
| RFC-0132:FIDL 表大小限制 | |
|---|---|
| 状态 | 已接受 |
| 区域 |
|
| 说明 | 此 RFC 将 FIDL 表限制为最多 64 个条目。 |
| Gerrit 更改 | |
| 作者 | |
| 审核人 | |
| 提交日期(年-月-日) | 2021-09-20 |
| 审核日期(年-月-日) | 2021-10-04 |
摘要
此 RFC 将 FIDL 表限制为最多 64 个成员。
另请参见:
设计初衷
发送 FIDL 表(构建、编码和解码)的用户模式性能成本是表正文中的最大设置序号的函数。此行为对用户来说并不明显或直观,如果使用不当,可能会对性能产生负面影响。此 RFC 建议设置限制,以防止近期出现严重行为,作为临时解决方案,促使 FIDL 作者重新思考其设计,并鼓励 FIDL 团队在 FIDL 作者开始遇到限制时提供更好的长期解决方案。
利益相关方
哪些人会关心此 RFC 是否被接受?
协调人: pascallouis@google.com
审核人: pascallouis@google.com、yifeit@google.com、mkember@google.com
咨询对象: ianloic@google.com、azaslavsky@google.com、abarth@google.com
共同化: 不适用
设计
表将限制为最多 64 个序号。具体而言:
- 如果序号值高于 64,FIDL 编译器必须发出错误。
- 收到高于 64 的序号时,绑定不得出错。 它们可能会忽略高于 64 的序号。
此外,如果第 64 个序号是非预留序号,则必须包含另一个表,作为确保消息继续可扩展的机制。 具体而言,如果第 64 个序号是非预留序号,并且分配了非表类型,FIDL 编译器必须发出错误。
实现
这将需要更改 FIDL 编译器以及每个 FIDL 绑定。
性能
本部分中的所有测量值均以纳秒为单位,并且是在配备 Intel Core i5-7300U CPU @ 2.60GHz 的 NUC 上记录的。
以下显示了单向通信所需的总(构建 + 编码 + 解码)用户模式时间,以 LLCPP 为单位进行测量:
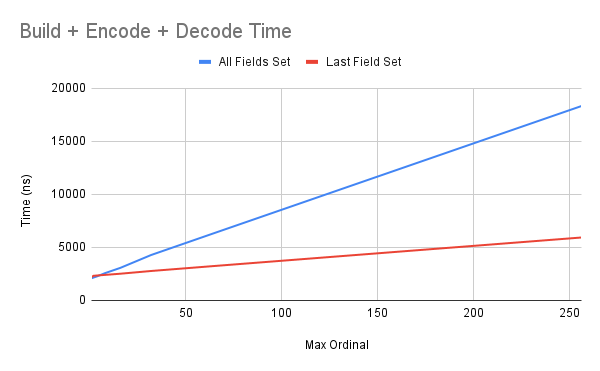
仅设置最后一个字段和设置所有字段这两种情况都非常接近线性,斜率分别为 14.7 纳秒/字段和 63.7 纳秒/字段。这意味着未设置或预留的字段大约需要 14.7 纳秒,而设置的字段大约需要 63.7 纳秒。
当最大序号为 64 时,最后一个字段设置时间为 3234.1 纳秒,所有字段设置时间为 6294.2 纳秒。
请注意,这些时间可能会随着绑定实现的变化而变化。
以下显示了 Fuchsia 系统中 FIDL 表定义中最大非预留序号的当前分布情况:
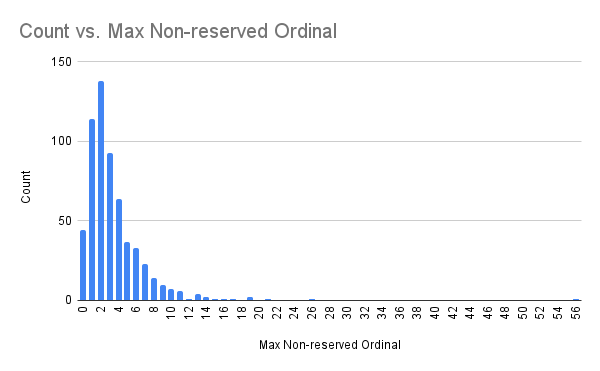
表定义中的最高序号为 56,次高序号为 26。包含 56 个字段的表中有许多字段被不必要地标记为预留字段,可以重新构建为更紧凑的表。这意味着当前表在一段时间内通常不会达到 64 个序号的限制。
较小的分配
某些绑定(例如 LLCPP)会计算消息所需的最大缓冲区空间,并使用此信息来确定分配的大小。如果表的大小不再不受限制,则在某些情况下可以减小分配的大小,这可能会提高性能。
工效学设计
此 RFC 使 FIDL 的使用更加困难,因为现在必须考虑限制。
向后兼容性
此 RFC 会破坏与包含超过 64 个条目的表的向后兼容性。
安全注意事项
这没有安全影响。
隐私注意事项
这没有隐私影响。
测试
GIDL 测试将验证线格式是否未更改,并且对超过 64 个条目的表的解码是否继续有效。 单元测试将检查编译器级更改。
文档
需要更新 FIDL 语言文档以指明此限制。
缺点、替代方案和未知事项
为什么限制为 64?
64 的限制是任意的,但之所以选择此限制,有以下几个原因:
它大于绝大多数用例所需的大小。 会有一些异常值,但它们可以使用替代结构来表示数据。如果限制为 32,则会更接近目前常用的表大小。
如果限制大于 64,则在某些情况下,用户可能会对性能下降感到意外。如果发现更常见的需要更高的限制,仍然可以通过另一个 RFC 再次提高限制。
64 是 64 位整数中的位数。这使得绑定可以潜在地使用位标志来标记存在或不存在。同样, 位掩码可用于定位序号,如被拒绝的 RFC RFC-0016 中所示。
大型表的替代方案
可以使用多种替代结构来代替大型表。联合向量就是这样一种选择 - 它与表类似,具有可扩展性,但对联合字段的数量没有限制。它还具有一种表示形式,可能更适合稀疏使用字段的情况。
稀疏表布局
之前被拒绝的 RFC 探索了一种替代表布局,该布局支持 更稀疏的表示形式: RFC-0116:对稀疏 FIDL 表的线格式支持
如果表使用更稀疏的表示形式,则可能不太需要大小限制。