
| RFC-0196:FIDL 大消息 | |
|---|---|
| 状态 | 已接受 |
| 区域 |
|
| 说明 | 支持通过 FIDL 协议发送大型消息。 |
| 问题 | |
| Gerrit 更改 | |
| 作者 | |
| 审核人 | |
| 提交日期(年-月-日) | 2022-06-28 |
| 审核日期(年-月-日) | 2022-10-27 |
摘要
目前,FIDL 语言将基于 Zircon 的传输(如通道和套接字)的消息大小限制为 64KiB。本文档提出了一种高级设计,用于处理任意大小的消息,即使这些消息超出了其底层传输的最大消息字节限制。为此,我们提升了类似于成熟现有模式的解决方案(即使用 fuchsia.mem.Data),使其成为一流的自动推断 FIDL 语言支持。
设计初衷
目前,通过网络发送的所有 FIDL 消息的大小都限制为 ZX_CHANNEL_MAX_MSG_BYTES,目前相当于 64KiB,源自可通过 Zircon 渠道发送的消息的最大大小。超出此限制的消息无法进行编码。
目前,解决此问题的常见方法是通过 zx.handle:VMO(或 fuchsia.mem.Data)以 blob 形式发送任意大小的数据,而底层 VMO 本身包含要发送的数据 blob。通常,这些 blob 包含最终用户希望以 FIDL 表示和编码/解码的结构化数据,但最终用户无法做到这一点,只能被迫自行进行手动转换。目前,fuchsia.git 中有大量使用这些封装容器类型的情况。
缺少对大型消息的支持会导致一些问题。其中最重要的是,很少需要发送大型消息但技术上能够发送大型消息的协议会导致大量 bug。例如,非常大的网址或在 WiFi 扫描期间生成的非常大的网络列表。所有需要采用 :MAX 大小的 vector 或 string 的 API 都容易出现此问题,以及其他极端情况,例如只有极少数情况下才会填充所有字段的 table 布局。在一般情况下,任何需要接受用户数据(以无法证明小于 64KiB 的消息形式)的内容都可能会受到此故障模式的影响。
通过 VMO 发送无类型的数据 blob 不符合人体工程学,因为它会丢失所有类型信息,而这些信息必须在接收端手动重建。用户无法利用 FIDL 来描述数据形状并抽象出编码->发送->解码->调度流水线,而是必须自行对消息进行编码,将其打包到另一个 FIDL 消息中,然后在另一端反向重复此过程。例如,ProviderInfo
API 具有子类型 InspectConfig 和 InspectSource,目前分别由 fuchsia.mem.Buffer 和 zx.handle:VMO 表示,但表示可由 FIDL 描述和处理的结构化数据。
使用 zx.handle:VMO 或 fuchsia.mem.Data 会导致仅包含数据的 FIDL 类型被迫携带 resource 修饰符。这会对绑定 API 产生下游影响,导致 Rust 等语言中生成的类型无法派生 Clone 特征,即使它们应该能够派生。
因大型消息支持不足而导致的 bug 和人体工程学问题非常普遍。在撰写此 RFC 期间进行的一项调查显示,过去和现在至少有 30 个案例表明,更强大的大型消息支持功能本可以帮助 FIDL 用户。
利益相关方
辅导员:hjfreyer@google.com
审核者:abarth@google.com、chcl@google.com、cpu@google.com、mseaborn@google.com、nickcano@google.com、surajmalhotra@google.com
咨询对象:bprosnitz@google.com、geb@google.com、hjfreyer@google.com、jmatt@google.com、tombergan@google.com、yifeit@google.com
社会化:五个团队(组件解析器、DNS 解析器、驱动程序开发、WLAN SME 和 WLAN 政策)已使用此设计审核原型:
- 组件问题解决者:geb@google.com
- DNS 解析器:dhobsd@google.com
- 驱动程序开发:dgilhooley@google.com
- WLAN 政策:nmccracken@google.com
- WLAN SME:chcl@google.com
此外,我们还采访了 30 多位现有 fuchsia.mem.Data 和 fuchsia.mem.Buffer 类型的用户,以征求有关设计反馈和使用情形适用性的意见。
设计
本文档中的关键字“必须”“不得”“必需”“会”“不会”“应”“不应”“建议”“可以”和“可选”应按照 IETF RFC 2119 中的描述进行解释。
消息溢出是传输级问题。对于什么是大型消息,以及如何最好地处理符合该定义的消息,在 Zircon 渠道、驱动程序框架、Overnet 等之间存在很大差异。这意味着,将特定方法请求或响应称为“大”并非抽象的说法:对于该方法所属的协议,“大”必须始终有一个明确的定义。
以下内容指定了消息如何声明“我相对于承载我的传输的预期大小而言很大,因此需要特殊处理”。此声明必须在以下情况下清晰可辨:在 *.fidl 文件中指定协议的接口定义时,以及在运行时针对任何实际溢出的给定消息实例。
具体来说:在此设计之前,发送者可能会发送一条在其他方面完全有效的消息,但该消息超出了底层传输的最大消息字节限制,从而导致令人意外且难以调试的 PEER_CLOSED 运行时故障。进行这些更改后,fidlc 编译器将静态检查载荷类型是否可能大于传输的最大消息字节限制,如果可能,则会生成特殊的“溢出”处理代码来解决此问题。此模式可为大型消息启用辅助运行时消息传送机制,其中使用无界限的边信道(对于 Zircon 信道,为 VMO)来存储消息的内容。此新消息传递路径完全在生成的绑定代码的“内部”添加,从而保持 API 和 ABI 兼容性。FIDL 方法实现者现在可以放心地使用,因为没有可分配的消息会因达到任意字节大小限制而触发 PEER_CLOSED。
电汇格式变更
在 FIDL 事务性消息标头的动态标志部分中添加了一个新位,称为 byte_overflow 标志。此标志翻转时,表示当前持有的消息仅包含消息的控制平面,消息的其余部分存储在单独的可能不连续的缓冲区中。
此单独缓冲区的位置以及访问方式取决于传输。如果 byte_overflow 标志处于有效状态,则传输中的控制平面消息必须包含 16 字节的事务性消息头,后跟一个额外的 16 字节附录消息,用于描述大型消息的大小。这意味着,此消息必须正好为 32 字节:默认 FIDL 消息头,后跟一个所谓的 message_info 结构体,其中包含三项数据:一个用于标志的 uint32、一个预留的 uint32(用于在排除溢出缓冲区的情况下指定附加到消息的句柄数量),以及一个用于指示 VMO 本身数据大小的 uint64:
type MessageInfo = struct {
// Flags pertaining to large message transport and decoding, to be used for
// the future evolution and migration of this feature.
// As of this RFC, this field must be zeroed out.
flags uint32;
// A reserved field, to be potentially used for storing the handle count in
// the future.
// As of this RFC, this field must be zeroed out.
reserved uint32;
// The size of the encoded FIDL message in the VMO.
// Must be a multiple of FIDL alignment.
msg_byte_count uint64;
};
由于需要生成一个额外的句柄来指向溢出缓冲区,因此大型 FIDL 消息可能只有 63 个附加句柄,而不是通常的 64 个。这种行为不够优雅,会让用户感到意外,并且只会通过运行时错误进行报告。我们承诺开发 内核改进,以在未来修复这一棘手的问题,从而弥补这一不幸的极端情况。
byte_overflow 标志必须占用动态标志位数组中的第 6 位(即倒数第二位)。位 #5 预留给可能在未来使用的 handle_overflow 位,不过此位目前未使用。
此位不得用于其他用途。
运行时要求
有多种情况,如果在解码期间违反了这些情况,必须导致 FIDL 传输错误,并立即关闭通信渠道。如果设置了 byte_overflow 标志,则控制平面消息的大小必须正好为 32 字节(如上所述),消息正文必须通过其他某种介质传输。
对于 zircon 通道传输,字节溢冲缓冲区的介质必须是 VMO。这意味着控制平面消息上的随附句柄数量必须至少为 1。相应最后一个句柄所指向的内核对象必须是 VMO,并且接收方从该 VMO 读取的字节数必须等于 message_info 结构的 msg_byte_count 字段的值。如果已知消息有界,则此值必须小于或等于相应载荷的静态推导最大大小。
消息发送者必须通过 zx_vmo_create 系统调用铸造新的 VMO,然后立即通过 zx_vmo_write 系统调用填充消息正文。它们必须确保表示溢出 VMO 的句柄不具有 ZX_RIGHT_WRITE 权限。
在接收端,消息的接收者必须使用 zx_vmo_read 读取其保存的数据。因此,通过 zircon 渠道发送的常规 FIDL 消息只需要两次系统调用(发送方为 zx_channel_write_etc,接收方为 zx_channel_read_etc),而字节溢出消息则需要更多次系统调用(发送方为 zx_channel_write_etc、zx_vmo_create 和 zx_vmo_write,接收方为 zx_channel_read_etc、zx_vmo_read 和 zx_handle_close)。虽然这种惩罚非常严厉,但未来的优化(例如改进 zx_channel_write_etc API)可能会挽回部分费用。消息接收器不得尝试写入接收到的溢出 VMO。
代码生成变更
对于任何最大字节数可能大于其协议传输限制的载荷消息,FIDL 绑定实现必须生成溢出处理程序。为此,FIDL 消息大致可分为三类:
- 有界: 最大累计字节数始终已知的消息。
此类别包含大多数 FIDL 消息。对于此类消息,绑定生成器必须使用计算出的消息最大字节数来确定是否包含在编码时设置
byte_overflow标志的功能,以及是否在解码时检查该标志。具体而言,如果最大累计字节数大于协议传输的限制(对于 Zircon 信道为 64KiB),则生成的代码中必须包含在编码时设置byte_overflow标志的功能和强制解码时标志检查功能;否则,生成的代码中不得包含这些功能。 - 半有界: 最大累计字节数仅在编码时已知的消息。此类别包括任何原本会受到限制的消息,但以传递方式包含
flexible union或table定义的消息除外。对于此类消息,绑定生成器必须使用计算出的消息最大字节数来确定是否包含在编码时设置byte_overflow标志的功能,但此标志必须始终在解码时进行检查。 - 无界: 最大累计字节数按定义始终未知的消息。此类别包括以传递方式包含递归定义或无界
vector的任何消息。对于此类消息,生成的绑定代码必须始终包含在编码时设置byte_overflow标志的功能,并且必须始终在解码时检查该标志。
@transport("Channel")
protocol Foo {
// This request has a well-known maximum size at both encode and decode time
// that is not larger than 64KiB limit for its containing transport. The
// generated code MUST NOT have the ability to set the `byte_overflow` on
// encode, and MUST NOT check it on decode.
BoundedStandard() -> (struct {
v vector<string:256>:16; // Max msg size = 16+(256*16) = 4112 bytes
});
BoundedStandardWithError() -> (struct {
v vector<string:256>:16; // Max msg size = 16+16+(256*16) = 4128 bytes
}) error uint32;
// This request has a well-known maximum size at both encode and decode time
// that is greater than the 64KiB limit for its containing transport. The
// generated code MUST have the ability to set the `byte_overflow` on encode,
// and MUST check it on decode.
BoundedLarge() -> (struct {
v vector<string:256>:256; // Max msg size = 16+(256*256) = 65552 bytes
});
BoundedLargeWithError() -> (struct {
v vector<string:256>:256; // Max msg size = 16+16+(256*256) = 65568 bytes
}) error uint32;
// This response's maximum size is only statically knowable at encode time -
// during decode, it may contain arbitrarily large unknown data. Because it
// is not larger than 64KiB at encode time, the generated code MUST NOT have
// the ability to set the `byte_overflow` on encode, but MUST check for it on
// decode.
SemiBoundedStandard(struct {}) -> (table {
v vector<string:256>:16; // Max encode size = 32+(256*16) = 4128 bytes
});
SemiBoundedStandardWithError() -> (table {
v vector<string:256>:16; // Max encode size = 16+32+(256*16) = 4144 bytes
}) error uint32;
// This response's maximum size is only statically knowable at encode time -
// during decode, it may contain arbitrarily large unknown data. Because it
// is larger than 64KiB at encode time, the generated code MUST have the
// ability to set the `byte_overflow` on encode, and MUST check for it on
// decode.
SemiBoundedLarge(struct {}) -> (table {
v vector<string:256>:256; // Max encode size = 32+(256*256) = 65568 bytes
});
SemiBoundedLargeWithError(struct {}) -> (table {
v vector<string:256>:256; // Max encode size = 16+32+(256*256) = 65584 bytes
}) error uint32;
// This event's maximum size is unbounded. Therefore, the generated code MUST
// have the ability to set the `byte_overflow` on encode, and MUST check for
// it on decode.
-> Unbounded (struct {
v vector<string:256>;
});
};
ABI 和 API 兼容性
此设计一旦完全推出,将完全兼容 ABI 和 API。它始终是 ABI 安全的,因为任何将之前有界限的载荷转换为无界限或半界限的更改(例如将 struct 更改为 table,或更改 vector 大小界限)本身就是破坏 ABI 合规性的更改。
对于无界或半有界载荷,无论大小如何,在消息解码期间始终会检查 byte_overflow 标志。这意味着,在连接的一端编码的任何消息都可以在另一端解码,即使演变添加了未知数据,导致消息从解码器的载荷类型视图来看出乎意料地大也是如此。
在推出期间的中间阶段,连接的一方可能具有了解大型消息的 FIDL 绑定,而另一方则没有,此时大型消息将无法解码。这与目前的情况类似,此类消息会在编码期间失败,不过现在失败会稍微远离来源。
由于大多数会发送大型消息的 API 已经实施了协议级缓解措施(例如分块),因此中间推出期间的解码失败风险被认为较低。主要风险在于,协议开始通过现有方法发送现在允许的大消息。此类协议应优先引入新的、能够处理大型消息的方法。
设计原则
此设计遵循了以下几项关键原则。
用多少,付多少
FIDL 语言的一项主要设计原则是按需付费。本文档中介绍的大型消息功能旨在秉持这一理想。
使用有界载荷的方法不会因本 RFC 的存在而降低性能。使用半有界或无界载荷但发送的消息不超过协议传输的字节数限制的方法,只需在接收端支付单个位标志检查的费用。只有实际使用大型消息溢出缓冲区的消息才会受到性能影响。
不需要大型消息支持的用户(即,很可能在 FIDL 中表达的大多数方法/协议)无需支付任何费用,无论是运行时性能成本还是编写 FIDL API 时产生的脑力开销。
不迁移数据
现在,大型消息已在所有可能使用它们的载荷中启用,无需迁移现有的 FIDL API 或其客户端/服务器实现。之前会导致 PEER_CLOSED 运行时错误的情况现在可以正常运行。
量身定制的运输服务
此设计可灵活满足现有和推测性不同传输的需求。例如,只要翻转 byte_overflow 位,并且传输层知道如何对包含溢出的数据包进行排序,就可以实现通过网络发送多数据包消息等惯例。
实现
此功能将通过实验性 fidlc 标志推出。然后,每个绑定后端都将进行修改,以处理此 RFC 针对明确指定实验性标志的输入所指定的大型消息。一旦该功能被视为稳定,相应标志就会被移除,从而允许常规使用。
此属性不应需要额外的 fidlc 支持,因为它只会将执行溢出检查所需的信息传递给将学习如何支持大型消息的后端选择。
在此 RFC 之前,绑定普遍将编码/解码缓冲区放置在堆栈上。今后,建议绑定应继续对未翻转 byte_overflow 标志的消息执行此行为。对于此类消息,绑定应在堆上分配。
性能
在略微自定义的场景中,可以使用内核微基准来估计所提议的传送方法的性能影响,方法是针对以下 B 值(16KiB、32KiB、64KiB、128KiB、256KiB、512KiB、1024KiB、2048KiB 和 4096KiB),将两种情况(发送大小为 B 的单通道消息与发送 16 字节通道消息和发送大小为 B - 16 的 VMO 的总和)相加并进行比较。
清单 1:表格显示了以 16 字节的渠道消息和大小为 B - 16 的 VMO 发送 B 字节数据时,而不是以大小为 B 的渠道消息发送数据时,估计的1 传送时间性能“税”。
| 邮件大小 / 策略 | 仅限频道 | Channel + VMO | VMO 使用税 |
|---|---|---|---|
| 16KiB | 2.5 微秒 | 5.9 微秒 | 136% |
| 32KiB | 4.5 微秒 | 7.7 微秒 | 71% |
| 64KiB | 7.9 微秒 | 13 微秒 | 65% |
| 128KiB | 16.5 微秒 | 23.3 微秒 | 41% |
| 256KiB | 35.8μs | 54.4μs | 52% |
| 512KiB | 71.3 微秒 | 107.4 微秒 | 51% |
| 1024KiB | 157.0μs | 223.4 微秒 | 42% |
| 2048KiB | 536.2 微秒 | 631.8 微秒 | 18% |
| 4096KiB | 1328.2μs | 1461.8μs | 10% |
清单 2:图表,显示了以 16 字节的通道消息和大小为 B - 16 的 VMO 交付 B 字节的数据时,与以大小为 B 的通道消息交付数据相比,估计的交付时间性能“税”。
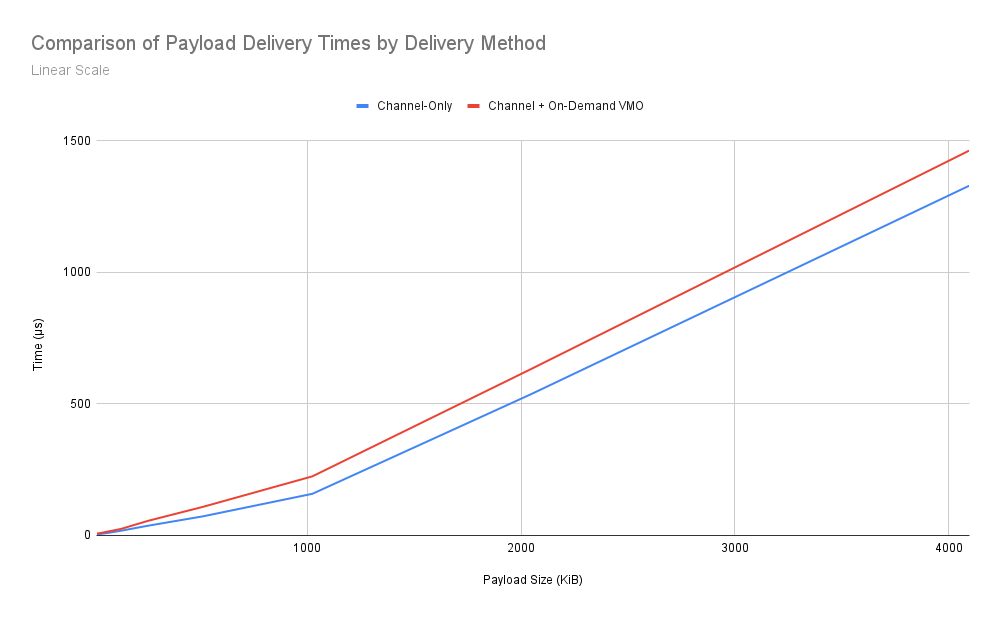
清单 3:以线性比例比较了以下两种情况下的传送时间性能:将 B 字节的数据作为 16 字节的通道消息传送,以及将 B 字节的数据作为大小为 B - 16 的 VMO 传送,而不是作为大小为 B 的通道消息传送。
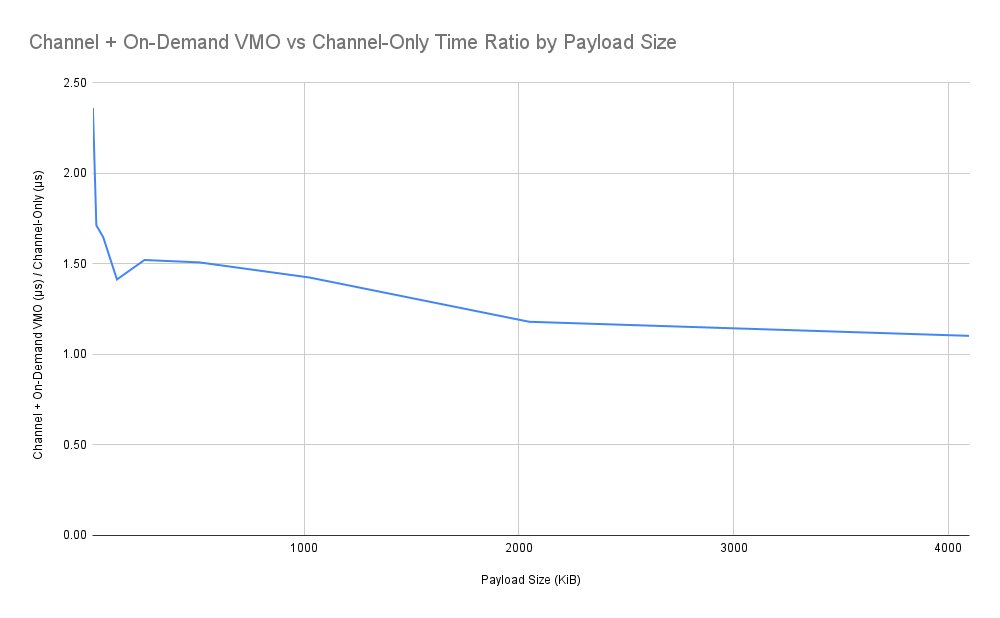
这些数据带来了一些有趣的发现。我们可以看到,数据大小与交付时间之间的关系大致呈线性。这两种方法在性能方面显然存在差距,不过有趣的是,随着消息大小的增加,差距似乎在缩小。
综合考虑这些结果,我们可以使用此设计中指定的方法来模拟发送 FIDL 大消息的预期性能。我们可以预期,在给定大小下,所谓的“VMO 税”与使用相同大小的普通旧频道消息(如果允许)相比,端到端传送时间大约会增加 20-60%。有趣的是,随着发送的消息大小增加,百分比差距略有缩小,这表明 VMO 税费相对于载荷大小的增长略低于线性增长。
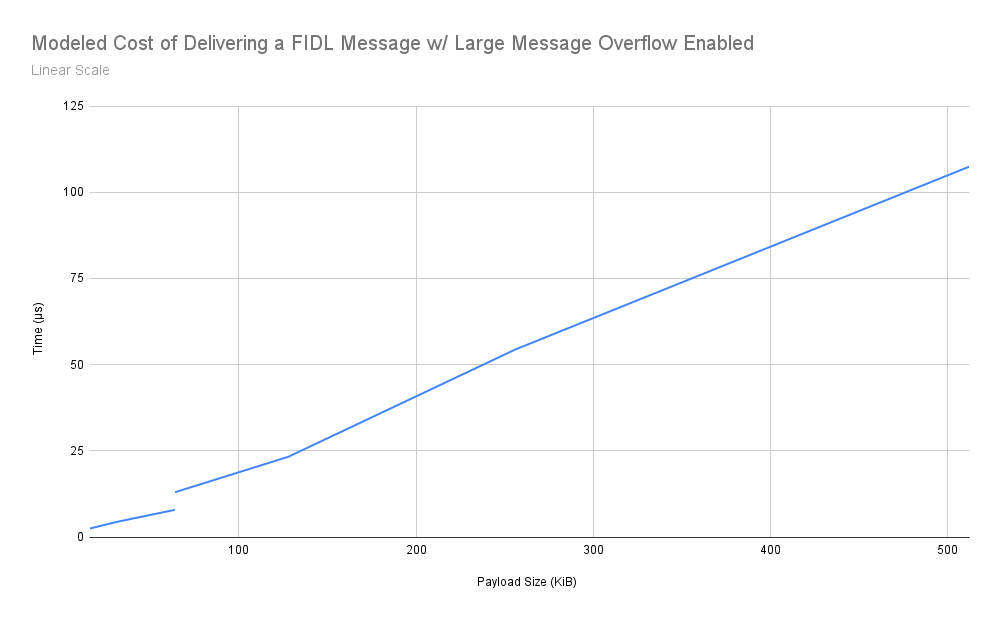
清单 4:表格,显示了本文档中所述设计的模型化送货时长效果。
| 邮件大小 / 策略 | 仅限频道 | Message + VMO |
|---|---|---|
| 16KiB | 2.5 微秒 | -- |
| 32KiB | 4.5 微秒 | -- |
| 64KiB | 7.9 微秒 | 13 微秒 |
| 128KiB | -- | 23.3 微秒 |
| 256KiB | -- | 54.4μs |
| 512KiB | -- | 107.4 微秒 |
| 11024KiB | -- | 223.4 微秒 |
| 2048KiB | -- | 631.8 微秒 |
| 4096KiB | -- | 1461.8μs |
商品详情 5:线性比例图,显示了本文档中所述设计的模型化送货时长性能。请注意,在从常规消息切换到大型消息时,64KiB 处存在不连续性。
工效学设计
此项更改极大地改进了人体工程学,因为现在基本上所有 zx.handle:VMO、fuchsia.mem.Buffer 和 fuchsia.mem.Data 的当前用例都可以使用一流的 FIDL 概念来描述。下游绑定代码也会受益,因为之前必须通过网络以无类型方式发送的数据现在可以使用常规 FIDL 途径进行处理。从本质上讲,为大型消息生成的 FIDL API 现在与其非大型消息对应项完全相同。
向后兼容性
这些更改将完全向后兼容。现有 API 的语义略有变化(从每个消息限制为 64KiB 变为无限制),但由于这是放宽了之前的限制,因此不会影响任何现有 API。
安全注意事项
这些更改对安全性的影响很小。使用 fuchsia.mem.Data 结构已可实现提升为“第一类”状态的模式,并且未观察到对安全性的负面影响。不过,务必确保在所有情况下安全地实现该功能。
此设计还会扩大与 FIDL 协议相关的拒绝服务攻击风险。之前,发送分配大量内存(导致接收方崩溃)的 VMO 的攻击途径仅适用于明确发送包含类型的 fuchsia.mem.Data/fuchsia.mem.Buffer/zx.handle:VMO 的协议。现在,包含至少一种具有无界或半界载荷的方法的所有协议都面临此风险。目前,这被认为是可容忍的,仅仅是因为 Zircon 中存在许多拒绝服务攻击向量。我们将在本设计范围之外寻求更全面的解决方案来解决此问题。
此设计未强制要求在接收端检查 ZX_INFO_VMO,从而引入了额外的拒绝服务攻击向量。这样一来,由分页器支持的 VMO 就可以通过永远不提供其承诺提供的页面来导致服务器挂起。实际上,意外发生这种情况的风险较低,因为只有相对较少的程序使用分页器支持的 VMO 机制。与上述推理类似,在未来的设计中实现更全面的解决方案之前,这种拒绝服务攻击向量是可以容忍的。
隐私注意事项
一项重要的隐私注意事项是,消息发送者必须确保他们为每条基于 VMO 的消息使用新创建的 VMO。它们不得在消息之间重复使用 VMO,否则可能会泄露数据。需要绑定才能强制执行这些限制。
测试
标准 FIDL 测试策略(针对 fidlc 的单元测试和针对下游及绑定输出的黄金标准)将进行扩展,以适应大型消息使用情形。
文档
需要更新 FIDL 有线格式规范,以描述本文档引入的有线格式更改。
缺点、替代方案和未知因素
缺点
这种设计存在许多缺点。虽然这些缺点被认为是次要的,尤其是相对于无所作为或实施所考虑的替代方案的成本而言,但仍然值得指出。
性能悬崖
如性能探索中所述,此 RFC 中描述的策略会在 ZX_CHANNEL_MAX_MSG_BYTES 截止点处导致性能“悬崖”,在该点处,用户开始为发送较大尺寸的消息支付“税费”。具体而言,比 64KiB 大 1 字节的消息的接收时间比正好 64KiB 的消息长大约 60%(13μs 而不是 7.9μs)。虽然这种陡降并不理想,但相对较小,并且可以通过未来的内核更改来改善。
拒绝服务攻击
现在,任何具有至少一种采用无界或半界载荷的方法的协议都容易受到内存方面的拒绝服务攻击:恶意攻击者可以在 message_info 结构的 msg_byte_count 字段中发送具有非常大值的溢出消息,并附加类似大小的 VMO。然后,接收方将被迫分配足够的内存来处理此载荷,如果恶意载荷足够大,则必然会崩溃。
如上文列举的安全注意事项中所述,这是一个非常真实的风险,此设计会推迟解决此风险,直到将来找到更全面的解决方案。
处理溢出边缘情况
此设计并不能完全消除因消息意外过大而在运行时遇到意外 PEER_CLOSED 的可能性:包含超过 64 个句柄的常规消息或包含超过 63 个句柄的大消息仍会触发错误状态。目前,这被认为是可接受的,因为作者知道在实践中没有使用此类载荷。此边缘情况可在需要时处理。message_info 结构中包含 reserved 字段,可确保在未来设计句柄溢出支持时具有灵活性。
依赖于上下文的消息属性
byte_overflow 和标志将是第一个对不同传输方式具有不同含义的标头标志(可争议的例外是静态标志,具体取决于我们是否将静态 FIDL 视为“传输方式”)。这带来了一些不确定性:仅仅查看线编码的 FIDL 事务性消息而不了解是哪个传输发送的,可能不再完全足以处理该消息。现在,我们需要一个“预处理”步骤,在此步骤中,我们会根据标头标志和消息的发送所用传输方式,执行特殊程序来组装完整的消息内容。例如,在 Zircon 渠道传输上溢出的非句柄携带消息现在会在其句柄数组中获取句柄,而溢出的 fdf 消息可能不会。
被拒的替代方案
在设计此 RFC 期间,我们考虑了大量替代解决方案。下面列出了最有趣的提案。
提高了 Zircon 消息大小限制
对于大型消息,最迫切的需求是通过 zx.channel 传输,而该传输目前的消息大小限制为 64KiB。一个显而易见的解决方案是提高此限制。
这么做会产生几个问题。首先,它只是将问题推迟到以后。但由于 ABI 破坏性内核限制迁移(例如上述迁移)并非易事,因此情况变得复杂起来,因为需要进行仔细管理,以确保在限制提高后编译的二进制文件不会意外发送比在限制提高前编译的二进制文件所能处理的更多数据。
许多 FIDL 实现还会根据该限制做出有用的假设。某些绑定(例如 Rust 的绑定)针对接收到的消息采用“猜测并检查”分配策略。它们会分配一个较小的缓冲区并尝试 zx_channel_read_etc。如果该系统调用因 ZX_ERR_BUFFER_TOO_SMALL 而失败,则返回实际消息大小。这样,绑定便可分配足够大的缓冲区并重试。
而其他绑定(例如 C++ 的绑定)则会不加考虑地始终为传入消息分配 64KiB 的内存,从而避免了多次系统调用的可能性,但代价是分配的内存更大。后一种策略无法扩展到任意大的消息。
最后,使用 VMO 是一种经过充分测试的解决方案:多年来,它一直是大型消息传输的首选方案,通过 fuchsia.mem.Data 和 fuchsia.mem.Buffer 类型实现。提高内核限制是一种不太可靠的解决方案,存在更多潜在的未知问题。
使用 zx_vmar_map 而非 zx_vmo_read
对当前设计的一种优化是让 FIDL 编码器使用 zx_vmar_map 直接从 VMO 缓冲区读取数据。这种方法存在两个问题。
主要问题在于此方法不安全,需要修改内核原语才能解决。问题在于,映射内存会造成这样一种情况:消息发送方可能会在接收方读取消息时修改消息内容,从而产生 TOCTTOU 风险。读取器可以直接尝试从映射的且可能可变的 VMO 读取数据,而无需先进行复制,但即使执行了防御性复制,也很难安全地执行此操作。通过 zx_vmo_create_child 调用强制执行 VMO 的不可变性,可以缓解这些安全风险,但代价是额外的系统调用和最坏情况下的复制开销。
内存映射的性能方面存在其他问题,并且有线 C++ 绑定存在复杂情况(例如,需要决定何时释放内存),因此此选项不太适合。
分包
此处的想法是将非常大的消息拆分为许多消息,每个块的大小不超过 64KiB,然后在另一端将它们组装起来。事务性消息标头会包含某种延续标志,用于指明是否预期后续会跟进“更多数据”。这种方式的优势在于内置了流控制,并且对于使用标准库中包含流基元的语言的程序员来说非常熟悉。
这种方法的缺点是,在消息不易分块的情况下,它无法提供明显的帮助。它也复杂得多:当多个线程发送时,大量令人困惑的部分消息块会阻塞传输,需要在另一端重新组装。
最令人担忧的是,此策略存在拒绝服务攻击风险,仅通过新的内核原语或未来添加有界协议无法解决此风险:恶意或有 bug 的客户端可能会发送非常长的消息数据包流,但随后未能发送“关闭”数据包。接收方在等待最后一个数据包时,必须将所有剩余的数据包都保存在内存中,这使得客户端可以在服务器上“预订”可能无限的持久内存分配。当然,也有一些方法可以解决这个问题,例如超时和政策限制,但这很快就会演变成通过 FIDL 重新实现 TCP。
显式溢出
本文档中提出的设计方案抽象出了如何从最终用户处传送大型消息的细节。用户只需定义其载荷,绑定会在后台完成其余工作。
另一种设计方案是允许用户以声明方式指定何时专门使用 VMO,无论是按载荷还是按载荷成员。从本质上讲,这只需要修改 FIDL 语言,以便为 fuchsia.mem.Data 提供更清晰的拼写。
现有设计以牺牲确定性和精细控制为代价,换取了性能和 API 兼容性的提升,这被认为是值得的。
仅允许值类型
此设计的早期版本建议仅针对值类型启用 overflowing。这里的理由很简单:现有使用情形中没有一个是资源类型,并且单个 FIDL 消息不太可能需要一次发送超过 64 个句柄,因此我们认为此问题优先级较低。
在为 fuchsia.component.resolution 库设计此解决方案的原型时,我们发现了一个问题。某些方法已使用表格来携带其载荷,与其全面替换方法,不如扩展表格以逐步弃用 fuchsia.mem.Data。具体而言:
// Instead of adding a new method to support large messages, the preferred
// solution is to extend the existing table and keep the current method.
protocol Resolver {
Resolve(struct {
component_url string:MAX_COMPONENT_URL_LENGTH;
}) -> (resource struct {
component Component;
}) error ResolverError;
};
type Component = resource table {
// Existing fields - note the two uses of `fuchsia.mem.Data`.
1: url string:MAX_COMPONENT_URL_LENGTH;
2: decl fuchsia.mem.Data;
3: package Package;
4: config_values fuchsia.mem.Data;
5: resolution_context Context;
// Proposed additions for large message support.
6: decl_new fuchsia.component.decl.Component;
7: config_values_new fuchsia.component.config.ValuesData;
};
这些方法带来了一个有趣的问题:虽然在实践中,载荷较大和携带句柄的情况是互斥的,但 fidlc 编译器并不知道这一点。从它的角度来看,这些只是资源类型。虽然可以想象出一些权宜之计来教导编译器了解此特定情况,但我们认为,在开发出更合适的内核原语之前,只允许大型消息使用 63 个句柄会更简单。
overflowing 修饰符
此设计的早期迭代版本允许用户在定义其协议方法的 FIDL 中设置 overflowing 存储分区,如下所示:
// Enumerates buckets for maximum zx.channel message sizes, in bytes.
type msg_size = flexible enum : uint64 {
@default
KB64 = 65536; // 2^16
KB256 = 262144; // 2^18
MB1 = 1048576; // 2^20
MB4 = 4194304; // 2^22
MB16 = 16777216; // 2^24
};
@transport("Channel")
protocol Foo {
// Requests up to 1MiB are allowed, responses must still be less than or equal
// to 64KiB.
Bar overflowing (BarRequest):zx.msg_size.MB1
-> (BarResponse) error uint32;
};
不过,由于它提供了多种选项,但没有明确的指导来帮助用户选择,因此最终被认为过于复杂和微妙。最终,大多数用户可能都希望回答一个简单的“是/否”问题(“我是否需要大消息支持?”),而不是担心特定限制带来的细微性能影响。
我们还考虑了使用单独的 overflowing 关键字(不含任何分桶)的替代方案,以便向用户明确表明他们接受的 API 性能可能较差。最终,我们认为性能差距不够大,而且无论如何都可以缩小,因此不值得在语言本身中添加此类标注。
未来可能开展的工作
虽然启用大型消息功能并非严格要求,但有一些配套措施可作为此项工作的重要补充和优化。
内核变更
有许多可能的内核更改虽然不在实现此功能的关键路径上,但无疑有助于减少系统调用抖动并优化性能。大型消息面向用户的 API 在实现这些额外的优化时不应发生变化。fuchsia.mem.Data 的大多数现有用户对延迟并不特别敏感(否则他们就不会使用 fuchsia.mem.Data!),因此修改内核的主要用途是提高在 FIDL 中启用大型消息后出现的紧急用例的性能。
一流的流
每当出现大型消息使用情形时,人们总是会问:“难道不能通过在 FIDL 中实现一流的流来解决这个问题吗?”为了回答任何特定情况下的这个问题,我们需要考虑两个有用的属性,大量数据可以根据这两个属性进行分类:分块性和可附加性。
可分块性是指相关数据是否可以拆分为有用的子部分,更重要的是,数据接收方是否可以仅对子集执行有用的工作。从本质上讲,这是 T 类型的数据与 vector<T> 或 array<T> 类型的数据之间的区别,其中列表的部分视图仍然可操作。分页列表可分块,而用于排序的项列表则不可分块。同样,树也是不可分块的:通常,人们无法对树的(任意)部分做太多事情。
可附加性是指数据在发送后是否可以修改。 可附加 API 的经典示例是 Unix 管道:在从读取端读取数据的同时,很可能(甚至可以预期)会从写入端添加更多数据。发送后可添加数据的数据是可附加的。在发送时不可变的数据(即使采用列表形式)则不是。
清单 6:一个矩阵,其中列出了所有可能的块化和附加组合的首选大数据处理策略。
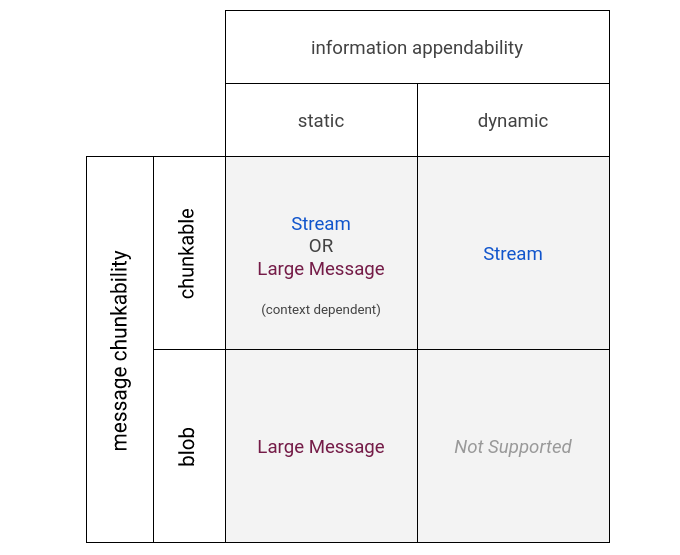
这两个区别很有用,因为将它们组合在一个矩阵中可以很好地指导我们选择更适合的大型消息或流。
对于静态 blob(例如数据转储、B 树或大型 JSON 字符串),用户不希望进行流式传输:对他们来说,这是一个单条消息,而它对于 FIDL 来说过大(或至少可能过大)这一事实是一种意外的复杂性,通常与他们的担忧相去甚远。在这种情况下,他们希望有一种方法来告诉系统“尽一切努力通过网络传输此消息,但不要传输过大的消息”。一旦数据已具体化到设备上某个位置的内存中,再将其零散地在进程之间移动就没什么意义了。
对于可分块的动态数据结构(例如网络数据包流),流是显而易见的选择(名称中就包含“流”一词!)。用户已经制作了自定义迭代器来处理这种情况,编写了用于处理在发送端设置流并在接收端干净地公开流的库,因此这似乎是第一类处理的理想候选对象。这也是一种非常自然的模式,在 FIDL 具有绑定的大多数语言(C++、Dart、Rust)中都具有强大的支持和程序员熟悉度。
对于可分块但大多静态的消息(例如列出连接到设备的外围设备的快照),该如何处理?将这些信息分块并将其作为流公开非常简单,但这样做是否有利并不明显:在许多公开此类信息的 API 中,作者将分页视为为了满足 FIDL 而添加的临时解决方案,而不是核心功能。在这种情况下,流式传输还是大型消息是更好的选择似乎非常依赖于具体情境。
总而言之:大型消息只是通过网络获取大量数据的潜在方法工具箱中的一种工具。FIDL 很可能在未来会提供一流的流式传输实现,该实现将补充而非取代大型消息所提供的功能。
有界协议和灵活的信封大小限制
这种设计存在非常真实的拒绝服务攻击风险,某些协议(尤其是那些在许多原本独立的客户端之间共享的协议)可能希望避免这种风险。为此,可以想象一下向协议添加 bounded 修饰符,以在编译时强制执行以下操作:确保协议的所有方法仅使用有界类型:
// Please note that this syntax is very speculative!
bounded protocol SafeFromMemoryDoS {
// The payload is bounded, so this method compiles.
MySafeMethod(resource struct {
a bool;
b uint64;
c array<float32, 4>;
d string:32;
e vector<zx.handle, 64>;
});
};
这种设计的一个后果是,FIDL 协议作者面临着“二分”选择:添加 bounded 可使协议免受因消息过大而可能造成的拒绝服务攻击,但会阻止相应方法的载荷传递性地使用 table 或 flexible union 类型。这是一个令人遗憾的权衡,因为可演化性和 ABI 兼容性是 FIDL 语言的核心目标。通过强制用户使用 ABI 稳定类型,我们极大地限制了他们未来发展载荷的能力。
一种可能的折衷方案是为 flexible 包裹布局引入明确的大小限制。这样一来,随着时间的推移,灵活的定义会发生变化,但仍会强制对类型的最大大小施加严格的、会破坏 ABI 的限制,从而提供 ABI 兼容性:
// Please note that this syntax is very speculative!
@available(added=1)
type SizeLimitedTable = resource table {
1: orig vector<zx.handle>:100;
// Version 2 still compiles, as it contains <=4096 bytes AND <=1024 handles.
@available(added=2)
2: still_ok string:3000;
// Version 3 fails to compile, as its maximum size is greater than 4096 bytes.
@available(added=2)
3: causes_compile_error string:1000;
}:<4096, 1024>; // Table MUST contain <=4096 bytes AND <=1024 handles.
这种大小限制提供了一种“软”灵活性:载荷仍然能够随时间变化,但在首次定义载荷时,对载荷增长的范围设置了硬性(即 ABI 破坏性)限制。
在先技术和参考资料
此提案有充分的先例,因为 fuchsia.mem.Data 以及之前的 fuchsia.mem.Buffer 和 zx.handle:VMO 在整个 fuchsia.git 代码库中得到广泛使用和支持。此决策实际上是经过充分测试的这种模式的“一流”演变。
之前有一份已废弃的 RFC 描述了与此 RFC 有些类似的内容,也使用 VMO 作为大型消息的底层传输机制。
附录 A:fuchsia.git 中 FIDL 载荷的界限
下表显示了 fuchsia.git 代码库中截至 2022 年 8 月初的溢出(大于 64KiB)载荷与标准载荷之间的有界性分布。该数据是通过构建 fuchsia.git 的“所有内容” build 收集的。然后,通过一系列 jq 查询分析生成的 JSON IR。
清单 7:表格,显示了 fuchsia.git 代码库中每种有效负载边界和大小的测量频率。
| 有界性 / 消息种类 | 标准 | 溢出 | 总计 |
|---|---|---|---|
| 有界限 | 3851 (76%) | 45 (%) | 3896 (77%) |
| 半有界 | 530(10%) | 70 (1%) | 600 (11%) |
| 无界限 | 0 (0%) | 602 (12%) | 602 (12%) |
| 总计 | 4381(86%) | 717 (14%) | 5098 (100%) |