
| RFC-0151:针对 CPU 目标的编译器调整标志 | |
|---|---|
| 状态 | 已接受 |
| 区域 |
|
| 说明 | 针对控制 CPU 目标平台的编译器标志提出的更改,以及这些更改对平台和 SDK build 的影响。 |
| 问题 | |
| Gerrit 更改 | |
| 作者 | |
| 审核人 | |
| 提交日期(年-月-日) | 2022-01-04 |
| 审核日期(年-月-日) | 2022-02-02 |
摘要
针对控制 CPU 目标平台的编译器标志提出的变更,以及这些变更对平台和 SDK build 的影响。
设计初衷
Fuchsia 的 build 会生成许多制品,这些制品包含适用于不同架构的可执行机器代码。例如:预构建的共享库(发布以供 SDK 使用),或者包含在平台和产品系统映像中的可执行 C/C++ 或 Rust 二进制文件。在编译器中生成机器代码时,务必指明以下内容:
目标架构:要使用哪种指令集架构?例如,x86-64 或 AArch64 ISA。此外,编译器还可以针对 ISA 的修订版本。 修订版可能会提供额外的指令或对现有指令的变体,例如新的浮点或 SIMD 指令,或更广泛的原子内存操作,这些指令可以显著提高性能。了解目标架构对于生成保证可在目标设备上运行的代码至关重要。“提高”目标架构会解锁新功能,但会牺牲与旧硬件的向后兼容性。
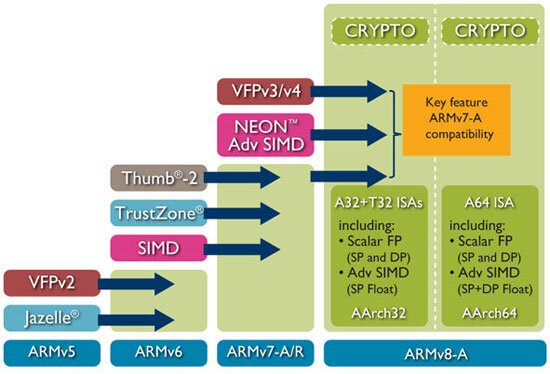
上方:ARM ISA 的发展历程(来源)
目标微架构:ISA 是如何实现的?这通常通过指令是按顺序执行还是无序执行、解码带宽、缓存加载延迟时间等来表示。指定目标微架构可让编译器生成可能在目标硬件上更快运行的机器代码,而不会限制硬件兼容性。
上图:Intel Core 2 微架构框图(来源)
{kind=link}
编译器允许用户以我们稍后将介绍的方式指定这些目标。Fuchsia 的构建系统能够以全局或按二进制文件的形式配置编译器。Fuchsia build 中现有的 CPU 定位实现存在一些缺点,此 RFC 旨在解决这些缺点:
arm64 的基准配置选择的是特定 CPU (Cortex-A53),而不是所用的 ISA 加功能。这会导致平台基准定义不明确。
由于缺乏在先技术,并且没有记录在案的政策或最佳实践,因此不清楚如何为此基准设置替换项。因此,Fuchsia 会构建所有内容,但会回退到基准,包括以明确在基准之外的硬件为目标的 build 配置。
这些缺点自 2016 年该 build 诞生以来就一直存在,在此之前,Fuchsia 所源自的在先技术中也存在这些缺点。当前系统旨在在第一台设备上搭载 Fuchsia(该设备恰好使用与当前平台 arm64 基准相同的微架构)。
最近的发展表明,是时候进行大刀阔斧的改革了。具体来说,除了以 Cortex-A53 为目标的 Astro 和 Sherlock 板配置之外,Fuchsia 现在还支持 Nelson 板配置 (Cortex-A55) 和 Atlas 板配置 (Intel Amber Lake)。不过,这些 build 目前未配置为利用基准与实际目标之间的差异。
此外,人们越来越希望改进平台硬件基准的定义或提高该基准。更清晰地定义基准配置和特定主板配置将有助于加快相关工作。另请参见:
为了应对当前和未来的挑战,此 RFC 建议对 build 中的 CPU 定位进行短期更改,并制定机制和政策来管理可预见未来的定位。
利益相关方
辅导员: cpu@google.com
审核者:
aaronwood@google.com- 系统程序集digit@google.com- Buildmcgrathr@google.com- 内核mvanotti@google.com- 安全性maniscalco@google.com- 内核phosek@google.com- 工具链travisg@google.com- 内核
已咨询:
由于提议的更改会影响平台的大部分内容,因此建议所有当事方自行指定为被咨询方。我尤其欢迎图形、媒体和 SDK 等团队提供反馈。
共同化:
此提案的重点内容已在 Fuchsia 的内核演进工作组中以 60 分钟的演示和公开讨论的形式进行了首次审核。
背景
编译时调整标志
Fuchsia 使用 clang 来编译 C/C++,同时还使用 gcc 持续构建和测试部分 Fuchsia 代码。这两种工具均提供以下标志:
-march:设置目标架构,例如 x86-64-v2(根据 RFC-0073,这是我们当前的 x64 基准)或 ARMv8-A。还可以选择指定其他架构功能,例如 +avx2 表示大于 x64 基准的 Intel Haswell 扩展。
-mtune:设置目标微架构,例如 cortex-a53 或 haswell。如果未使用 -mtune 和 -mcpu,则此值设置为 generic,以在一定范围的目标 CPU 之间实现平衡。
-mcpu:设置目标 CPU。接受与 -mtune 类似的值。对于 ARM CPU,这相当于将目标架构 (-march) 和目标微架构 (-mtune) 设置为与目标 CPU 相匹配。在 x86 上,这被视为已弃用,并且给定的值会重定向到 -mtune。
Rust 编译器提供以下 codegen 选项:
target-cpu:类似于 -mcpu,接受 cortex-a53 等值。
target-features:类似于 -march 特征,例如 +avx2。
当前状态
目前,所有 x64 build 均使用 -march=x86-64-v2 进行编译,而所有 ARM build 均使用 -mcpu=cortex-a53 进行编译。
存在一种通过名为 board_configs 的 GN 实参替换此配置的机制,该实参可被 .gni 文件中的板级配置替换。某些主板(尤其是 Astro 和 Sherlock)会手动指定上述 Cortex-A53 配置,不过目前这属于空操作,因为如果未定义任何替换项,则相同的配置也会作为后备配置。大多数主板配置都不会设置 board_configs。
调整目标和权衡
本部分简要回顾了设置 CPU 目标选项时需要考虑的不同目标,以及它们之间的一些权衡。
硬件兼容性:以 ISA 的早期修订版为目标可解锁与旧版硬件的兼容性。更高的兼容性是以无法使用可提升性能或安全性的新 ISA 功能为代价实现的。
性能:新指令可带来性能提升:更快速或更广泛的原子操作、加速的数学运算(FPU、SIMD 改进)、针对常见算法(例如 CRC 和 AES)的内置加速器。针对特定 CPU 调整机器代码可以生成在目标 CPU 上运行速度更快的代码,但通常会牺牲目标参数之外的其他 CPU 的性能。
与二进制文件大小的相互影响:在某些情况下,我们发现调优会增加二进制文件大小,例如,当针对按顺序执行处理器的指令调度优化增加寄存器压力时。
二进制文件大小:某些代码生成功能可通过特定 CPU 功能解锁。 例如,SIMD 支持自动矢量化,这与循环展开具有类似的效果,即生成速度更快但体积也更大的代码。针对按顺序执行的 CPU 调整的指令调度往往会生成更大的代码,因为它会添加更多调度限制,并可能增加寄存器压力和寄存器溢出。
其他代码生成功能可以减小二进制文件的大小。例如,用专用指令替换 CRC 和 AES 等算法可生成速度更快、体积更小的代码。
易于问题排查,即二进制多样性:针对不同 CPU 进行调整意味着随着时间的推移,会生成更多相同逻辑制品的二进制变体。例如,内核映像或预构建共享库的多种“变体”,每种都针对不同的目标进行了优化。这可能会使重现问题变得更加复杂,或者使 Fuchsia 暴露于在某些二进制变体中表现出来但在其他变体中未表现出来的问题。
公平竞争环境:除了基准 build 之外,Fuchsia 还可能提供针对特定 CPU 调整的 SDK 预构建件(系统映像、可重新分发的共享库)。这样做会使某些硬件选择比其他硬件选择具有更小的特权。合理假设是,创建针对某些 CPU 调整的 SDK 变体会在未来形成提供更多调整后的 SDK 发布渠道的预期。
简洁性:上述所有因素都会增加理解、开发和维护 Fuchsia 的复杂性。上述权衡取舍适用于以下情况:在面向特定硬件(例如面向特定用户硬件的 OTA 渠道的 build 和发布流水线)的 build 和分发渠道上,设置 CPU 定位选项以引入已可行的二进制多样性。在撰写本文时,还没有一种系统或软件包交付机制可以为不同的目标硬件提供多个二进制文件,并为正确的设备匹配正确的二进制文件。
提案
您可以在此更改中查看立即建议的修改。 下文将提供更多说明。
新的 arm64 基准硬件目标
arm64 的当前基准定义为以 Cortex-A53 为目标平台,如下所示:
-mcpu=cortex-a53
从技术上讲,这相当于根据一组精确的 Cortex-A53 特征来表达 -march,并针对 Cortex-A53 调整代码生成。
-march=<armv8a + Cortex-A53 features>
-mtune=cortex-a53
相反,基准将表达平台实际使用的 ARMv8-A ISA 功能,因此这些功能被假定为基准,然后针对通用 armv8a CPU 调整代码生成。
-march=armv8-a+simd+crc+crypto
-mtune=generic
对 -march 的影响实际上是无操作,因为移除 Cortex-A53 中支持但在代码中未使用的 -march 功能是无操作。
对 -mtune 的影响很小或没有影响,因为通用调优目标会针对典型的按序 ARMv8-A CPU(例如 Cortex-A53)进行优化。
对现有 x64 基准硬件目标的更改
x64 的当前基准为:
-march=x86-64-v2
上述 RFC-0073:将 x86-64 平台要求提升到 x86-64-v2 中已介绍过此主题。
这将更改为以下标志设置:
-march=x86-64-v2
-mtune=generic
这不会改变行为,因为如前所述,如果未指定 -mtune 和 -mcpu,-mtune 默认值为 generic。不过,添加 -mtune=generic 可明确此行为,并与 arm64 基准的定义保持一致。
特定于板的配置
在特定于平台的 .gni 文件(例如 //boards/ 中的文件)中指定的 board_configs 平台实参将继续用于通过特定于平台的配置来替换基准配置。
具体来说,使用 Cortex-A53 的主板配置(例如 astro.gni 和 sherlock.gni)将继续以 Cortex-A53 为目标,并保留当前的 -mcpu=cortex-a53 配置。
从本质上讲,此 RFC 采用的是以 Cortex-A53 为目标的现有 arm64 配置,并将其从平台基准提取到搭载此类 CPU 的 Astro 和 Sherlock 板的板级特定配置中。然后,此 RFC 以 ARM ISA 术语重新定义了平台基准,该基准可推广到许多硬件选择,而不是单个 ARM CPU。
此外,在 SDK 的未来版本中,还可以添加对针对不同架构变体(例如 ARM Cortex-A73 或 Intel AVX 扩展)的优化的支持。这值得进一步讨论,但超出了本文的范围。
内核配置
board_configs 实参将不再应用于内核映像。原因如下:
需要在代码生成时了解的更新指令或其他 CPU 功能目前对内核没有好处。
基于微架构的内核代码调优无法带来足以抵消增加二进制多样性和复杂性的好处。
内核可以继续提供有关受支持硬件功能的信息,例如通过 zx_system_get_features 系统调用。
此外,内核仍然可以利用一些较新的硬件功能,例如 64kB 内存页,这些功能不需要生成不同的代码,只需在运行时查询这些功能是否存在即可。如果引入了需要特定于主板的配置的新功能(例如此功能),则可以轻松引入定义关联标志的新实参 kernel_board_configs。
向后兼容性
此 RFC 中提出的立即变更不会提高 Fuchsia 的最低硬件要求,因此不会影响向后兼容性。如果未来更改会提高最低要求,那么此 RFC 倡导的政策可能会有所帮助。
安全注意事项
Fuchsia 使用或打算使用多项可提高安全性或支持使用清理器(从而提高安全性)的 CPU 功能。这些通常不受此处讨论的编译器标志控制,因此无需担心。
值得注意的是:
- 用户空间最高字节忽略(另请参阅 RFC-0143)在整个 AArch64 中普遍受支持。
- 改进了清理器支持的新指令(例如 ARM MTE)或通过确保控制流完整性来缓解漏洞(例如指针身份验证和分支目标标识或 Intel 控制流强制技术)的新指令位于 NOP 空间中,因此向后兼容(从旧 CPU 将它们作为 NOP 执行的意义上来说)。因此,使用这些指令不需要提高平台或 SDK 变体的最低支持 ISA。
测试
正确性:对 CPU 定位的更改绝不应影响正确性。 此问题已通过持续的提交前和提交后测试进行验证。目前的系统足以确保这一点。
性能:更改 CPU 定位条件通常会对性能产生影响。Fuchsia 的 Perfcompare 系统将用于验证任何此类更改,这与之前的情况一样。
二进制文件大小:CPU 目标平台的更改通常会以细微的方式影响二进制文件大小。具体而言,Fuchsia 目前最密切地跟踪 Astro 映像的大小,因为这是我们拥有的限制最多的目标。立即进行的更改不会使此大小发生倒退。受未来变更影响的特定商品图片可由相应商品定义的所有者进行审核,并仔细考虑权衡取舍。
缺点、替代方案和未知因素
CPU 定位在有时会相互冲突的目标之间存在许多工程和业务权衡。上文已对这些内容进行了回顾。未来会改变这些权衡取舍的变更,以及未来的调整机会和注意事项,均不在本 RFC 的讨论范围内。