
| RFC-0279: Support for product-specific blob formats | |
|---|---|
| Status | Accepted |
| Areas |
|
| Description | This RFC proposes the usage of different blob types for different products |
| Issues | |
| Gerrit change | |
| Authors | |
| Reviewers | |
| Date submitted (year-month-day) | 2026-02-02 |
| Date reviewed (year-month-day) | 2026-03-10 |
Problem Statement
Different kinds of Fuchsia-based products may benefit from storing blobs on blobfs / fxblob in different formats, optimized for their particular workload or requirements. For instance, there may be requirements for best possible compression ratio, for best decompression speed, or for the minimum amount of processing RAM. The ability to produce builds with a variety of blob format settings is currently very limited in Fuchsia.
Summary
This RFC proposes the introduction of arbitrary blob types, and support for them in local storage, build, assembly, software delivery and server-side infrastructure. It builds on top of the ideas and proposals which have been ratified in RFC-276 ("Support for system updates with changes to the blob format"). However, instead of focusing on the type 1 to type 2 migration, this RFC generalizes towards the support of arbitrary blob types, by:
- Leveraging the software support built into local storage and software delivery facilitating the type 1 to type 2 migration to support arbitrary types.
- Leveraging software assembly support to generate the required type of blob when assembling the product bundles.
- Extending the update client-server communication such that clients can request particular blob types.
- Extending the tooling to convert between all supported blob types.
Familiarity with RFC-276: Support for system updates is essential as this RFC builds on top of its concepts and explanations.
Stakeholders
Facilitator: davemoore@google.com
Reviewers:
- csuter@google.com (Storage)
- jfsulliv@google.com (Storage)
- etryzelaar@google.com (SWD)
- amituttam@google.com (PM)
- awolter@google.com (Software Assembly)
- markdittmer@google.com (Security)
- gtsai@google.com (Infrastructure)
Socialization:
This RFC was discussed in a series of design discussions internal to the software delivery, local storage and infrastructure teams. Early versions of the text in this RFC were reviewed with stakeholders in Build and Assembly teams.
Requirements
- As with RFC-276, for every client device in production, a soft transition to new blob formats shall always be possible. That is, any client device in production shall be able to be migrated to a new blob format without any user-visible impact.
- Again, the non-delivery blob format and the computation of the Merkle roots for given blobs remain unchanged. Stepping stones for the introduction of product-specific blobs should be avoided.
- The product configuration should be able to specify whether all blobs should
be updated to the specified format in case they are already stored on-disk
in a different format. If existing blobs are to be updated, the mechanism
should be able to complete updating of the blobs to the intended format
without end-user-visible impact from both intended and unintended
interruptions, for instance:
- Intended: Controlled by the software / configuration, for example to manage device thermals, read/write performance requirements, testing and benchmarking.
- Unintended: Loss of power, device reboot, incomplete migrations (e.g. due to connectivity problems, system crash causing reboot, ...).
Design
The following sections describe the technical changes to facilitate the given requirements. Most of the design and implementation choices of RFC-276 can be leveraged verbatim for product-specific blobs. In fact, during the drafting of RFC-276 the team anticipated that the future might hold the need for more blob types, and consciously avoided choices that would make the type 1 to type 2 migration special whenever possible. Hence, this RFC focuses on the differences and the pieces that come on top of the design in RFC-276.
Blob type naming, legacy blob types, ordering and consequences
This section clarifies important details about blob types. While there is no
change in meaning or semantics compared to RFC-207 and
RFC-276, it has been very easy to misinterpret the semantics because
previously, only the delivery blob types 1 and 2 have been defined. It is
important to note that these types are to be understood as enum, and shall
especially not be understood as a version denominator. The consequences are:
- Type 2 is different than type 1. It satisfies a different use case,
nothing more.
- It does not supersede type 1.
- It is not the successor of type 1.
- There is no ordering. The types are just names, nothing more.
- There is no notion of "up to type N": In a hypothetical scenario where blob types 1,2,3 and 4 are defined, stating "product X supports blob types 1 and 4" does not imply that 2 and 3 are supported as well.
In retrospect, type 2 should have been named differently in RFC-276 to avoid this misinterpretation as integer.
Legacy blob types
As a result of the potential misinterpretation as described in the previous section, we will henceforth refer to type 1 and type 2 as legacy blob types.
For the upcoming types, the use of integer-esque or single-letter names that may be interpreted as implying ordering, succession or improvement is discontinued. Instead, descriptive naming is used. This means that new blob types are expected to convey their meaning via their name in the enums and when converted to strings, for instance:
pub enum DeliveryBlobType {
...
/// Type 1 supports the zstd-chunked compression format. [legacy type]
Type1 = 1,
...
/// Uncompressed is a raw, uncompressed format [descriptive naming]
Uncompressed = 17,
/// Zstd compression, default settings [descriptive naming]
ZstdDefault = 18,
...
}
Note that the integer numbers allocated in the above example are purely for illustration purposes. They do not reflect currently existing code or the intention to be implemented in this exact manner.
When converting the descriptive types into strings, this RFC proposes that e.g.
ZstdDefault in the example above translates into vnd.fuchsia-blob.raw+zstd.
The reason for this is that this is a valid MIME type string which fits well
with a potential future extension allowing for client-server content negotiation
as described in a section below.
Transitioning to descriptive blob types
As mentioned in the previous section, upcoming blob types shall all carry descriptive names. This presents the opportunity to make a clean cut when introducing Fuchsia to new products, and avoid using legacy blob types for these products altogether. Thus, the following roadmap for the usage of the various blob types is proposed with this RFC:
- Descriptive blob types for
UncompressedandZstdLevel_X_Chunksize_Yare introduced to have one guaranteed uncompressed, raw blob type, as well as ones that mimic the existing type 1 and type 2.- Legacy blobfs (written in C++) is not expected to support descriptive blob types for now, only legacy types.
- The newer fxblob is expected to support all blob types, and is aware of the similarities and differences between the legacy types and their descriptive equivalents.
- Every product is required to support an uncompressed blob type.
- Legacy blobfs based products are required to support type 1.
- Fxblob based products are required to support both type 1 and
Uncompressed.
- If a client requests a legacy blob type from the server, i.e. uses an URL
like "https://blob.domain.tld/blobs/LegacyTypeName/87fa73ed...", the server
will alwaye return the blob type
LegacyTypeNamewith or without the uncompressed flag set. - If a client requests a descriptive blob type from the server, i.e. uses an
URL like "https://blob.domain.tld/blobs/DescriptiveTypeName/87fa73ed...", the
server will return a blob type of either
DescriptiveTypeNameorUncompressed, but never a legacy type (e.g. type1 with the uncompressed flag.)- In the future, if client-server content negotiation (see below) is added, the server may return any of the supported types as indicated in the request.
- Removal of type 1 or type 2 from a product will require a stepping stone.
Introduce new delivery blob types <T> as the need arises
The introduction of delivery blobs is discussed in RFC-207 ("Offline blob compression"). These blobs are designed for the efficient transfer of data from a blob server to fxblob/blobfs on a device. Delivery blobs include both the raw data and shared metadata (used for software delivery and local storage). This metadata can, for example, specify the type of payload compression.
Unlike the type 1 to type 2 migration which mostly addresses the need for improved compression ratios, this RFC does not specify the properties for the upcoming types, generally referred to as <T> in this RFC. These upcoming types will not require changes in the design or conceptual implementation of local storage, SWD or server side infrastructure. Hence there will be no further RFCs for new delivery blob types that adhere to the scheme described in this RFC.
To provide some possible examples of what is currently expected as potential upcoming types:
- Higher compression than either type 1 or type 2.
- Faster decompression than either type 1 or type 2.
- Different compression algorithms than either type 1 or type 2.
- Delta encoding, using a patch format to update existing blobs to a newer blob as part of an OTA.
While all of these shall be technically possible given this design, this is not to be confused with an announcement that all of these are going to be implemented in the foreseeable future.
The consequences of introducing a new blob type are a generalization of the description in RFC-276:
- The Fuchsia platform code (local storage, package management, ffx) will be
able to handle the a priori existing blob types as well as the newly
introduced one.
- If a blob type is not just disabled for future builds, but is intended to be removed completely, including the platform code that can handle it (e.g. removing a compression algorithm from the code base), then a proper stepping stone procedure as described in RFC-276 needs to be performed.
- For the local development workflows involving TUF repositories, there is no
guarantee for
fx otato always succeed, because there is currently no TUF-based mechanism to force a multi-stage update through a stepping stone release. For these situations, developers will be expected toffx target flashtheir devices as a workaround.
When the assembly configuration for a specific product has been changed to create the blob type <T> by default:
- The product bundle will contain only type <T> delivery blobs by default.
- The system updater will begin to request type <T> blobs.
- The server side package serving infrastructure will ensure that type <T>
and the previous default blob type for the particular project is available
to client devices. The
ffxtool will be available to the server side infrastructure to generate the desired blob type on-the-fly if necessary. Whether all those different files generated from the same "origin blob" are permanently stored, just cached or neither, is not prescribed by this RFC and should be decided for the particular backend, server and product circumstances.
From the viewpoint of the client, the server side representation of the blob repository looks like the following tree, and is accessible by URLs like "https://some_blob_repo.domain/blobs/<T>/<hash>":
blobs
+> 1/
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> ...
+> 2/
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> ...
+> some_other_type/
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> ...
+> yet_another_type/
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> ...
Blob rewriting scenarios
There are the following potential migration scenarios that this RFC is addressing:
- Full migration of blob type <T> to type <U> as part of an OTA: In this case, the blob storage determines the type of the currently present blobs. Subsequently it can indicate to the package management stack whether a particular blob needs to be re-downloaded during an OTA, following the mechanism described in RFC-276.
- A more generalized case of this is the situation that the blob storage currently contains blobs in multiple different blob formats, i.e. the migration is from type <Ta, Tb, Tc, Td, ...> to type <U>. This is covered by the same concepts and implementations, though: The blob storage will determine that a blob is not in the desired format <U> and will indicate to the package management stack that it needs to be replaced.
- Gradual migration: It is important to note that a migration of all the blobs as in the previous bullet points is not necessarily required or even desired for the general case. One particular example where complete migration as part of an OTA could be required is when a newly introduced blob type offers far superior compression and a particular product is known to be tight on storage. However, since the blob storage for a product will support all blob types that have previously been used on a product and that have not yet been completely replaced, there is no general requirement for the blobs stored in blobfs/fxblob to be of the same type. Thus, in most cases, only the newly downloaded blobs are in the desired format. Over time, the number of blobs in the previously stored format decreases continuously as they are garbage collected after having been replaced by a newer blob which has a different hash due some change in the blob itself.
The first point describes the scenario that, as part of an OTA, every blob available in the blob storage will be re-downloaded in the new delivery type, and replace the existing one. The latter ("gradual migration") would not overwrite the existing blobs. This is an important distinction to address a particular challenge: With gradual migration, it is difficult to reason about the exact amount of free storage space a device's blob storage has at any given time. For devices with ample storage, this is typically not an issue, but with devices exhibiting challenging storage constraints, it might be. Hence, migrations to any upcoming type <T> will be able to happen either gradually or all-at-once, following the steps and procedures laid out in RFC-276.
The decision of whether a migration is going to be gradual or requires a complete rewrite will depend on a configuration setting for assembly, just like setting the desired blob type for a product. As a result, the blob storage can communicate to the package management stack which blobs need to be re-downloaded in the new encoding, employing the same mechanism defined in RFC-276:
fn do_ota() {
...
for hash in list_of_expected_hashes {
let blob = match get_blob_by_hash_from_blob_storage(hash) {
(Some(blob), info) if info.desired_type => blob,
_ => {
let blob = fetch_blob_from_server(hash);
write_blob_to_blob_storage(&blob);
blob
}
};
}
...
}
For a gradual migration, the info.desired_type value would always be true.
This would avoid re-downloading any blob that already exists in any encoding in
the blob storage.
Risk mitigation for gradual blob migrations
The section above introduces the concept of gradual migrations, which was deliberately not scoped in RFC-276. There is a conceptual difficulty when doing gradual migrations which needs to be looked at separately. To illustrate the challenge, this following scenario considers the situation where:
- Multiple blob type migrations happen over a longer period of time (Type A -> Type B -> Type C), and additionally:
- At no point in time, every blob on the blob storage was stored as Type B.
- An automated size check mechanism estimates based on the sizes of the compressed build artifacts of the current system image and the intended update whether an OTA will fit on a device or not. It conceptually - for counting purposes - views the available space as two equally sized ranges which must be large enough to hold the "old" set of blobs (before an OTA is performed) and a "new" set of blobs (the blobs the system requires after booting into the updated version).
The following illustration depicts this situation over time.
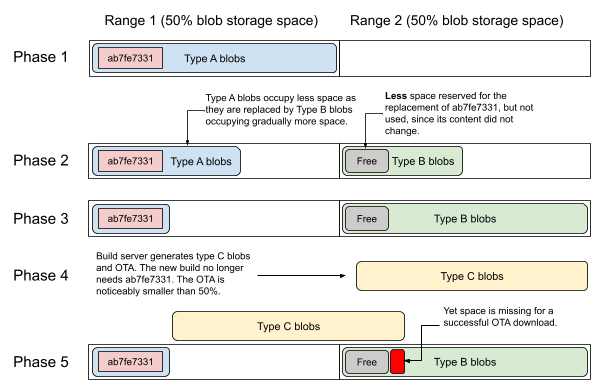
The process that would lead to this difficulty is as follows:
- Phase 1: Before the first migration is started, every blob on the system is stored as type A. Before the OTA is installed that begins the gradual migration to type B, the size checking mechanism calculates that the required 50% of storage should be available on the devices. The OTA is performed, the device reboots into the new system that uses the new type B blobs whenever a new blob is downloaded.
- Phase 2: Gradually, over the course of multiple OTA updates, the hashes of most of the blobs change. Subsequently the type A blobs are gradually replaced by type B blobs. However, there is a particularly large type A blob ("ab7fe7331..." in the picture) which does not get replaced on the devices that have it already stored in type A because its content does not change.
- The builds however, which are produced by a builds server, contain blob ab7fe7331 in type B (and devices flashed with fresh builds also contain blob ab7fe7331 in type B). If blob ab7fe7331 requires less storage with type B than than with type A (e.g. because of better compression), the size checking mechanism would underestimate the storage requirement for blob ab7fe7331 on many of the deployed devices that still hold blob ab7fe7331 in type A.
- Phase 3: Over the course of several OTAs, with the exception of blob ab7fe7331, all blobs have been updated to type B.
- Phase 4: Now the migration to type C is planned. Also, blob ab7fe7331 is no longer part of the OTA since it is replaced by a smaller blob with a different hash. Subsequently, the whole OTA to the new version now requires slightly less than 50% capacity.
- Phase 5: Because blob ab7fe7331 is still in type A format and is required for the running system until the next boot, the download of the blobs for the OTA will fail, since the combined size of "blob ab7fe7331 + all type B blobs + all type C blobs - reserved space for blob ab7fe7331 in type B format" is larger than 100%.
This scenario is not expected to be a real world problem with systems that have ample storage, but it becomes relevant for Fuchsia-based products that tend to have full OTA sizes close to 50% of the blob storage capacity.
It is noteworthy that the above scenario happens due to the progressive nature of the described size check mechanism, namely that it calculates storage requirements based on the "current" and "next" set of blobs. One could come up with a conservative mechanism that records the largest compressed size for every blob that was ever delivered to a fleet of a product, and calculates the size requirements under the assumption that a device could have the largest possible set of blobs for all hashes that ought to be available in its blob storage.
The disadvantage of this mechanism is that it would inevitably lead to a lot of false positives in the sense that in all likelihood not a single device really has this largest possible set of blobs. This subsequently would force the development teams to work on a much tighter storage budget than realistically necessary.
Because of the challenge illustrated above with storage constrained devices, this RFC proposes to have a policy in place to always perform full migrations with these devices. This makes reasoning about free storage straightforward.
If a full migration is impractical because of product-specific requirements (e.g. violation of a critical rollout plan), a full migration for storage constrained devices before the migration to type C shall be completed, for example in phase 3 of above illustration. That way, it would be ensured that the progressive size checking mechanism's calculation is realistic and matches the actual allocation on the devices. The product release teams need to plan their release schedule and procedure accordingly.
Implementation
The implementation of this RFC is intended to be completed in parallel with RFC-276 the migration from type 1 to type 2 blobs. Because in many regards this RFC is a generalization of the concepts described in the former, it is efficient to implement the two together. Subsequently, even though this RFC does not impose unconditional stepping stones, the implementation will be embedded in the first phase of the three phase approach of RFC-276, conceptually like this:
- Implementation of support for blob overwrite and updatable status in the blob storage layer (Local Storage).
- Implementation of support in the package management stack for type <T> delivery blobs (SWD).
- Implementation of support for blob type conversion from type <T> into
<U> via
ffx. (SWD). - Support for creation of product bundles with type <T> delivery blobs
(Assembly).
- The default settings are not changed as part of this RFC.
- Support for serving type <T> delivery blobs (Infrastructure).
- The server side infrastructure will continue to be able to serve the
previous default blob type if a client requests it, if necessary by
means of on-the-fly conversion using
ffx.
- The server side infrastructure will continue to be able to serve the
previous default blob type if a client requests it, if necessary by
means of on-the-fly conversion using
- Support for exposing the status flag for the blob rewrite policy (Local Storage).
When this is completed, and it is confirmed that the server side infrastructure can serve type <T> blobs, the product configuration for the designated consumers of type <T> is adapted, causing subsequent builds to begin fetching type <T> blobs instead of the previous type.
Performance
The functionality as proposed by this RFC is expected to have some performance impact for some scenarios, but due to the generic nature of the not-yet-defined upcoming blob types we cannot quantify them precisely at this point. However, qualitatively, the following can be expected:
- Whenever a full blob type migration (i.e. all blobs are rewritten) is performed as part of an OTA, it will take longer than usual as all blobs in the previous format will be re-downloaded and re-written.
- Whenever a new blob type is introduced with a different encoding than an existing one, the performance during assembly might change. It might get slower or faster, mildly or significantly, depending on the particular details. This cannot be determined at this point and is outside of the scope of this RFC.
- The introduction of every new delivery blob type will increase the number of
tests to ensure the new type works as expected. This would scale slightly
higher than linearly, i.e. the test suite that is routinely run against each
of the existing blob types would now be run against the newly introduced
type as well. On top of this, some additional tests of migrations from
specific types to the new type and fallback to other types may be tested as
needed, too.
- Depending on the requirements, it may not be necessary to test every blob type on every product / board configuration. This is to be determined on a case by case basis, and this RFC is intentionally not setting the requirements for the resulting test matrix. The product and test teams should ensure that the selected blob type for their product is supported by the testing procedures and may choose to opt out of testing configurations that are definitely out of scope for a particular product.
Ergonomics
As described in the previous, the ffx tool has gained for delivery blobs,
initially supporting type 1 and later 2, where the support for type 2 is not
completed as of this writing.
This RFC mandates that the introduction of additional blob types in local
storage and software delivery shall always come with support in ffx for the
new type. Hence, for any given pair of blob types <T>, <U> the following
should be always possible. Note that the commands are conceptual examples only.
The upcoming implementation may choose different syntax, subcommand naming and /
or offer additional functionality:
# Encoding an uncompressed blob into <T>
$ ffx package blob compress --type <T> --output <output_file> raw_input_file
# Encoding an uncompressed blob into <U>
$ ffx package blob compress --type <U> --output <output_file> raw_input_file
# Recompressing a <T> blob into <U>
$ ffx package blob decompress --output raw_blob v1_compressed_input_file
$ ffx package blob compress --type <U> --output <output_file> raw_blob
As with previous blob types, ffx will be able to detect the blob format it
finds, hence it will not need explicit passing of a --blob-format argument
when decoding.
Unlike previous RFCs, this RFC will not change the default blob type for either
ffx package blob compress or ffx product. If one of the newly defined blob
types are to be used by ffx or assembly, they need to be enabled explicitly
via command line arguments or assembly configuration.
Note that a minor potential change to the ergonomics is under consideration as
of this writing: Currently, as mentioned in the above example, the ffx command
implies that blob types are merely about compression. While this was initially
the case, it is not necessarily so. For instance, the generation of delta blobs,
i.e. a binary diff between two blobs as a measure of saving data transfer
bandwidth, is an obvious candidate for a blob type as well. Subsequently, it is
being considered to call the ffx subcommand ffx package blob encode and
decode, respectively, in the future.
Backwards Compatibility
As with previous changes to the on-disk blob format, introduction of new types <T> shall not interrupt the operation of Fuchsia-based products or development workflows. Hence, the design and implementation plan strives to ensure backwards compatibility.
Production
Since the introduction of the blob types described in this RFC does not necessarily come with a migration of a product from another blob type, this RFC is not prescriptive in terms of whether a new blob type demands a stepping stone or not. This is delegated to the product-specific circumstances.
However, we do require the server side infrastructure to ensure that a product
can always download a set of blobs that it understands. As described in the
Design section above, the server backend will leverage ffx to convert blob
types on the fly when the client requests a particular format.
This approach allows us to support migrations essentially indefinitely: A stepping stone is never needed to introduce a new blob type, but only to fully retire a no longer used blob type, i.e. dropping server side support for it. The reason for this is an update from a very old version might not know what blob type it will be upgraded to, and hence won't request the new blob type during a system update to the then-newest version. This can be resolved by force-updating it to the last version supporting the retired blob type first. But again, this is not necessarily the general case with all product-specific blob types. If this situation arises, though, the procedures as laid out in RFC-276 shall be followed.
Development
During migration, the development host will change from publishing type <T> to type <U> delivery blobs. Similar to RFC-207 and RFC-276 the development host will only support one blob format at a time. Consequently, the host-side server may not retain older blob formats for backward compatibility.
Unlike production builds, which can be forced through a stepping stone if
necessary, development workflows lack a mechanism to enforce updates through a
specific build. Therefore, fx ota will rely on device-side fallback, meaning
fxblob/blobfs will handle the necessary actions based on the incoming blobs.
Security considerations
This RFC does have implications on the attack surface beyond the scope explained in RFC-207. It allows changing the on-disk format of blobs without special preparations and follow-up-RFCs. Thus, the teams who intend to introduce a new blob type should coordinate closely with security teams, especially on the following points:
- In most cases it is expected that the introduction of new blob types comes with the introduction of a new encoder (e.g. compression algorithms) for the blobs. Such encoders have been successfully exploited in the past. Thus, the introduction of a new encoding should go through security review to verify the particular fitness for the intended use. This applies to review of the format itself, as well as the implementation and the roll-out.
- The encoders and decoders need to be continuously updated to make sure the fixes for all known vulnerabilities are included in Fuchsia.
- Fuzzing should be performed on all supported blob formats to discover potential vulnerabilities as early as possible.
De-facto-deprecation of blob types
When introducing new blob types, there is always the lurking issue of new blob types de-facto-deprecating an old blob type. While it is explicitly made clear above that blob types typically reflect different use cases, and some type is not intended to succeed other types, it is entirely true that this might de facto happen.
For instance, a newly introduced compression algorithm might outpeform an already established one in all metrics relevant for a specific product. If this happens, and the Fuchsia platform continues to support the previous algorithm, it must be ensured that the code handling the other algorithm continues to be updated and monitored for security issues to prevent the possibility of downgrade attacks. The testing section contains additional details on the tests for this type of attacks.
Thus, when a new blob type is introduced which could cause a de-facto-deprecation of another blob type, e.g. because of overlapping technical scope, the product and release teams should consider introducing a stepping stone. This stepping stone would disable the previously used blob type on the product after switching to the new one, i.e. production devices will refuse to write the old blob type to blob storage during an OTA.
Privacy considerations
This RFC does not include any changes related to privacy. The delivery blob type has been communicated between the client and server since RFC-207. Furthermore, this RFC does not propose any additional modifications to data transfer.
Testing
Since this RFC is a logical extension of previous RFCs, the test concept described in RFC-276 applies for this RFC as well. It again will cover both automated and manual testing.
Automated testing
The automated test code developed for RFC-207 and RFC-276 is going to be extended to cover the testing of newly introduced blob types. Since the latter RFC has already been designed under the assumption that additional blob types are going to be developed and deployed eventually, the test concept was specifically designed to be generic to this requirement. This means testing scenarios like migrations from type <T> to <U> are already part of the design, and extending the automated tests to include new blob types is trivial. Thus, no additional changes to the already designed test concept are proposed by this RFC.
Blob downgrade attack tests
Upon implementation of this RFC, adversarial tests to verify the resilience against blob downgrade attacks will be introduced. Specifically, a likely scenario is the de-facto-deprecation of a blob type for a product, as explained earlier in this RFC: When a product is moved off a blob type to a different one, there is a strategic reason behind it. To cover this situation, there will be a high level test that confirms that receiving a type <T> blob when a type <U> blob is requested results in an error, and the received type <T> blob is not written to disk.
Note that there is a section on future work, suggesting the introduction of policies for accepting multiple blob types, having preferences for them, and the definition of policies regarding acceptable and unacceptable blob types. If / when this is implemented, the blob downgrade attack tests need to be extended accordingly, to ensure the resulting cases are fully covered.
Manual testing
For products, the manual OTA tests conducted by the test team and subsequent dogfood builds will verify the test results from automated testing and confirm that introduction of a new blob type does not lead to unforeseen problems. The manual tests are performed for concrete product requirements, i.e. they will not verify every possible migration permutation manually.
Documentation
Upon acceptance of this RFC, the documentation of BlobFS and OTA updates will be reviewed and, if necessary, updated to reflect the details that change with the introduction of new blob types.
Drawbacks, alternatives, and unknowns
Alternatives
Alternatives to server side support for product-specific blob types
There is a possible solution to shipping product-specific blobs to devices
without server side awareness of the entire concept of delivery blobs. If the
blob hash was calculated not from the raw binary content alone, but from the
tuple (content, blobType), different blob types (with different settings and /
or for specific products) would end up having different names. In this
implementation, the server would not have to distinguish between different
types, and instead would be able to serve everything from what looks like only
one directory containing all blobs:
blobs/
+> ...
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> 76d4f97c1aaf486fabeabdce2095aa9d736f72e1257acd654dcbbddeb4564c28
+> ...
In this example, the two listed files would have the same payload, yet their hashes, and hence filenames, would be different due to the different blob type. The blob server could serve them to clients from the same directory.
Sticking to the original Fuchsia design, and deriving the name exclusively from the hash of the raw payload (i.e. without compression or encoding) would result in a something that looks more like multiple directories, named after the delivery blob type:
blobs
+> 1/
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> ...
+> 2/
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> ...
+> next_generation_type/
+> a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
+> ...
Both designs are entirely feasible, but changing the current design that is built into the Fuchsia platform and the tooling today does not come with significant obvious benefits that would justify additional engineering effort.
Thus, this RFC keeps the current design, and continues to derive the file names from the raw content alone. From the viewpoint of the client, the design continues to leverage simple path separators to avoid ambiguity.
Future work
Policies for accepting and refusing downloaded blob types
With the possible existence of many different blob types, a possible future requirement is the automatic fallback to other types if the requested blob type is not available on the server. At present, the blob downloader expects the blobs to be available in the specified format and will error out if it is unavailable.
However, when implementing a scheme where multiple types may be accepted and the client can communicate preferences in order, as discussed in the next section, being explicit about defining policies for the products would be useful. These policies might be helpful in preventing downgrade attacks by denying the download and storage of de-facto-deprecated formats by allowing only very specific alternate types. While this RFC is not prescriptive of the precise technical implementation, it is suggested that these policies can be given in a clear, concise, explicit way, instead of implicitly scattered across multiple compilation units or components.
It is important to note that the implementation of such functionality would require the extension of tests for the protection against blob type downgrade attacks, as described in the section on testing.
Non-scalar negotiation of blob types between client and server
The design described in this document relies on the client communicating the desired delivery blob type to the server via a scalar separator in the URL, for example URLs like:
https://some-package-server.com/blobs/next_generation_type/a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
The advantage is a very clear and easy to understand request scheme and a straightforward implementation. Although there are currently no known specific requirements, there is potential for future needs where the selection of blobs delivered to a client depends on multiple factors rather than a single scalar value. For instance, a client might hypothetically send a request to the update server specifying a preference for delivery type "AB-positive" while indicating that type "B-negative" would be an acceptable alternative. This could be enabled by several possible implementations, two of which are:
- More complicated request URLs to convey the necessary information. While this is possible, it would be rather unconventional, compared to the solution in the next bullet point.
- Additional http headers which are transferred to the server with the
client's request. A common implementation of this relies on MIME types and
http
Acceptheaders, see the section below.
Note that due to the current absence of a concrete requirement, this RFC does not mandate an implementation and classifies this as potential future work.
Content negotiation via MIME types and Accept headers
A potential implementation to satisfy this request leverages vendor-specific custom MIME types and the http "Accept" header. As a concrete example, the remainder of this section assumes that we are looking at three different blob types:
- Uncompressed blobs.
- Compressed blobs, using the lz4 algorithm. Compressed blobs, using the zstd algorithm, with variadic compression levels and chunk sizes.
With an update server implementing the suitable content negotiation counterpart, there could be MIME types for these three mentioned types, like:
application/vnd.fuchsia-blob.rawapplication/vnd.fuchsia-blob.raw+lz4application/vnd.fuchsia-blob.raw+zstd; level=<L>; chunk=<C>
In this implementation, blob types would no longer be described by simple terms
like "type 1". Subsequently, the blob header might no longer contain just an
u32 integer to denote the blob type. Instead, it could gain an additional
field, potentially of variable-length to contain the string describing the blob
type.
The system update client would then request a URL, conceptually like:
https://some-package-server.com/blobs/<doesnt_matter>/a68945271ac8812c85b4d7239c2ac919030ea7bc6d0bd4cec038b0643dc1e728
But it would send a http request with a header containing an Accept header,
for instance:
Accept: application/vnd.fuchsia-blob.raw+zstd; level=3, application/vnd.fuchsia-blob.raw+lz4; q=0.8, application/vnd.fuchsia-blob.raw; q=0.5
In this scenario, the update server could basically ignore the URL segment
between blobs/ and the hash value and simply serve the hash adhering to the
preferences as communicated in the Accept header.
For handling the transmission of the blobs from the blob server to the target device and into its storage, multiple possible options seem viable, with their own pros and cons, in particular the following ones:
- The delivery blob format remains unchanged. The package management stack maintains a table mapping delivery blob types to MIME type strings. The storage code maintains a translation of what delivery blob types mean in terms of actual code for the blob file systems. The main advantage of this scheme is that no change to the current delivery blob implementation would be necessary in either storage or package management. What would change is that when requesting blobs, the resolver / blob downloader would query said table to determine the appropriate mime type string(s) when requesting blobs from the server. The downside is that the mapping between a MIME type and the actual code is split between the package management and the storage code. Whenever a new blob type is introduced or decommissioned, this requires to be kept in sync manually. This might be slightly more error-prone than the other option described below, but it still very straightforward, making problems resulting from this split quite unlikely.
- The delivery blob format could encapsulate the MIME-type directly. This would
require a change, as given in the example illustrated below. In this
implementation, the integer type field we use today to map to the enum
that defines the blob type, would still be used for legacy types. A reserved
magic value in this field would indicate that the MIME type field is to be
used instead of the legacy type field. The advantage of this is that there
would be no table to map a MIME type to an enum in the package management
stack and from there to the actual functionality in storage. Instead,
storage could immediately
matchon the MIME type. The downside is the additional complication of the blob header introducing another field of variable length, and the necessary change of the blob type itself.

This RFC does not mandate an implementation using MIME types and Accept
headers right now, but offers an outlook at possible future implementations in
case the concrete requirement for content negotiation arises. If so, the
specifics of the implementation will be discussed in a later RFC or design
document.
Opportunistic online migration
This RFC focuses on the migration of "server side provided" migrations, assuming that in migrations from type <T> to type <U> all blobs for type <U> are provided via the blob server, and following the design and software distribution mechanisms as laid out in RFC-207 (Offline blob compression).
However there are scenarios where it might be favorable to perform an online (i.e. on-device) migration instead of downloading the type <U> blobs from the server, for instance:
- For the most important metrics of a particular migration scenario (e.g. minimizing overall network activity, devices with particularly powerful processors, very efficient compression algorithms, etc.) it is beneficial to perform an online migration and re-encode the blobs on the device itself.
- As a special case of the previous point there is the scenario where type <U> is an unencoded / uncompressed blob. In this case it is almost always beneficial to perform the migration scenario online on the device itself without downloading the uncompressed blobs from the blob server.
These migrations are most likely conceptually simpler than the ones described in RFC-276 or in this RFC, but they are intentionally out of scope for this RFC. Since at least some of these scenarios can be implemented without changing the way software is delivered to a device, they might not necessarily require subsequent RFCs prior to implementation.