
| RFC-0026:隨處可見的信封 | |
|---|---|
| 狀態 | 已遭拒 |
| 區域 |
|
| 說明 | 將信封壓縮超過兩倍,提高現有信封格式的效率。使用封裝做為參照所有行外物件的唯一方式。這可提高線路格式的一致性,以及通訊協定設計和實作的統一性。 |
| 作者 | |
| 提交日期 (年-月-日) | 2019-01-19 |
| 審查日期 (年-月-日) | 2019-02-04 |
拒絕原因
考量到這份 RFC 的意見回饋和留言數量,我們決定撤回 (即自行拒絕) 這項提案。不過,這份草案仍有許多很棒的想法,我們會將這些想法發布為範圍較小的獨立 RFC,方便進行更清楚的討論,並將獨立功能分別納入各自的 RFC。
RFC-0032 是從這個 RFC 衍生而來。
摘要
這項 RFC 有兩個目標:
- 現有
envelope格式的效率可提升,因為信封會壓縮超過兩倍。 - 使用信封做為參照所有非行內物件的唯一方式。 這可提高線路格式的一致性,以及通訊協定設計和實作的統一性。
(1) 和 (2) 的副作用是,所有型別 (不只是結構體、控制代碼、向量、字串、表格和 (可擴充) 聯集) 都可以有效率地實作選用性 (可為空值) 1。
提振精神
信封是可擴充、可演進資料結構 (表格和可擴充聯集) 的基礎。提高信封效率,可讓這些可擴充的結構體用於更多重視效能和線路大小的環境。
FIDL 也有幾種普遍使用的型別,用於動態大小的資料:向量和字串。由於 FIDL 主要物件的大小預計會靜態已知,因此這些型別必須是行外型別。如果信封可用於表示所有超出範圍的資料,我們就能簡化通訊協定和實作程序,降低實作成本並減少錯誤空間。
此外,FIDL 也會受益於選用性的整體一致做法。這可帶來更符合人體工學的體驗,並提供比現行機制更多類型的選項,同時簡化使用者的心智模型。信封會以一致的方式為所有型別啟用選用性,藉此達成這些目標。
設計
信封可指下列資料:
- 行外,類似現有的信封格式,或
- 內嵌:資料儲存在信封本身。這可用於固定大小且小於 64 位元的「小型」型別。
Out-Of-Line Envelopes
不符規定的信封包括:
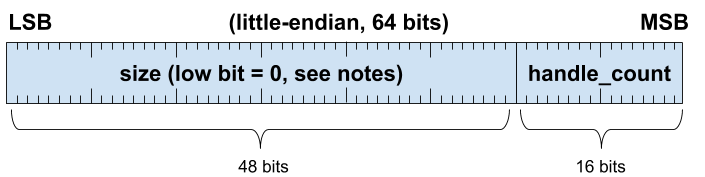
做為 C 結構體:
typedef struct {
uint64_t size:48; // Low bit will be 0
uint16_t handle_count;
} fidl_out_of_line_envelope_t;
與現有信封格式相比,非行內信封有以下變更:
- 大小 (num_bytes) 為 48 位元,而非 32 位元,因此可使用較大的酬載。
- 大小包括可能以遞迴方式編碼的任何子物件大小。
- 舉例來說,
vector<string>的大小包括外部向量內部字串子物件的大小。 - 這與目前封包實作的 size 欄位現有行為相符。
- 舉例來說,
- 由於非行內物件會對齊八位元組,因此合法非行內物件的大小一律為 8 的倍數。這表示
size % 8 == 0,也就是說 - 請參閱下方的「離線封包的編碼大小」,瞭解計算遞迴大小對效能的影響。
- 大小包括可能以遞迴方式編碼的任何子物件大小。
handle_count為 16 位元,而非 32 位元。- 目前無法透過 Zircon 管道傳送超過 64 個控制代碼;我們認為 16 位元足以因應未來需求。
handle_count包含所有遞迴子物件的控制碼計數。
- 已捨棄「存在/缺席」欄位。
- 如果
size或handle_count欄位的值不為零,即表示存在。 - 如果
size和handle_count欄位都為零,則表示缺席。- 這稱為「零信封」。
- 如果
假設解碼器知道封包內容的靜態型別 (結構),則 MAY 會以封包資料的指標覆寫封包。如要瞭解如何處理內容類型不明的封包,請參閱「解碼器回呼」一節的建議。
標記位元
行外封包的大小明確佔用最低有效位元,控制代碼計數則佔用最高有效位元。如「信封」一節所述,
- 因為大小欄位的最低位元一律為零 (由於大小是 8 的倍數),
- 封包的最低位元也一律為零。
我們將封包的最低位元稱為「標記位元」。
- 如果標記位元為零,信封的資料會超出範圍。
- 如果標記位元為 1,信封的資料會內嵌。
由於標記位元是內嵌資料的位元,內嵌封包也無法成為需要 64 位元對齊的架構上的實際指標,因為指標會是 8 的倍數,且也需要最低的三個位元為零。這項功能有助於解碼器區分內嵌封包和實際指標,因為解碼器通常會以封包內容的指標覆寫行外封包,但不會覆寫行內封包。
內嵌信封
內嵌信封的編碼方式如下:
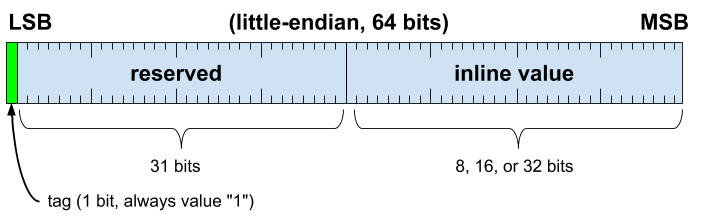
做為 C 結構體:
typedef struct {
uint8_t tag:1; // == 1
uint32_t reserved:31;
union {
_Bool bool;
uint32_t uint32;
int32_t int32;
uint16_t uint16;
int16_t int16;
uint8_t uint8;
int8_t int8;
float float32;
zx_handle_t handle; // Only when decoded (see Handles for more details)
};
} fidl_inline_envelope_t;
- 內嵌信封的 LSB 會設為 1,與行外信封和實際指標有所區別。
- 信封的上 32 位元用於表示內嵌值,可以是
int8、uint8、int16、uint16、int32、uint32、float32、bool或控制代碼。- 如果值小於 32 位元寬度,則會使用高位元 32 位元的最低位元來表示值,這是標準的小端序表示法。
- 除非日後的 RFC 規定如何解讀這些位元,否則編碼器「必須」將保留位元編碼為零。
- 解碼器和驗證器必須忽略保留位元,除非日後的 RFC 說明如何解讀這些位元。
- 解碼器「應」在解碼期間保留內嵌封包。
- 由於內嵌資料具有內嵌資料,不需要參考行外資料,因此在就地解碼時,解碼器不需要以指標取代內嵌資料 (與行外封包不同)。
編碼器應編碼為行外或內嵌?
編碼器必須:
- 如果類型為
bool、(u)int8、(u)int16、(u)int32、float32或控制代碼,請內嵌編碼資料。(非正式:如果類型為固定大小且 <= 32 位元)。 - encode data out-of-line for all other types. (非正式:如果型別為 >= 64 位元或大小可變動)。
帳號代碼
控制代碼宣告有三種情境:
- 不可擴充容器中的非選用控點,例如
struct S { handle h; }; - 非可擴充容器中的選用控點,例如
struct S { handle? h; }; - 可擴充容器中的控點,例如
table T { handle h; }
針對 (1) 中非可擴充容器中的非選用控制代碼,我們建議保留現有的連線格式,也就是 uint32。在不可擴充的容器中,非選用控制代碼不需要是封包,因為封包的設計用途是攜帶選用或動態大小的資料。
對於 (3),可擴充容器中的控制代碼:由於封包是可擴充容器的基礎,因此必須使用封包編碼控制代碼。如要編碼控制代碼,編碼器「必須」將其編碼為行外封包,並將 size 設為 0,handle_count 設為 1:
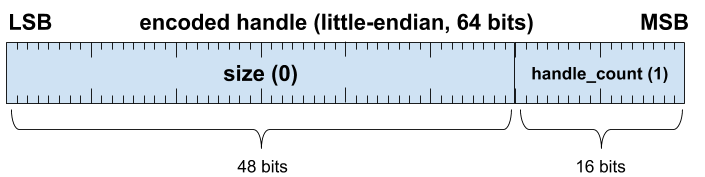
這個編碼會指示解碼器在行外控制代碼表格中查閱控制代碼值。如果解碼器想就地解碼,則解碼器「應」採取下列做法:
- 在行外控制代碼資料表中查閱控制代碼,判斷實際的控制代碼值。
- 將標記位元設為 1,將信封從行外變更為行內。
- 將 fidl_inline_envelope_t 結構體的控制代碼欄位設為實際控制代碼值。
如需編碼/解碼控制代碼的範例,請參閱「範例」一節。
我們選擇這種雙重編碼/解碼形式,是因為它同時與行外和內嵌信封編碼相容。雖然這會導致信封中的控點出現專用程式碼,但我們認為,與需要更多編碼的簡單程式碼相比,擁有更統一 (即更少) 的資料編碼是更好的取捨方式。
對於 (2) 中非可擴充容器的可選控制代碼,我們也建議使用與內容 (3) 相同的封包表示法做為連線格式,也就是雙重離線編碼/內嵌解碼形式。很抱歉,這個選用控制代碼的表示法比現有的選用控制代碼線路格式更不精簡,後者為 uint32。不過,我們仍建議使用以信封為基礎的表示法,因為
- 使用選用控制代碼的封裝函式,與使用任何選用型別的封裝函式一致,
- 相較於其他訊息類型,FIDL 訊息中的選用控制代碼相對較少2,因此額外 4 個位元組的封包負荷不應大幅影響訊息大小,
- 如果保留選用控制代碼的現有
uint32線路格式,控制代碼就會有三種編碼和三條不同的程式碼路徑:非選用、選用和信封中的控制代碼。使用選用項目的波封表示法可省去一個編碼和一個程式碼路徑,進而提高一致性並減少專用程式碼。
(2) 的編碼 (非可擴充容器中的選用控制代碼) 會明確列於下方的「設計決策」一節,因為選用控制代碼的 uint32 較精簡,可能值得考慮。
字串和向量
目前不可為空值的 String 和Vector 的線路格式會儲存為 16 個位元組:
uint64,表示元素數量 (向量) 或位元組數 (字串),- 表示存在/不存在/指標的
uint64。
我們建議使用封裝來表示字串和向量,可為可為空值或不可為空值:
- 元素 (向量) 或位元組 (字串) 的數量會移出內嵌。
- 這樣一來,向量/字串就能以封包 (僅限) 表示,因此封包會成為參照任何行外資料的唯一方式 (適用於所有 FIDL 型別),確保所有行外資料的表示方式一致。
- 向量/字串內容位於獨立的行外物件中,並緊接在元素/位元組計數之後。
- 波封為零或非零,決定了是否存在。
如果是向量,請注意,向量元素計數與封包大小不同:
- 封包大小為向量元素計數乘以元素大小。
- 如果向量包含子物件 (例如
vector<Table>、vector<vector<string>>),封包大小會包含所有遞迴子物件的大小。
可為空值的字串/向量,以及可擴充容器內的字串/向量,會以與不可為空值的字串和向量相同的方式表示:系統會使用零封包表示字串/向量不存在。
反之,如果字串/向量不可為空值,驗證器遇到零封包時,就必須回報錯誤。
對於使用 C 繫結的程式碼,這可能是原始碼破壞性變更,因為這類程式碼會預期 fidl_vector_t 和 fidl_string_t 的記憶體布局與連線格式完全相符。不過,我們可以在線路格式變更前實作過渡計畫 (例如將 C API 變更為使用函式或巨集),以便進行軟性轉移。
請注意,您還是可以透過彈性陣列成員 (例如 struct {
uint64 element_count; element_type data[]; };),將這個新的字串/向量版面配置表示為 C 結構體。
選用 (可為空值) 型別
目前,結構體、字串、向量、控制代碼、聯集、資料表和可擴充聯集可以設為選用 (可為空值)。
在所有位置使用信封,即可讓所有類型成為選用項目:
- 系統會將選用資料連同信封儲存,可選擇以行外或行內方式儲存。
- 如果缺少選用資料,系統會以零信封的形式儲存。
請注意,對於小型類型,視容器的對齊需求而定,內嵌資料可盡可能緊密地儲存選用類型,就像儲存非選用類型一樣。
編碼/解碼表單的 C/C++ 結構體
信封的編碼形式可以由內嵌或非內嵌信封的聯集表示。同樣地,解碼後的封包可以是內嵌、指向封包資料的指標,或回呼決定的值 (詳情請參閱「解碼器回呼」一節)。
typedef union {
fidl_inline_envelope_t inline; // Low bit is 1
fidl_out_of_line_envelope_t out_of_line; // Low bit is 0
} fidl_encoded_envelope_t;
typedef union {
fidl_inline_envelope_t inline; // Low bit is 1
void* data; // Low bit is 0
uintptr_t callback_data; // Value determined by callback (see Decoder Callback)
} fidl_decoded_envelope_t;
static_assert(sizeof(fidl_encoded_envelope_t) == sizeof(void*));
static_assert(sizeof(fidl_decoded_envelope_t) == sizeof(void*));
不明資料
當接收器 (驗證器和解碼器) 用於可演進的資料結構 (例如資料表或可擴充的聯集) 時,可能不知道封包的類型。如果接收者不知道信封類型:
- 您可以放心忽略內嵌信封。
- 控制代碼必須使用行外封包 (而非行內封包) 編碼,因此可安全地忽略所有行內封包。
- 系統會盡量剖析並略過不符合規範的信封。
- 信封大小決定要略過的離線資料量。
- 如果封包的控制代碼計數不為零,驗證器「必須」處理指定數量的控制代碼。
- 預設處理行為必須是關閉所有控制代碼。
- 如果解碼器想就地解碼,可以將不明封包覆寫為指向封包內容的指標。
- 如果解碼器確實會以指標覆寫封包,封包中的大小和控制代碼計數資訊就會遺失。如果這會造成問題,請參閱「解碼器回呼」一節,瞭解替代方案。
請注意,如果需要略過許多不明類型,將大小嵌入行外封包可透過 FIDL 訊息快速線性搜尋。
解碼器回呼
如「不明資料」一節所述,解碼器可能會覆寫不明信封,導致解碼器遺失大小和控制代碼計數資訊。或者,解碼器可以附加回呼,處理封包並覆寫預設行為。callback API 可能類似下列函式原型:
void set_unknown_envelope_callback(
unknown_envelope_callback_t callback, // a callback
void* context // client-specific data storage
);
typedef uintptr_t (*unknown_envelope_callback_t)(
const void* message, // pointer to the envelope's containing message
size_t offset, // offset in the message where the unknown envelope is
size_t size, // the envelope's size
size_t handle_count, // the envelope's handle count
const char* bytes, // pointer to the envelope's data
void* context // a context pointer set via set_unknown_envelope_callback()
);
回呼會傳回 uintptr_t,解碼器可用於覆寫不明封包。這可讓解碼器從不明封包複製大小和控制代碼計數,並以指向解碼器自有自訂資料結構的指標覆寫封包。
行外信封的編碼大小
這項 RFC 規定,行外封包必須具有正確的 (遞迴) 大小,才能呈現行外資料。如果接收者應知道封包類型,則解碼器可以計算大小 3,因此大小欄位並非必要,這項規定可能會增加編碼器的負擔。因此,編碼器可說是額外執行工作,但沒有明顯好處。這項論點也適用於控制代碼計數。
不過,我們仍建議您提供大小和控制代碼計數,原因如下:
- 一致性:要求大小表示所有用途的封裝編碼都一致,無論是否在可擴充的容器內。提高一致性可減少程式碼,並簡化認知模型。
- 我們稍後可以變更這項設定。
未來的 RFC 可選擇使用大小的標記值 (例如
UINT48_MAX),或保留大小欄位中的其中一個 LSB,表示大小不明,在這種情況下,解碼器必須遍歷行外酬載並自行計算大小。由於欄位結構維持不變,因此這項變更不會影響線路格式。此外,由於解碼器可以先實作邏輯,再更新編碼器,因此也可以做為軟轉換。
整體而言,RFC 作者認為,針對大小不明的項目要求編碼可能過早進行最佳化,並建議從簡單、更一致的統一設計開始。如果我們認為日後應重新審視這項決定 (例如零複製 向量 I/O 編碼器可用,因此編碼器不必修補封包即可寫入正確大小),則可清楚瞭解如何以軟轉換方式實作。
範例
選用的 uint 儲存內嵌:
uint32? u = 0xdeadbeef; // an optional uint: stored inline.
C++ 表示法:
vector<uint8_t> object{
0x01, 0x00, 0x00, 0x00, // inline tag
0xEF, 0xBE, 0xAD, 0xDE, // inline data
};
選用的 vector<uint16> 儲存的行外:
vector<uint16>? v = { 10, 11, 12, 13, 14 }; // an optional vector<uint16>; stored out-of-line.
離線大小為 24:
- 元素數量 (以獨立的次要物件形式儲存) 佔 8 個位元組,
- 向量內容 + 10 (5 個元素 *
sizeof(uint16_t)), - = 18,四捨五入為 24,以利對齊。
C++ 表示法:
vector<uint8_t> object{
0x18, 0x00, 0x00, 0x00, 0x00, 0x00, // envelope size (24)
0x00, 0x00, // handle count
};
vector<uint8_t> sub_objects{
// element count
0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
// vector data
0x0A, 0x00, 0x0B, 0x00, 0x0C, 0x00, 0x0D, 0x00,
0x0E, 0x00,
// padding
0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
};
包含三個欄位的 table:
table T { 1: int8 i; 2: reserved; 3: int64 j; } = { .i: 241, .j: 71279031231 };
C++ 表示法:
// a table is a vector<envelope>, which is represented with an
// out-of-line envelope
vector<uint8_t> object{
0x28, 0x00, 0x00, 0x00, 0x00, 0x00, // envelope size (40)
0x00, 0x00, // handle count
};
vector<uint8_t> sub_objects{
// vector element count (max table ordinal)
0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
// vector[0], 1: int8, stored inline
0x01, 0x00, 0x00, 0x00, // inline tag
0xF1, 0x00, 0x00, 0x00 // 241
// vector[1], 2: reserved
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, // zero envelope
// vector[2], 3: int64, stored out-of-line
0x08, 0x00, 0x00, 0x00, 0x00, 0x00, // envelope size
0x00, 0x00, // handle count
// vector[2] content
0xBF, 0xB3, 0x8F, 0x98, 0x10, 0x00, 0x00, 0x00 // 71279031231
};
控點:
handle h; // decoded to 0xCAFEF00D
C++ 表示法:
vector<uint8_t> encoded_form{
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, // envelope size
0x01, 0x00, // handle count
};
vector<uint8_t> decoded_form{
0x01, 0x00, 0x00, 0x00, // inline tag
0x0D, 0xF0, 0xFE, 0xCA, // inline data
};
導入策略
這項 RFC 是破壞性的連線格式變更。雙方 FIDL 對等互連都需要瞭解新的連線格式,並將這項瞭解內容傳達給對等互連,雙方才能使用新格式。
可以進行軟轉換。方法有兩種:
- 交易訊息標頭中含有
uint32保留/旗標欄位。 我們可以保留 1 位元,供發起對等互連的節點指出其瞭解新的連線格式,並分階段進行軟轉換:- 確保所有用戶端和伺服器都能解讀新舊線路格式。我們繼續使用舊的傳輸格式。
- 如要啟用新的線路格式,請讓對等互連設定交易訊息標頭中的位元。如果雙方都設定了位元,雙方都可以切換至新的線路格式。
- 軟轉移作業完成後,所有 Fuchsia 層都可以使用新的線路格式。我們可以移除在交易訊息標題中設定位元的動作。
- 刪除舊線路格式的程式碼,並取消預留交易訊息標頭位元。
- 我們可以為特定 FIDL 訊息型別、介面或兩者,加上
[WireFormat=EnvelopeV2]屬性 (或類似屬性),指出訊息/介面應使用新的線路格式。- 雖然使用
[WireFormat]屬性裝飾介面似乎更符合線路格式變更,但實作結構體的 WireFormat 變更應該會比較容易,因為結構體可用於不同介面,而繫結需要額外的邏輯來判斷結構體的使用情境。 - 建議介面
[WireFormat]屬性只影響介面方法引數的線路格式,而不遞迴影響引數的結構體。 - 這樣一來,團隊就能選擇部分遷移及採用新的連線格式,並自行決定遷移速度。
- 所有結構體和介面都具有
[WireFormat]屬性後,我們就可以捨棄舊的線路格式,假設所有結構體和介面都使用新的線路格式,並忽略該屬性。
- 雖然使用
這兩種軟性轉移方法都需要大量開發時間、測試時間,且容易出錯。正確導入程式碼來執行任一方法、執行計畫,以及順利移除舊程式碼,都需要投入大量心力。
我們可能會同時處理舊版和新版連線格式的程式碼;否則,在實作新版連線格式的支援功能時,就無法逐步導入 CL。由於處理這兩種連線格式的程式碼都會存在,建議您使用任一方法,製作軟轉換是否可行的原型。如果不是,那就沒辦法,只能硬性轉移。
無論是軟性或硬性轉移,Fuchsia 中任何手動建立 FIDL 訊息的執行個體,都必須升級至新的線路格式。
我們也應利用這次的線路格式變更,併入其他需要進行的變更 (例如建議的序數大小變更)。
請注意,相較於 FIDL1 到 FIDL2 的轉換,這項轉換較為簡單,因為 FIDL2 大幅變更了語言繫結。由於沒有使用者可見的變更4,因此我們不建議將此 FIDL 稱為 3。
回溯相容性
提議的線路格式變更與 API (來源) 相容,但有一個例外:如果我們將向量/字串元素計數移至行外,C 繫結就會成為 API 中斷性變更。為減輕這項影響,我們可以在新線路格式推出前,預先規劃並使用巨集或函式,將目前的 C 繫結抽象化。
線路格式變更與 ABI 不相容,但您可以透過「實作策略」一節中列出的策略,讓現有程式碼與 ABI 相容。
效能
這項 RFC 可大幅縮減信封所需的大小,這似乎會帶來顯著的整體淨效益。不過,整體效能影響較不明顯。提升效能:
- 使用可擴充資料結構 (資料表和可擴充聯集) 的 FIDL 訊息會變得更精簡。
- 如果波封和選用性具有統一的表示法,由於程式碼可以共用,因此可能會縮減程式碼大小並改善快取位置。
不過,請注意以下幾點:
- 如果可擴充資料結構因效率較高而更普及,則使用量增加可能會抵銷這項優勢,導致訊息較不精簡,且動態分配的資源較多,而非使用不可擴充的資料結構。
- 為所有型別導入選用性可能會使 FIDL 訊息略為變大,因為使用者可能會使用這項功能,將先前非選用的型別設為選用。
- 如果我們決定對選用控制代碼使用信封編碼,選用控制代碼的效率就會降低。
- 如「離線封裝的編碼大小」一節所述,在封裝中編碼大小和控點計數,對於接收端來說,是目前行為的效能回歸。
人體工學
- 所有 FIDL 類型都可以啟用選用性。 這項人體工學改良措施可讓選用性保持一致,而非僅適用於特定類型。
- 更有效率的可擴充資料結構可在更多重視效率的環境中使用,因此使用者不必太擔心效能問題,而且可享有可擴充性的優點,不必再使用不可擴充的結構。
- 我們甚至可能建議預設應將表格用於 FIDL 資料結構,而結構體則保留用於高效能環境。
- 可擴充聯集 (RFC-0061) 正在嘗試移除靜態聯集。
說明文件
- 線路格式說明文件需要更新。
- 更新說明文件時,應將封包說明為第一級概念:這樣一來,讀者遇到選用性和可擴充資料結構的連線格式時,就能更輕鬆地認知分塊。
- 我們應更新 FIDL 樣式指南,建議何時應使用選用類型 (相較於具有信號值的非選用類型)。
安全性
- 這項 RFC 不應會對安全性造成重大影響。
- 不過,為操控行外和行內封包格式而進行的位元運算,應經過充分測試並保守處理,確保程式碼能妥善處理極端情況。我們認為,使用標準 C/C++ 結構體/聯集來表示信封 (而非手動位元移位和遮罩),可大幅提升程式碼正確性。
測試
- 由於這項 RFC 會變更信封的連線格式,我們認為現有的 FIDL 測試套件 (尤其是相容性測試) 足以測試所有使用信封的案例。
- 我們會為行外和內嵌表單新增波封剖析、編碼和解碼的單元測試,因為這可能是容易出錯的區域。
- 如果我們同意將線路格式變更做為軟轉換 (請參閱「實作策略」一節),我們會新增同層級協商測試,並可能切換至新的線路格式。
- 如果我們同意將所有型別的選用性公開做為這項變更的一部分,則需要為任何可選用的型別新增測試。
缺點、替代方案和未知事項
- 如果我們認為這項提案的效率提升幅度不值得實作成本,可以保留現有的線路格式。如果是這樣,我們就必須尋找替代策略,為所有類型導入選用性。
- 針對可擴充容器和選用型別使用專門的表示法,可能比針對所有情況使用封裝更有效率。不過,由於存在這項 RFC,我們顯然認為封包提供的通用性和一致性,比專屬表示法的效率提升更重要。
設計決策
雖然這項 RFC 提出建議,但我們仍積極尋求以下決策的意見和共識:
- 請參閱「字串和向量」一節,瞭解如何將元素計數 (向量) 和位元組計數 (字串) 移出列外,這會影響 C 繫結。我們可以選擇不這麼做,但代價是統一性較低:字串和向量會成為例外,所有超出範圍的參照都會使用封裝。(信封仍可用於參照行外向量/字串資料)。
- 我們是否要考慮軟性或硬性轉移?如要瞭解優缺點,請參閱「導入策略」一節。
- 我們建議在行外封包中使用 48 位元表示大小,並使用 16 位元表示控制代碼。相較之下,目前的信封格式使用 32/32 位元。48 位元的大小是否合理?
- 我們建議使用封裝來編碼非可擴充容器中的選用控制代碼,這比目前的選用控制代碼編碼 (8 位元組對 4 位元組) 更不精簡。
- 這裡必須在精簡和更專業的程式碼與一致性之間取捨。我們認為,相較於更精簡的專屬表示法,一致性和統一性更為重要,因為選用控制代碼的使用情況可能相對較少。(程式碼中 37 個選用用途,而非 187 個非選用用途)。
- 我們是否要立即啟用選用性?
- 我們建議在升級線路格式時,針對所有類型顯示選用性,因為這項變更可以逐步完成。
- 導入這類選用性功能需要變更剖析器、編碼器、驗證器和解碼器,這項工程相當浩大,因此有必要另行轉換。
- 我們建議內嵌 <= 32 位元的型別;我們可以更積極地內嵌。
- 由於標記位元在 64 位元封包中只使用一個位元,因此我們可以內嵌任何 <= 63 位元的資料。
- 我們可以針對小型字串和向量使用專門的表示法,例如元素/位元組計數的一個位元組,然後是字串/向量資料,藉此內嵌這些字串和向量。(如需靈感,請參閱先前作品)。
- 我們捨棄了這些方法,即使它們更有效率,因為根據內容而非型別內嵌,表示 (1) 解碼器無法根據型別預先得知是否要預期內嵌或外嵌封包,且 (2) 變更欄位內容表示可以不同方式編碼,這似乎與 FIDL 的目標和靜態焦點相違背。
既有技術和參考資料
作者從現有的標記指標用法中獲得許多靈感,這類指標在動態和函式語言中歷史悠久。特別是 Objective-C 64 位元執行階段會大量使用這些指標,以提升效能 (甚至還會使用專用的5/6 位元編碼來處理內嵌字串)。
由於目前的 64 位元平台通常會使用 48 位元 (或更少) 編碼指標,我們考慮從解碼指標中竊取更多位元,並使用位元移位嘗試在指標中編碼行外物件的大小。不過,部分架構已將實體位址空間擴展至 48 位元以上 (ARM64、x64-64 5 層分頁),因此竊取更多指標位元可能無法因應未來的需求。