuristic to decide between
the old and new syntax, which could lead to surprising results.
Further, this token is added to all files in the prior syntax rather than in the
new syntax (e.g. new_syntax;") in order to socialize the aspect of the
upcoming migration - readers of FIDL files will get a sense that the syntax is
about to change and can seek additional context through other channels (e.g.
documentation, mailing lists).
A new fidlconv host tool will be added that can take FIDL files in the old
format and convert them to files in the new format, referred to as .fidl_new
for the purposes of this section. Though this tool is separate from fidlc,
it will need to leverage the compiler's internal representation to perform
this conversion correctly. For example, a type Foo will need to be converted to
client_end:Foo only if it is a protocol - to determine whether the case
fidlconv will leverage fidlc to compile the FIDL library first.
The FIDL frontend compiler fidlc as well as accompanying tools like the
formatter and linter will be extended to support either syntax based on the
marker defined above.
With this added functionality, the build pipeline will be extended as follows:
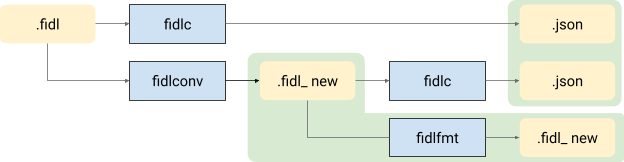
That is:
- A
fidlconvtool will convert FIDL files in the old syntax to the new syntax. - The
fidlccompiler will output the.jsonby compiling the old syntax. - Separately, the
fidlccompiler will output the.jsonIR by compiling the new syntax. - The
fidlfmtformatter will format the generated new library files.fidl_new.
For testing and verification:
- The two json IR will be compared, and verified to match (except for span information).
- Idempotency of the formatting of new libraries files will be verified to
check both the output of the
fidlccompiler, and of thefidlfmtformatter with the new syntax.
As part of this implementation, the FIDL team will also move the coding tables backend to be a standalone binary (in the same vein as other backends), and will obsolete and delete the C bindings backend by generating the last uses, and checking them in the fuchsia.git tree repository.
Ergonomics
This RFC is all about ergonomics.
We are willing to trade a short term productivity loss to developers familiar with the current syntax as they retrain to use this modified syntax as we strongly believe the many more developers who will be using FIDL in the future will greatly benefit.
Documentation and Examples
This will require changing:
- FIDL language specification
- FIDL grammar
- all FIDL code examples
Backwards Compatibility
This change is not backwards compatible. See the implementation section for the transition plan.
Performance
This change has no impact on performance.
Security
This change has no impact on security.
Testing
See the implementation section for the transition plan, and verifying its correctness.
Drawbacks, Alternatives, and Unknowns
Using colon to separate name from type
Since we're moving types to be second, we could also consider using the quite
common : separator as is done in type theory, Rust, Kotlin, the ML languages
(SML, Haskell, OCaml), Scala, Nim, Python, TypeScript, and many more:
field: int32 rather than the proposed field int32
This proposal rejects this approach.
The : separator is primordially used to separate layouts from constraints. It
is also used to indicate a "wrapped type" for enum and bits declarations.
Finally it is used to denote envelopes in table and union declarations.
Further overloading the : separator, especially in close grammatical proximity
to its main use will lead to confusion (e.g. a table member 1: name:
string:128;).
Omitting semicolons
It has been discussed to work to omit semicolons terminating declarations (be it member, const, or other).
This proposal chooses not to explore this simplification.
Removing semicolons makes little syntactic difference for FIDL authors. It's also not a key change to make, and should we want to explore this in the future it will be easy to modify (e.g. Go's approach to remove semicolons).
However, presence of semicolons to terminate members and declarations makes it
much easier to guarantee unambiguous grammar rules especially as we explore
constraints (use-site and declaration-site). For instance, with a declaration
site layout constraint (C) such as struct Example { ... }:C; we delineate a
constraint nicely between the : separator and the ; terminator.
Unifying enums and unions
From a type theoretic standpoint, an enumeration represents a sum of unit types, and a union represents a sum of any types. It is therefore tempting to seek to unify these two concepts into one. This is the approach taken by programming languages which support ADTs such as ML or Rust.
However, from a layout standpoint, a sum type of only unit types (an
enumeration) can be represented much more efficiently than the extensible
counterpart (a union). While both offer extensibility in light of adding new
members, only unions offer extensibility to go from unit types (e.g. struct
{}) to any types. This extensibility comes at a cost of an inline envelope.
We have chosen a pragmatic approach that balances the complexity of having two constructs, with the performance benefit of special casing enumerations.
References
On syntax
On extensible method arguments
On type aliasing and named types
Footnote2
While it may seem odd to prefer syntactic conciseness over explicitly choosing a
wrapped type, having a sensible default provides greater consistency for enums
across FIDL libraries. This in term provides a migration path to switch enums
down the road, e.g. should a library define a general purpose ErrorStatus
enum, it could be replaced later by another 'better' general purpose
ErrorStatusV2.
-
Or at least, not without a good understanding of the wire format and care, e.g. https://fxrev.dev/360015 ↩