
| RFC-0226:Zircon 分页器回写 | |
|---|---|
| 状态 | 已接受 |
| 区域 |
|
| 说明 | 内核支持,用于跟踪和回写对分页内存 VMO 的修改 |
| 问题 | |
| Gerrit 更改 | |
| 作者 | |
| 审核人 | |
| 提交日期(年-月-日) | 2023-04-13 |
| 审核日期(年-月-日) | 2023-09-19 |
摘要
本文档介绍了 Zircon 内核对分页内存的支持,该内存可以修改,然后写回(同步)到分页器源(例如存储磁盘)。
设计初衷
Zircon 支持创建由用户空间分页器服务(通常由文件系统托管)支持的 VMO(虚拟内存对象)。单个文件在内存中表示为 VMO。当访问 VMO 的页面时,它们会根据需要被换入,用户分页器会从磁盘读取页面的内容。
Zircon 分页器 API 最初仅支持只读文件;没有机制可用于将内存中已脏的 VMO 页面写回磁盘。此设计足以托管 blobfs 等不可变文件系统,该文件系统用于提供 Fuchsia 上的所有可执行文件和其他只读文件。不过,对于通用文件系统,如果客户端可以修改文件内容,并且需要将文件内容同步回磁盘,则必须支持回写。
如果没有回写支持,minfs 和 fxfs 等可变文件系统就无法利用按需分页。作为一种解决方法,可变文件系统必须使用匿名(非分页器支持)VMO 将文件缓存在内存中,并自行管理这些 VMO 的内容。即使很少或从不访问这些 VMO 中的某些页面,也可能需要将这些 VMO 完整地保留在内存中。将这些匿名 VMO 切换为分页器支持的 VMO,其中页面可以根据需要进行缺页中断和逐出,从而使可变文件系统能够更好地利用内存。写回支持还允许可变文件系统的客户端直接对 VMO 执行读取和写入操作,而不是依赖于通道进行数据传输,而通道受通道限制的约束,速度可能会非常慢。
在本文档的其余部分中,术语“用户寻呼器”和“文件系统”可互换使用,具体取决于上下文。
利益相关方
辅导员:
- cpu@google.com
审核者:
- adanis@google.com、csuter@google.com
已咨询:
- brettw@google.com、cdrllrd@google.com、godtamit@google.com、maniscalco@google.com、travisg@google.com
共同化:
此 RFC 经过了本地存储团队的设计审核。
要求
所提出的设计方案可满足以下目标:
- 增强 Zircon 以支持将分页器支持的 VMO 写回,从而允许构建高性能可变文件系统(使用 Zircon 流)。
- 支持通过虚拟机映射(例如
mmap文件)进行文件读写。 - 提供用户分页器启动的尽力刷新脏页,以降低因意外关机导致的数据丢失风险。
- 在未来的迭代中,允许内核(通过用户分页程序)根据系统内存压力逐出脏页。
以及一些非目标:
- 除了用户分页器启动的刷新之外,内核不会对脏页的清理速率做出任何保证。不过,未来的发展可能会增加限制未完成脏数据量的功能,并让内核根据该量启动回写请求。
- 防止因违反内核/分页器协议而导致的数据丢失不是目标。如果用户分页器在关闭其对 VMO 的句柄(或终止)之前未能查询脏页并将其写回,则可能会发生数据丢失。
设计
概览
拟议的设计旨在支持以下两种直接用例:
- 文件系统客户端可以通过封装文件 VMO 的内核对象(即流)访问文件。这可以大致视为与
zx_vmo_read()和zx_vmo_write()类似,因为流 syscall 在内部封装了 VMO 读取/写入内核例程。 - 文件系统客户端还可以
mmap文件,这大致相当于使用zx_vmar_map将文件 VMO 映射到客户端进程的地址空间。
为简单起见,本文档的其余部分将讨论与文件 VMO 的直接交互,无论是通过系统调用 (zx_vmo_read/write) 还是通过 VM 映射 (zx_vmar_map)。
以下是几个示例,展示了涉及回写的互动可能是什么样的。
示例 1
- 文件系统客户端针对给定范围对文件 VMO 执行
zx_vmo_read()。 - 由于 VMO 是由分页器支持的,因此内核会为关联的用户分页器生成读取请求。
- 由文件系统托管的用户分页器满足此请求。它会提供从磁盘读取的内容。
- 文件系统客户端对同一范围的 VMO 执行
zx_vmo_write()。VMO 的页面之前已在第 3 步中填充,因此可以直接写入。所做的修改目前仅在内存中,但需要在某个时间点反映回磁盘。 - 用户分页器会查询内核,以获取 VMO 中已脏化 / 修改的范围。这可以作为文件系统执行的定期后台刷新的一部分来完成,也可以响应文件系统客户端请求的刷新来完成。
- 用户分页程序将查询到的脏范围写回磁盘。此时,修改后的文件内容已成功持久保存到磁盘。
示例 2
- 文件系统客户端使用
zx_vmar_map()映射文件 VMO。映射从地址addr开始。客户端读取从addr开始的范围。 - 与示例 1 相同。
- 与示例 1 相同。
- 文件系统客户端现在写入从
addr开始的同一范围。底层页面已填充,因此内容在内存中修改。修改需要在某个时间点反映回磁盘。 - 与示例 1 相同。
- 与示例 1 相同。
此处的示例先执行 VMO 读取,然后再执行写入。请注意,这样做只是为了将用户分页器的页面填充拆分为一个单独的步骤,为清晰起见。客户端可以直接写入尚未在内存中的文件偏移量;写入操作会一直阻塞,直到用户分页器先提供相应页面。
上述两个示例均假设文件系统遵循覆盖写入模型,其中已填充(已提交)的页面可以直接写入,而无需先请求额外的空间。修改后的内容会写回磁盘上的同一位置,因此无需为修改分配额外的空间。不过,fxfs 和 minfs 等文件系统使用写入时复制 (CoW) 模型,其中每次修改都需要在磁盘上分配新空间。因此,我们还需要一种机制来预留空间,以便写入已提交的网页;修改了步骤 4,以便在写入操作继续之前等待该预留。
为了执行回写,Zircon 分页器 API 进行了扩展,以支持以下功能:
- 内核会阻止写入用户分页器已指示应遵循写入时复制方案的 VMO,并在用户分页器确认写入后继续。
- 内核会跟踪 VMO 中的脏页,并具有向用户分页程序显示该信息的机制。
- 用户分页程序会向内核指示何时同步 VMO 中的脏范围以及何时完成同步,以便内核相应地更新脏跟踪状态。
- 内核还会向用户分页程序提供有关 VMO 大小调整的信息。
- 用户寻呼器有一种方法可以查询内核代表其跟踪的相关信息,例如 VMO 上次修改的时间。
分页程序和 VMO 创建
分页器创建系统调用保持不变,即使用 zx_pager_create() 创建将 options 设置为 0 的分页器。
使用 zx_pager_create_vmo() 创建基于分页器的 VMO,并将其与分页器端口和将用于相应 VMO 的页面请求数据包中的密钥相关联。zx_pager_create_vmo() 系统调用还支持新的 options 标志 ZX_VMO_TRAP_DIRTY。这表示内核应捕获对 VMO 的任何写入,并首先从用户分页器请求对写入的确认。此标志适用于以写入时复制模式运行的文件。有关此标志的更多详情,请参阅下文。
// Create a VMO (returned via |out|) backed by |pager|. Pager requests will be
// queued on |port| and will contain the provided |key| as an identifier.
// |size| will be rounded up to the page boundary.
//
// |options| must be 0 or a combination of the following flags:
// ZX_VMO_RESIZABLE - if the VMO can be resized.
// ZX_VMO_TRAP_DIRTY - if writes to clean pages in the VMO should be trapped by the
// kernel and forwarded to the pager service for acknowledgement before proceeding
// with the write.
zx_status_t zx_pager_create_vmo(zx_handle_t pager,
uint32_t options,
zx_handle_t port,
uint64_t key,
uint64_t size,
zx_handle_t* out);
默认情况下,所有分页内存支持的 VMO 都被视为可变;这也可用于实现只读文件系统,而无需额外费用。修改页面的代码路径可能不会针对只读 VMO 执行。不过,如果 VMO 被修改(可能是意外误用),但用户分页器从不查询其中的脏页并尝试将其写回,则修改后的内容将仅保留在内存中。在未来,当内核生成回写请求时,用户分页器可以将此类 VMO 的回写请求视为错误,也可以直接忽略它们。
提供 VMO 页面
分页内存支持的 VMO 中的页面由用户分页程序根据需要填充,并在收到分页程序读取请求时填充 zx_pager_supply_pages()。此系统调用已存在,可用于只读 VMO。
回写的页面状态
由分页器支持的 VMO 可以有三种状态的页面 - Dirty、Clean 和 AwaitingClean。这些状态编码在 vm_page_t 中。
这三种状态之间的转换遵循以下步骤:
- 新提供的
zx_pager_supply_pages()页面最初为Clean。 - 当页面被写入时,它会转换为
Dirty。如果 VMO 是使用ZX_VMO_TRAP_DIRTY创建的,则内核会先阻塞,等待用户寻呼器对DIRTY寻呼器请求的确认。有关此互动的更多详情,请参阅下文。 - 用户分页器会在稍后通过系统调用查询内核,以获取 VMO 中的脏页列表。
- 对于内核返回的每个脏页,用户分页器都会调用一个系统调用来向内核发出信号,表明它正在开始回写该页面,这会将该页面的状态更改为
AwaitingClean。 - 如果写入的页面超出此点,其状态会切换回
Dirty。 - 用户分页程序在完成页面写回后会发出另一个系统调用。如果此时网页状态为
AwaitingClean,则会转换为Clean。 - 如果用户分页器在回写时遇到错误,则页面会保持
AwaitingClean状态。未来对脏页的查询会返回AwaitingClean和Dirty页面,以便用户分页器可以再次尝试写回页面。
下面的状态图显示了这些状态之间的转换。
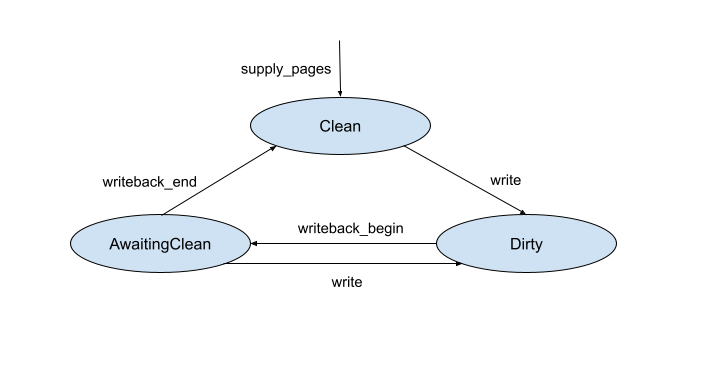
AwaitingClean 需要作为单独的状态进行跟踪,原因如下:
虽然处于
Clean和AwaitingClean状态的页面在写入时都会转换为Dirty,但用户分页器正在写回的页面需要与Clean页面区别对待。在内存压力下,Clean页面可以被回收,但正在写回的页面需要受到保护,以免被回收。内核需要知道已写回哪个版本的页面,以便在用户分页程序完成时正确地将其转换为
Clean。这对于区分在刷新之前传入的页面写入(已安全地写入磁盘)与之后传入的页面写入(需要稍后写回)非常重要。我们可以避免在回写开始时从用户分页程序进行系统调用,并且内核可以在将页面作为脏页面查询的一部分返回给用户分页程序时,简单地将页面标记为
AwaitingClean。不过,在查询之后,用户分页器可能仍需一段时间才能开始刷新页面,这会留下更长的时间窗口让页面再次变脏。如果回写窗口更紧凑,用户寻呼器将能够成功将页面移至Clean状态的可能性会更高。
为了更新脏状态,内核会跟踪何时通过 VMO 和流写入系统调用以及通过 VM 映射将页面写入到内存中。请注意,这适用于通过虚拟机映射发生的任何写入操作,无论是由用户还是内核执行的,也就是说,这也适用于内核在执行 zx_channel_read() 等系统调用时使用 user_copy 完成的写入操作。
在 zx_vmo_write() 等系统调用期间推断脏页非常简单,因为范围是指定的。访问 VMO 的另一种方式是通过进程地址空间中的 VM 映射。为了跟踪分页内存支持的 VMO 中的脏状态,可写映射在相应的页表条目中开始时会移除写入权限。因此,写入操作会生成保护错误,该错误通过恢复写入权限并将页面状态标记为 Dirty 来解决。
此处提及的 Dirty 状态是指 vm_page_t 跟踪的状态,即软件跟踪的脏状态。x86 上的硬件页表支持脏位跟踪,但我们选择不使用该功能来推导初始实现中的页面脏状态。对于不支持页表中脏位的旧版 arm64 平台,我们无论如何都需要在软件中跟踪脏位。因此,为了保持一致性和简化实现,我们选择一开始不使用硬件脏位来推断页面的脏 / 干净状态。依赖硬件页表位也会给页表回收带来复杂性,未来当我们依赖硬件位时,需要考虑这一点。
值得注意的是,只有由分页器直接支持的 VMO 才符合脏跟踪条件。换句话说,由分页器支持的 VMO 的 CoW 克隆不会选择加入脏跟踪,也不会看到任何回写请求。在克隆中写入的页面是从父级的页面副本派生出来的,克隆直接拥有这些页面,并将其视为不同的页面。
为待处理的写入操作预留空间
写入标记为使用 ZX_VMO_TRAP_DIRTY 创建选项标志捕获脏转换的 VMO 需要文件系统的确认。该解决方案分为两部分,其中 v1 从简单入手,更侧重于正确性,而 v2 则基于 v1 来提高性能。v1 提案主要遵循同步模型,文件系统会为新写入操作预留空间。在 v2 中,我们将添加另一层来表达内核中的脏预留配额以及它们如何应用于 VMO,以便内核可以自行跟踪预留。这将减少内核与文件系统之间的大部分来回通信,从而提高性能。
ZX_VMO_TRAP_DIRTY v1
ZX_VMO_TRAP_DIRTY VMO 创建标志表示内核应捕获 VMO 中的任何 Clean->Dirty 页面转换(或 AwaitingClean->Dirty 转换)。当写入操作发生在尚未标记为脏的页面上时,内核会生成 ZX_PAGER_VMO_DIRTY 分页器请求。对于通过虚拟机映射进行的写入,请求跨越包含错误地址的单个页面。对于流/VMO 写入,内核会针对需要写入的范围内每个连续运行的非脏页发送请求。
针对范围 [start, end) 的脏请求如下所示。
zx_packet_page_request_t request {
.command = ZX_PAGER_VMO_DIRTY,
.flags = 0,
// |offset| and |length| will be page-aligned.
.offset = start,
.length = end - start,
};
ZX_VMO_TRAP_DIRTY 创建标志适用于以 CoW 模式写入的文件,以及以覆盖模式写入的稀疏文件。如果未指定该标志,系统会将页面标记为 Dirty,并继续写入,而无需用户分页器参与;这适用于在覆盖模式下写入的非稀疏文件。
用户寻呼机使用 zx_pager_op_range() 确认 ZX_PAGER_VMO_DIRTY 请求:
ZX_PAGER_OP_DIRTY将尚未处于Dirty状态的页面状态设置为Dirty,然后内核继续执行被阻塞的写入操作。ZX_PAGER_OP_FAIL不会改变页面的当前状态,并且会使发起写入的zx_vmo_write()调用失败,为虚拟机映射生成严重页面错误异常,如果是zx_stream_write(),则会成功返回并进行部分写入。
// |pager| is the pager handle.
// |pager_vmo| is the VMO handle.
// |offset| and |length| specify the range, i.e. [|offset|, |offset| + |length|).
//
// |op| can be:
//
// ZX_PAGER_OP_DIRTY - The userspace pager wants to transition pages in the range
// [offset, offset + length) from clean to dirty. This will unblock any writes that
// were waiting on ZX_PAGER_VMO_DIRTY page requests for the specified range.
// |data| must be 0.
//
// ZX_PAGER_OP_FAIL - The userspace pager failed to fulfill page requests for
// |pager_vmo| in the range [offset, offset + length) with command
// ZX_PAGER_VMO_READ or ZX_PAGER_VMO_DIRTY.
//
// |data| contains the error encountered, a zx_status_t error code sign-extended
// to a |uint64_t| value - permitted values are ZX_ERR_IO, ZX_ERR_IO_DATA_INTEGRITY,
// ZX_ERR_BAD_STATE and ZX_ERR_NO_SPACE.
zx_status_t zx_pager_op_range(zx_handle_t pager,
uint32_t op,
zx_handle_t pager_vmo,
uint64_t offset,
uint64_t length,
uint64_t data);
根据文件系统刷新脏数据和标记页面 Clean 的频率,当客户端写入页面时,此方法可能会产生显著的性能开销。为了避免这种开销,文件系统可能会尽可能长时间地延迟刷新脏数据,但这并不是一个好的激励措施 - 脏页面无法被逐出,会增加内存压力,并且刷新间隔时间越长,数据丢失的可能性也越大。v2 提案试图减少面向客户端的写入操作带来的部分性能开销。
ZX_VMO_TRAP_DIRTY v2
将添加新的系统调用 zx_pager_set_dirty_pages_limit(),以指定内核允许累积的脏页数量。这里的预期是,文件系统会预先为这些脏页预留空间。此限制将是每个分页器的限制,默认设置为零。
可以使用 zx_pager_set_dirty_pages_limit() 将限制设置为非零值(如果需要,可以多次设置)。v1 设计基本上以零为限运行。
zx_status_t zx_pager_set_dirty_pages_limit(zx_handle_t pager_handle,
uint64_t num_dirty_pages);
内核将跟踪每个分页器的脏页数量(稍后会详细介绍符合跟踪条件的页面类型),在转换为 Dirty 时递增计数,在转换为 Clean 时递减计数。内核仍会像在 v1 中一样捕获每个脏转换,但如果这样做不会超出分配的脏限制,它只会增加未完成的脏页数。如果新计数不超过限制,内核将继续执行写入操作,而无需用户分页器参与。这应该是正常的运行模式,因此每次页面变脏时,都可以节省往返用户寻呼机的费用。
采用此方法时,用户分页器需要向内核传达两件事:
- 整个内存分页的脏页上限
- 在变脏时会占用相应限额的页面
对于 2),我们再次依赖于 ZX_VMO_TRAP_DIRTY VMO 创建标志。此标志现在会触发生成一种新的分页器请求:ZX_VMO_DIRTY_MODE。现在,当内核捕获写入时,它会咨询文件系统,以确定是否应选择将这些页面纳入脏页限制的计数范围。用户寻呼机使用两种新的操作类型之一来响应 zx_pager_op_range。
ZX_PAGER_OP_DIRTY_MODE_POOLED会告知内核,相应范围内的页面将计入每个内存管理器的脏页限制。此方法旨在用于以 CoW 模式运行的文件,以及以覆盖模式运行的文件的稀疏区域。ZX_PAGER_OP_DIRTY_MODE_UNPOOLED会告知内核,相应范围内的页面不会计入脏页限制。此值适用于以覆盖模式运行的稀疏文件的非稀疏区域。
标记为 ZX_PAGER_OP_DIRTY_MODE_POOLED 的页面会转换为 Dirty,并且未完成的寻呼器脏计数会递增,前提是未超过寻呼器脏限制。不过,如果脏化页面会超出分页器脏限制,内核会开始生成 ZX_PAGER_VMO_DIRTY 数据包,即 v1 中所述的默认模式。可以提供一个可选标志,用于在写回页面(转换为 Clean)时设置脏模式,这样可以节省捕获未来写入以生成 ZX_VMO_DIRTY_MODE 分页器请求的费用。
这种设计支持灵活的模型,其中文件系统可以在其 VMO 上混合使用不同类型的写入模式。以 CoW 模式写入的文件将使用 ZX_VMO_TRAP_DIRTY 创建其 VMO,并且其页面可以使用 Pooled 模式。同样,在“覆盖”模式下,可以使用 ZX_VMO_TRAP_DIRTY 标志创建稀疏文件,并分别针对稀疏区域和非稀疏区域使用“池化”模式和“非池化”模式。始终使用覆盖模式的文件可以完全省略 ZX_VMO_TRAP_DIRTY 标志,这样就永远不必支付写入时寻呼器请求的费用。
当用户分页器在脏配额用完时开始接收 ZX_PAGER_VMO_DIRTY 请求后,预计会开始清理页面,以便为新的脏页面腾出空间。当它完成 zx_pager_set_dirty_pages_limit() 时,会发出信号,使用与之前相同的限制或新的限制。在此调用之后,内核将在未来的写入操作中恢复检查累积的脏计数是否超过脏限制,并且仅在再次达到脏限制时生成 ZX_PAGER_VMO_DIRTY 请求。
ZX_VMO_TRAP_DIRTY v1 和 v2 之间的区别
v1 和 v2 之间的主要区别在于负责跟踪预订数量的实体。在 v1 中,文件系统负责跟踪预留,内核会告知文件系统何时以及将预留计数增加多少。由于负责拦截对预留的潜在更改的实体(内核)与执行实际簿记的实体(文件系统)不同,因此两者之间需要紧密耦合。在 v2 中,我们尝试通过让内核自行跟踪预留计数来稍微放宽这一限制。因此,只有在以下情况下才需要与文件系统通信:1) 需要设置 VMO 范围以选择启用(或停用)内核预留跟踪;2) 内核的预留配额用尽,文件系统需要介入。
我们预计 2) 是此处的极端情况,因为文件系统会定期将脏页刷新到磁盘。预计大部分通信都是由 1) 引起的。内核可以多次请求同一范围的信息(例如,对于跨越重叠范围的写入),同样,文件系统也可以多次向内核提供有关同一范围的冗余信息。在网页上设置脏模式实际上不会消耗任何脏限制,因为只有在网页实际写入时,脏计数才会递增。因此,文件系统还可以推测性地设置页面的脏模式,以减少未来分页器请求的性能开销(但需要注意,页面逐出可能会发挥作用)。
发现脏范围
用户分页程序需要一种机制来了解 VMO 中的脏页,以便将其写回。这里需要考虑两种不同的模型:一种是拉取模型,即用户分页程序从内核查询脏页信息;另一种是推送模型,即内核通过向用户分页程序发送回写请求来指示脏页。初始设计从更简单的拉取模型开始,并引入了脏范围查询系统调用,该系统调用可能如下所示:
// |pager| is the pager handle.
// |pager_vmo| is the vmo handle.
// |offset| and |length| specify the VMO range to query dirty pages within.
// Must be page-aligned.
//
// |buffer| points to an array of type |zx_vmo_dirty_range_t| defined as follows.
// typedef struct zx_vmo_dirty_range {
// // Represents the range [offset, offset + length).
// uint64_t offset;
// uint64_t length;
// // Any options applicable to the range.
// // ZX_VMO_DIRTY_RANGE_IS_ZERO indicates that the range contains all zeros.
// uint64_t options;
// } zx_vmo_dirty_range_t;
//
// |buffer_size| is the size of |buffer|.
//
// |actual| is an optional pointer to return the number of dirty ranges that were
// written to |buffer|.
//
// |avail| is an optional pointer to return the number of dirty ranges that are
// available to read. If |buffer| is insufficiently large, |avail| will be larger
// than |actual|.
//
// Upon success, |actual| will contain the number of dirty ranges that were copied
// out to |buffer|. The number of dirty ranges that are copied out to |buffer| is
// constrained by |buffer_size|, i.e. it is possible for there to exist more dirty
// ranges in [offset, offset + length) that could not be accommodated in |buffer|.
// The caller can assume than any range that had been made dirty prior to
// making the call will either be contained in |buffer|, or will have a start
// offset strictly greater than the last range in |buffer|. Therefore, the caller
// can advance |offset| and make another query to discover further dirty ranges,
// until |avail| is zero.
//
zx_status_t zx_pager_query_dirty_ranges(zx_handle_t pager,
zx_handle_t pager_vmo,
uint64_t offset,
uint64_t length,
void* buffer,
size_t buffer_size,
size_t* actual,
size_t* avail);
用户分页器预计会多次调用此查询,不断推进其查询的偏移量,直到处理完所有脏页。
在拉取模型中,清理页面的速率完全取决于文件系统选择查询脏范围并尝试回写的速率。不过,在少数情况下,内核本身需要发起回写页面的请求,例如在内存压力过大的情况下,以便清理脏页面并随后释放这些页面。在这种情况下,内核可能会按 LRU 顺序发送脏页的回写请求。此标志旨在为用户分页器提供提示,以便它可以提高刷新页面的速率,例如,如果它以延迟方式处理请求。
VMO 中脏范围 [start, end) 的回写请求可能如下所示。
zx_packet_page_request_t request {
.command = ZX_PAGER_VMO_WRITEBACK,
.flags = ZX_PAGER_MEMORY_PRESSURE,
// |offset| and |length| will be page-aligned.
.offset = start,
.length = end - start,
};
写回脏范围
扩展了 zx_pager_op_range() 系统调用,以支持两个额外的操作 ZX_PAGER_OP_WRITEBACK_BEGIN 和 ZX_PAGER_OP_WRITEBACK_END,分别用于指示用户分页器何时开始刷新页面以及何时完成刷新。
ZX_PAGER_OP_WRITEBACK_BEGIN会将指定范围内的所有Dirty页面的状态更改为AwaitingClean。对于已处于AwaitingClean或Clean状态的任何网页,系统都会忽略此值,并保持这些状态不变。ZX_PAGER_OP_WRITEBACK_END会将指定范围内的所有AwaitingClean页面的状态更改为Clean。对于已处于Clean状态或处于Dirty状态的任何网页,系统都会忽略此值,并保持其状态不变。
如果在执行 flush 期间(即在 ZX_PAGER_OP_WRITEBACK_BEGIN 之后但在 ZX_PAGER_OP_WRITEBACK_END 之前)遇到任何错误,用户寻呼机无需再执行任何操作。假设没有其他写入操作,这些页面在内核中会保持 AwaitingClean 状态。当内核再次查询脏页时,它将包含 AwaitingClean 页以及 Dirty 页,然后用户分页器可以再次尝试对这些失败的页面进行回写。
// Supported |op| values are:
// ZX_PAGER_OP_WRITEBACK_BEGIN indicates that the user pager is about to
// begin writing back the specified range and the pages are marked |AwaitingClean|.
// ZX_PAGER_OP_WRITEBACK_END indicates that that user pager is done writing
// back the specified range and the pages are marked |Clean|.
//
// |pager| is the pager handle.
// |pager_vmo| is the VMO handle.
// |offset| and |length| specify the range to apply the |op| to, i.e. [|offset|,
// |offset| + |length|).
// For ZX_PAGER_OP_WRITEBACK_*, |data| is unused and should be 0.
zx_status_t zx_pager_op_range(zx_handle_t pager,
uint32_t op,
zx_handle_t pager_vmo,
uint64_t offset,
uint64_t length,
uint64_t data);
对于 ZX_PAGER_OP_WRITEBACK_BEGIN,data 可选择性地设置为 ZX_VMO_DIRTY_RANGE_IS_ZERO,以表明调用方希望将指定范围写回为零。当调用方处理由 zx_pager_query_dirty_ranges() 返回且其 options 设置为 ZX_VMO_DIRTY_RANGE_IS_ZERO 的范围时,应使用此方法。它可确保在查询之后但在回写开始之前在范围内创建的任何非零内容不会因错误地假设其仍为零并将其标记为干净(因此可逐出)而丢失。
调整 VMO 的大小
分页内存支持的 VMO 与匿名(非分页内存支持的)VMO 在处理 VMO 中缺少内容的方式上有所不同。匿名 VMO 具有隐式的零初始内容,因此未提交的页面意味着零。对于由分页器支持的 VMO,情况并非如此,未提交的页面并不意味着零;它们只是意味着分页器尚未为这些页面提供内容。不过,如果调整为更大的尺寸,分页器无法提供新扩展范围内的页面,原因很简单,因为后备来源(例如存储磁盘)上还没有相应内容,因此无法分页。内核可以提供此新扩展范围内的零页,而无需咨询用户分页器。
调整大小是通过跟踪跨越新调整大小范围的零间隔来处理的,内核会隐式提供零页面。用户分页器尚不知道此零间隔,因此当用户分页器查询脏范围时,此范围会被报告为脏范围。此外,zx_vmo_dirty_range_t 中的 options 字段针对此范围设置为 ZX_VMO_DIRTY_RANGE_IS_ZERO,以表明它全为零。
如果 VMO 是使用 ZX_VMO_TRAP_DIRTY 标志创建的,并且页面写入到这个新扩展的范围内,内核会在提交这些页面之前为其生成 ZX_PAGER_VMO_DIRTY 分页器请求。这是因为文件系统可能需要为实际(非零)页面预留空间。此模型假设文件系统可以通过稀疏区域在磁盘上高效地表示零,因此仅当在新扩展的范围内提交页面时才咨询文件系统。
从寻呼机分离 VMO
zx_pager_detach_vmo() 将 ZX_PAGER_COMPLETE 数据包排入队列,这表示用户分页器将来不应再针对相应 VMO 提出分页器请求。这也表明用户分页器应查询并写回所有未完成的脏页。请注意,分离操作不会阻塞,直到脏页面被写回为止;它只会通知用户分页器可能需要刷新。
分离后,原本需要生成寻呼器请求的 zx_vmo_read() / zx_vmo_write() 会因 ZX_ERR_BAD_STATE 而失败。通过映射进行读取和写入,这些映射同样需要寻呼器请求生成致命的页面错误异常。内核可以自由舍弃 VMO 中的干净页面。不过,内核会保留脏页,直到用户分页程序清理这些脏页。也就是说,即使 VMO 已分离,ZX_PAGER_OP_WRITEBACK_BEGIN 和 ZX_PAGER_OP_WRITEBACK_END 仍继续受支持。zx_pager_op_range() 在所有其他操作上,zx_pager_supply_pages() 在分离的 VMO 上失败并显示 ZX_ERR_BAD_STATE。
如果寻呼器在关联的 VMO 中包含脏页的情况下被销毁,则内核可以随时移除这些页面,无论是否存在任何未完成的回写请求。换句话说,只有当分页器存在时,脏页才能保证保留在内存中,以便分页器能够清理它们。
查询分页器 VMO 统计信息
内核还会跟踪 VMO 是否被修改,用户寻呼器可以查询此信息。此方法旨在供用户寻呼机用于跟踪 mtime。
// |pager| is the pager handle.
// |pager_vmo| is the VMO handle.
// |options| can be ZX_PAGER_RESET_VMO_STATS to reset the queried stats.
// |buffer| points to a struct of type |zx_pager_vmo_stats_t|.
// |buffer_size| is the size of the buffer and should be large enough to
// accommodate |zx_pager_vmo_stats_t|.
//
// typedef struct zx_pager_vmo_stats {
// uint32_t modified;
// } zx_pager_vmo_stats_t;
zx_status_t zx_pager_query_vmo_stats(zx_handle_t pager,
zx_handle_t pager_vmo,
uint32_t options,
void* buffer,
size_t buffer_size);
如果 VMO 已修改,则返回的 zx_pager_vmo_stats_t 的 modified 字段设置为 ZX_PAGER_VMO_STATS_MODIFIED,否则设置为 0。未来,zx_pager_vmo_stats_t 结构可能会扩展更多字段,以便用户寻呼机查询。
modified 状态会在修改 VMO 的系统调用(例如 zx_vmo_write() 和 zx_vmo_set_size())上更新,也会在首次通过映射发生写入页面错误时更新。系统已跟踪页面上的首次写入错误,以正确管理从 Clean 到 Dirty 的转换,因此 modified 状态会在那时更新。不过,通过脏页上的映射传入的未来写入不会被跟踪;这样做会显著减慢对映射的 VMO 的写入速度。因此,对于已映射的 VMO,modified 状态可能并不完全准确。
如果用户寻呼器还希望重置查询的统计信息,则 options 可以为 ZX_PAGER_RESET_VMO_STATS。如果 options 值为 0,则不会重置任何状态,而是执行纯查询。请注意,如果指定了 ZX_PAGER_RESET_VMO_STATS 选项,此调用可能会通过消耗可查询状态来影响未来的 zx_pager_query_vmo_stats() 调用。例如,如果 zx_vmo_write() 之后是两次连续的 zx_pager_query_vmo_stats() 调用(带有 ZX_PAGER_RESET_VMO_STATS 选项),则只有第一次调用会看到 modified 设置。由于在第一次 zx_pager_query_vmo_stats() 之后没有进行进一步修改,因此第二次 zx_pager_query_vmo_stats() 将返回 modified(即 0)。
实现
分页回写功能已开发一段时间,所有新的 API 部分都已在 @next vDSO 中提供。fxfs 已采用回写 API 来支持流读取/写入和 mmap。
性能
借助页面回写,fxfs 能够从通过渠道执行 I/O 切换到使用流,这使得各种基准的性能提升了大约 40-60 倍。
安全注意事项
无。
隐私注意事项
无。
测试
已编写内核核心测试和压力测试来练习分页器系统调用。此外,还有存储测试和性能基准。
文档
更新了内核系统调用文档。
缺点、替代方案和未知因素
对回写请求进行速率限制
在未来的迭代中,当内核生成回写请求时(在内存压力下或以稳定的后台速率),我们需要某种策略来控制分页器端口上排队的回写请求数量。一种方法是让内核跟踪正在处理的未完成请求的数量,并尝试将其保持在一定限度内。
另一种方法是让用户寻呼机配置可调参数,这些参数直接或间接地决定了回写请求的生成速率。例如,用户寻呼器可以指定在将脏页排队等待回写之前,脏页可以保留的建议时长,也可以指定用户寻呼器可以支持的典型写入数据传输速率。可能存在需要比全局系统默认值高得多的后台回写速率的文件系统。用户分页器指定其处理请求的粒度(系统页面大小的倍数)可能也很有用。然后,内核在计算范围时可以考虑这一点,并且可能能够减少总体请求数。
跟踪和查询网页年龄信息
对于初始实现,内核会在一个页面队列中跟踪脏页,该队列按页面首次变脏的时间排序。此队列可用于在将来生成回写请求,并且在清理页面后,可以将这些页面从脏队列移至(干净的)分页器支持的队列,这些队列目前用于跟踪只读页面并确定其使用期限。我们可能还希望更精细地跟踪脏页的年龄;将脏页和干净页统一到一个通用池中,以便利用老化和访问位跟踪来处理全局工作集,这可能是有意义的。我们可能还希望通过新的 API 将此年龄信息公开给用户寻呼器,以便在处理回写请求时将其纳入考虑范围。
在回写期间阻止进一步写入
此处提出的设计不会阻止在回写进行期间(即在 ZX_PAGER_OP_WRITEBACK_BEGIN 和 ZX_PAGER_OP_WRITEBACK_END 之间)传入的新写入。相反,写入的页面会再次被标记为脏页。也许某些文件系统希望在页面处于 AwaitingClean 状态时阻止写入操作。我们可能会考虑在未来添加 ZX_PAGER_OP_WRITEBACK_BEING_SYNC,以在回写期间阻止写入。请注意,ZX_VMO_TRAP_DIRTY v1 提供了一种通过 ZX_PAGER_VMO_DIRTY 分页器请求解决此问题的方法,该方法允许文件系统在刷新正在进行时暂停处理。