
| RFC-0196:FIDL 大型訊息 | |
|---|---|
| 狀態 | 已接受 |
| 區域 |
|
| 說明 | 支援透過 FIDL 通訊協定傳送大型訊息。 |
| 問題 | |
| Gerrit 變更 | |
| 作者 | |
| 審查人員 | |
| 提交日期 (年-月-日) | 2022-06-28 |
| 審查日期 (年-月-日) | 2022-10-27 |
摘要
目前,FIDL 語言會將透過管道和通訊端等以 Zircon 為基礎的傳輸方式傳送的訊息大小限制為 64KiB。本文提出高階設計,用於處理任意大小的訊息,即使訊息超過基礎傳輸的訊息位元組上限也沒問題。方法是提升類似於現有模式的解決方案,使用 fuchsia.mem.Data,以自動推斷 FIDL 語言支援。
提振精神
目前透過連線傳送的所有 FIDL 訊息大小上限為 ZX_CHANNEL_MAX_MSG_BYTES,相當於 64 KiB,這是從可透過 Zircon 管道傳送的訊息大小上限衍生而來。如果訊息超過這項限制,就會無法編碼。
目前解決這個問題的常見方法是透過 zx.handle:VMO 或 fuchsia.mem.Data 將任意大小的資料做為 Blob 傳送,而基礎 VMO 本身則包含要傳送的資料 Blob。這些 Blob 通常包含結構化資料,使用者希望以 FIDL 表示及編碼/解碼,但無法這麼做,因此必須自行手動轉換。目前 fuchsia.git 中有大量使用這些包裝函式型別的案例。
缺乏大型訊息支援功能會導致一些問題。其中最重要的是,很少需要傳送大型訊息的通訊協定,在技術上卻能夠傳送,因此造成大量錯誤。舉例來說,這類錯誤包括非常大的網址,或 Wi-Fi 掃描期間產生的大型網路清單。凡是需要採用 :MAX 大小 vector 或 string 的 API,都可能發生這個問題,其他極端情況也可能導致這個問題,例如只有極少數欄位會填入資料的 table 版面配置。一般來說,凡是需要以訊息形式接受使用者資料,但無法證明訊息小於 64 KiB 的項目,都可能受到這種故障模式影響。
透過 VMO 傳送未輸入型別的資料 Blob 不符合人體工學,因為這樣會遺失所有型別資訊,必須在接收端手動重建。使用者必須自行編碼訊息、將訊息套件到另一個 FIDL 訊息中,然後在另一端反向重複這個程序,而不是利用 FIDL 描述資料形狀,並抽象化 encode->send->decode->dispatch 管道。舉例來說,ProviderInfo
API 具有子類型 InspectConfig 和 InspectSource,
目前分別以 fuchsia.mem.Buffer 和 zx.handle:VMO 表示,
但代表可由 FIDL 說明及處理的結構化資料。
使用 zx.handle:VMO 或 fuchsia.mem.Data 會導致僅限資料的 FIDL 型別強制攜帶 resource 修飾符。這會對繫結 API 造成下游影響,導致 Rust 等語言中產生的型別無法衍生 Clone 特徵,即使這些型別應該可以衍生也一樣。
支援大型郵件不足導致的錯誤和人體工學問題十分普遍。在草擬本 RFC 時進行的調查顯示,至少有 30 個案例 (包括過去和現在) 顯示,更強大的大型訊息支援功能有助於 FIDL 使用者。
利害關係人
輔導員:hjfreyer@google.com
審查人員:abarth@google.com、chcl@google.com、cpu@google.com、 mseaborn@google.com、nickcano@google.com、surajmalhotra@google.com
諮詢對象:bprosnitz@google.com、geb@google.com、hjfreyer@google.com、jmatt@google.com、tombergan@google.com、yifeit@google.com
社交化:五個團隊 (元件解析器、DNS 解析器、驅動程式庫開發、WLAN SME 和 WLAN 政策) 已使用這項設計審查原型:
- 元件解析器:geb@google.com
- DNS 解析器:dhobsd@google.com
- 驅動程式開發:dgilhooley@google.com
- WLAN 政策:nmccracken@google.com
- WLAN 專家:chcl@google.com
此外,我們也訪談了超過 30 位現有 fuchsia.mem.Data 和 fuchsia.mem.Buffer 類型的使用者,收集設計意見回饋,並瞭解使用案例是否合適。
設計
本文中的關鍵字「MUST」、「MUST NOT」、「REQUIRED」、「SHALL」、「SHALL NOT」、「SHOULD」、「SHOULD NOT」、「RECOMMENDED」、「MAY」和「OPTIONAL」應按照 IETF RFC 2119 的說明解讀。
訊息溢位是傳輸層級的問題。訊息是否屬於大型訊息,以及如何妥善處理這類訊息,在 Zircon 管道、驅動程式庫架構、Overnet 等之間差異很大。也就是說,將特定方法要求或回應稱為「大型」並非抽象陳述:該方法所屬的通訊協定必須一律明確定義「大型」。
以下說明訊息如何聲明「我相較於運送我的傳輸方式預期大小而言偏大,因此需要特殊處理」。在指定通訊協定的 *.fidl 檔案中,介面定義時間和任何實際溢位的訊息執行個體執行階段,都必須可辨識這項宣告。
具體來說,在採用這項設計之前,寄件者可能會傳送完全有效的訊息,但訊息超過基礎傳輸的訊息位元組上限,導致難以偵錯的意外 PEER_CLOSED 執行階段失敗。完成這些變更後,fidlc 編譯器會靜態檢查酬載類型是否可能大於傳輸的訊息位元組上限,如果是,則會產生特殊的「溢位」處理程式碼來因應這種情況。這個模式可為大型訊息啟用次要的執行階段訊息傳送機制,藉此使用無界側邊通道 (以 Zircon 管道來說,就是 VMO) 儲存訊息內容。這個新的訊息傳送路徑完全新增在產生的繫結程式碼「內部」,因此可同時維持 API 和 ABI 相容性。FIDL 方法實作人員現在可以放心,不會因達到任意位元組大小限制而觸發 PEER_CLOSED,導致可分配的訊息無法傳送。
電線格式變更
系統會在 FIDL 交易訊息標頭的 dynamic flags 部分新增一個稱為 byte_overflow 標記的新位元。這個標記翻轉時,表示目前保留的訊息只包含訊息的控制層,訊息的其餘部分則儲存在另一個可能不連續的緩衝區中。
這個獨立緩衝區的位置和存取方式取決於傳輸方式。如果 byte_overflow 旗標處於啟用狀態,傳輸中的控制層訊息必須包含 16 位元組的交易訊息標頭,後面接著額外的 16 位元組附錄訊息,說明大型訊息的大小。也就是說,這則訊息「必須」正好是 32 個位元組:預設 FIDL 訊息標頭,後接所謂的 message_info 結構體,其中包含三筆資料:用於標記的 uint32、預留的 uint32 (用於指定附加至訊息的控制碼數量,但不包括溢位緩衝區),以及指出 VMO 中資料大小的 uint64:
type MessageInfo = struct {
// Flags pertaining to large message transport and decoding, to be used for
// the future evolution and migration of this feature.
// As of this RFC, this field must be zeroed out.
flags uint32;
// A reserved field, to be potentially used for storing the handle count in
// the future.
// As of this RFC, this field must be zeroed out.
reserved uint32;
// The size of the encoded FIDL message in the VMO.
// Must be a multiple of FIDL alignment.
msg_byte_count uint64;
};
由於需要產生額外的控制代碼來指向溢位緩衝區,大型 FIDL 訊息可能只會附加 63 個控制代碼,而不是通常的 64 個。這種做法不夠完善,會讓使用者感到意外,而且只會透過執行階段錯誤回報。我們致力於開發核心改善項目,以修正未來尖銳的邊緣,彌補這個不幸的特殊情況。
byte_overflow 旗標必須佔用動態旗標位元陣列中的位元 #6 (即倒數第二個最重要的位元)。位元 #5 保留供日後使用,但目前未使用。handle_overflow這個位元不得用於其他用途。
執行階段要求
如果解碼期間違反下列條件,必須導致 FIDL 傳輸錯誤,並立即關閉通訊管道。如果設定 byte_overflow 旗標,如上所述,控制層訊息的大小必須正好是 32 個位元組,訊息主體必須透過其他媒介傳輸。
如果是 zircon 管道傳輸,位元組溢位緩衝區的媒介必須是 VMO。也就是說,控制層訊息中隨附的控制代碼數量必須至少為一。最後一個控制代碼所指向的核心物件必須是 VMO,且接收器從該 VMO 讀取的位元組數量必須等於 message_info 結構體的 msg_byte_count 欄位值。如果已知訊息有界限,這個值必須小於或等於相關酬載的靜態推斷最大大小。
訊息傳送者必須透過 zx_vmo_create syscall 鑄造新的 VMO,然後立即透過 zx_vmo_write 填入訊息主體。他們必須確保代表溢位 VMO 的控制代碼沒有正確的 ZX_RIGHT_WRITE。
在接收端,訊息收件者必須使用 zx_vmo_read 讀出訊息所含資料。因此,透過鋯石管道傳送的一般 FIDL 訊息只需要兩個系統呼叫 (寄件者為 zx_channel_write_etc,收件者為 zx_channel_read_etc),但位元組溢位訊息需要更多系統呼叫 (寄件者為 zx_channel_write_etc、zx_vmo_create 和 zx_vmo_write,收件者為 zx_channel_read_etc、zx_vmo_read 和 zx_handle_close)。這項罰款金額相當高,但日後進行最佳化 (例如改善 zx_channel_write_etc API),應可挽回部分損失。訊息接收器不得嘗試寫入收到的溢位 VMO。
程式碼生成變更
對於最大位元組計數可能大於通訊協定傳輸限制的任何酬載訊息,FIDL 繫結實作必須產生溢位處理常式。為此,FIDL 訊息大致可分為三類:
- 有界: 最大累計位元組計數一律已知的訊息。
這個類別包含大部分的 FIDL 訊息。對於這類訊息,繫結產生器必須使用計算出的訊息位元組數上限,判斷是否要納入在編碼時設定
byte_overflow旗標的功能,以及是否要在解碼時檢查該旗標。具體來說,如果累計位元組計數上限大於通訊協定傳輸的限制 (以 Zircon 管道來說為 64KiB),則產生的程式碼必須包含在編碼時設定byte_overflow旗標的功能,以及強制解碼時的旗標檢查;否則不得包含這些功能。 - 半有界: 訊息的累計位元組數上限只會在編碼時得知。這個類別包含任何原本會受限的訊息,但會遞移包含
flexible union或table定義。對於這類訊息,繫結產生器「必須」使用訊息的計算最大位元組數,判斷是否要納入在編碼時設定byte_overflow標記的功能,但這個標記「必須」一律在解碼時檢查。 - 無界限: 最大累計位元組計數永遠無法得知的訊息。這個類別包含任何遞迴定義或無界
vector遞迴包含的訊息。對於這類訊息,產生的繫結程式碼必須一律包含在編碼時設定byte_overflow標記的功能,且必須一律在解碼時檢查該標記。
@transport("Channel")
protocol Foo {
// This request has a well-known maximum size at both encode and decode time
// that is not larger than 64KiB limit for its containing transport. The
// generated code MUST NOT have the ability to set the `byte_overflow` on
// encode, and MUST NOT check it on decode.
BoundedStandard() -> (struct {
v vector<string:256>:16; // Max msg size = 16+(256*16) = 4112 bytes
});
BoundedStandardWithError() -> (struct {
v vector<string:256>:16; // Max msg size = 16+16+(256*16) = 4128 bytes
}) error uint32;
// This request has a well-known maximum size at both encode and decode time
// that is greater than the 64KiB limit for its containing transport. The
// generated code MUST have the ability to set the `byte_overflow` on encode,
// and MUST check it on decode.
BoundedLarge() -> (struct {
v vector<string:256>:256; // Max msg size = 16+(256*256) = 65552 bytes
});
BoundedLargeWithError() -> (struct {
v vector<string:256>:256; // Max msg size = 16+16+(256*256) = 65568 bytes
}) error uint32;
// This response's maximum size is only statically knowable at encode time -
// during decode, it may contain arbitrarily large unknown data. Because it
// is not larger than 64KiB at encode time, the generated code MUST NOT have
// the ability to set the `byte_overflow` on encode, but MUST check for it on
// decode.
SemiBoundedStandard(struct {}) -> (table {
v vector<string:256>:16; // Max encode size = 32+(256*16) = 4128 bytes
});
SemiBoundedStandardWithError() -> (table {
v vector<string:256>:16; // Max encode size = 16+32+(256*16) = 4144 bytes
}) error uint32;
// This response's maximum size is only statically knowable at encode time -
// during decode, it may contain arbitrarily large unknown data. Because it
// is larger than 64KiB at encode time, the generated code MUST have the
// ability to set the `byte_overflow` on encode, and MUST check for it on
// decode.
SemiBoundedLarge(struct {}) -> (table {
v vector<string:256>:256; // Max encode size = 32+(256*256) = 65568 bytes
});
SemiBoundedLargeWithError(struct {}) -> (table {
v vector<string:256>:256; // Max encode size = 16+32+(256*256) = 65584 bytes
}) error uint32;
// This event's maximum size is unbounded. Therefore, the generated code MUST
// have the ability to set the `byte_overflow` on encode, and MUST check for
// it on decode.
-> Unbounded (struct {
v vector<string:256>;
});
};
ABI 和 API 相容性
這項設計全面推出後,將完全相容於 ABI 和 API。由於任何將先前繫結的酬載轉換為無界或半界酬載的變更 (例如將 struct 變更為 table,或變更 vector 大小界線),都已是 ABI 中斷變更,因此一律為 ABI 安全。
對於無界或半無界酬載,無論大小為何,系統一律會在訊息解碼期間檢查 byte_overflow 標記。也就是說,即使演進版本新增了不明資料,導致訊息從解碼器的酬載類型來看異常龐大,連線一端編碼的任何訊息都可能在另一端解碼。
在推出期間的過渡期,連線的一方可能具有可辨識大型訊息的 FIDL 繫結,另一方則沒有,因此大型訊息將無法解碼。這與目前的情況類似,這類郵件會在編碼期間失敗,但現在失敗的來源會稍微遠一點。
我們認為,在中間推出期間,解碼失敗的風險很低,因為大多數會傳送大型訊息的 API 都已採用通訊協定層級的緩解措施,例如分塊。主要風險向量是通訊協定開始透過現有方法傳送現在允許的大型訊息。這類通訊協定應改為採用可傳送大型訊息的新方法。
設計原則
這項設計符合幾項重要原則。
用多少付多少
FIDL 語言的主要設計原則是只須依實際用量付費。本文所述的大型訊息功能,即是為了實現這個理想而設計。
使用有界酬載的方法不會因此 RFC 而降低效能。如果方法使用半受限或不受限的酬載,但傳送的訊息大小未超過通訊協定傳輸的 bye 計數限制,則只需支付接收端單一位元旗標檢查的費用。只有實際使用大型訊息溢位緩衝區的訊息,才會受到效能影響。
如果使用者不需要支援大型訊息 (也就是可能以 FIDL 表示的大多數方法/通訊協定),則無論是執行階段效能成本,還是編寫 FIDL API 時產生的精神負擔,都不需要支付任何費用。
不需遷移
現在,凡是可能使用大型訊息的任何酬載,都已在各處啟用大型訊息,現有 FIDL API 或其用戶端/伺服器實作項目都不需要遷移。先前會導致 PEER_CLOSED 執行階段錯誤的情況,現在「可以正常運作」。
量身打造的運輸服務
這項設計可彈性因應現有和推測的各種傳輸需求。舉例來說,只要翻轉 byte_overflow 位元,且傳輸層知道如何排序包含封包的溢位,即可透過網路傳送多封包訊息等慣例。
實作
這項功能將透過實驗性 fidlc 標記推出。每個繫結後端都會經過修改,以處理這個 RFC 針對特定指定實驗旗標的輸入內容所指定的大型訊息。一旦這項功能穩定性足夠,系統就會移除這個標記,開放一般使用者使用。
這個屬性不應需要額外的fidlc支援,因為它只會將執行溢位檢查所需的資訊傳遞至後端選取項目,後端會學習如何支援大型訊息。
在此 RFC 之前,繫結會將編碼/解碼緩衝區普遍放置到堆疊上。日後,建議繫結應繼續對未翻轉 byte_overflow 旗標的訊息執行這項行為。對於這類訊息,繫結應改為在堆積上分配。
效能
如要估算建議傳送方式的效能影響,請在稍微自訂的情境中使用核心微基準,然後加總並比較兩種情況:傳送大小為 B 的單一管道訊息,以及傳送大小為 16 位元組的管道訊息,並傳送大小為 B - 16 的 VMO,其中 B 的值如下:16KiB、32KiB、64KiB、128KiB、256KiB、512KiB、1024KiB、2048KiB 和 4096KiB。
清單 1:表格顯示預估1 傳送時間成效,以及以 16 位元組的管道訊息傳送 B 位元組資料時支付的「稅金」,以及大小為 B - 16 的 VMO,而非大小為 B 的管道訊息。
| 訊息大小 / 策略 | 僅限頻道 | 電視頻道 + VMO | VMO 使用稅 |
|---|---|---|---|
| 16KiB | 2.5μs | 5.9 微秒 | 136% |
| 32KiB | 4.5μs | 7.7μs | 71% |
| 64KiB | 7.9μs | 13μs | 65% |
| 128KiB | 16.5 微秒 | 23.3 微秒 | 41% |
| 256KiB | 35.8μs | 54.4 微秒 | 52% |
| 512KiB | 71.3μs | 107.4 微秒 | 51% |
| 1024KiB | 157.0μs | 223.4 微秒 | 42% |
| 2048KiB | 536.2μs | 631.8μs | 18% |
| 4096KiB | 1328.2 微秒 | 1461.8 微秒 | 10% |
清單 2:圖表顯示預估送達時間效能「稅金」,也就是以大小為 B - 16 的 VMO 傳送 B 位元組的資料,而非以大小為 B 的管道訊息傳送時所支付的費用。
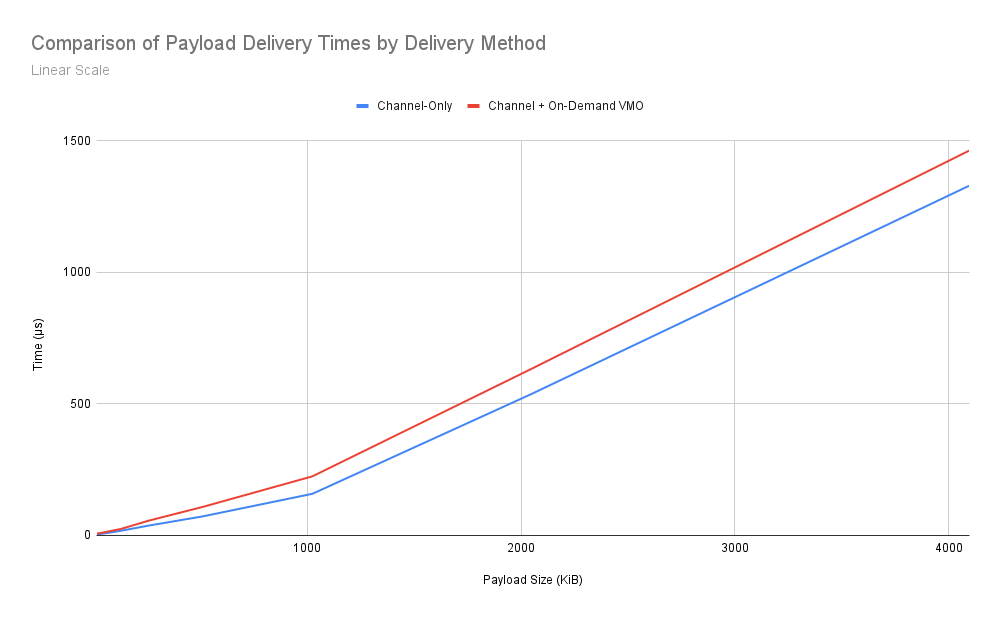
清單 3:以線性比例比較傳送 B 位元組資料時的傳送時間效能,其中一種方式是傳送 16 位元組的管道訊息,另一種方式是傳送大小為 B - 16 的 VMO,而不是大小為 B 的管道訊息。
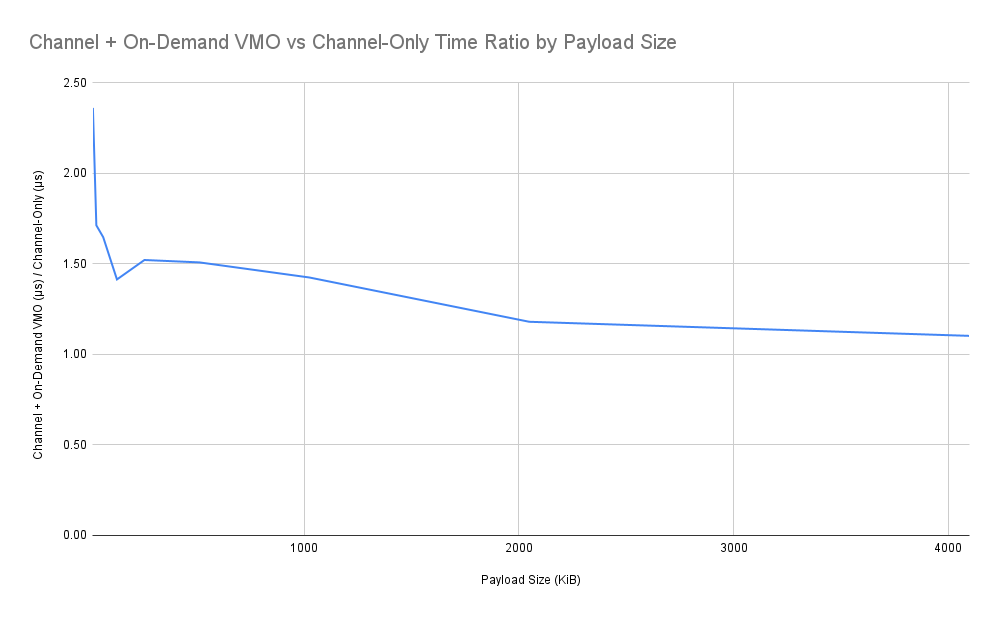
這項資料可得出幾項有趣的觀察結果。從圖中可以看出,資料大小與傳送時間大致呈現線性關係。顯然這兩種方法在效能上存在差距,但有趣的是,隨著訊息大小增加,差距似乎會縮小。
結合這些結果,我們可以模擬使用本設計中指定方法傳送 FIDL 大型訊息的預期效能。我們可以預期,在特定大小下,使用所謂的「VMO 稅」會比使用相同大小的舊版管道訊息 (如果允許) 大約增加 20% 至 60% 的端對端傳送時間。有趣的是,隨著傳送的訊息大小增加,百分比差距會略為縮小,這表示 VMO 稅金相對於酬載大小,會略為次線性成長。
清單 4:表格,顯示本文所述設計的模擬運送時間成效。
| 訊息大小 / 策略 | 僅限頻道 | 訊息 + VMO |
|---|---|---|
| 16KiB | 2.5μs | -- |
| 32KiB | 4.5μs | -- |
| 64KiB | 7.9μs | 13μs |
| 128KiB | -- | 23.3 微秒 |
| 256KiB | -- | 54.4 微秒 |
| 512KiB | -- | 107.4 微秒 |
| 11024KiB | -- | 223.4 微秒 |
| 2048KiB | -- | 631.8μs |
| 4096KiB | -- | 1461.8 微秒 |
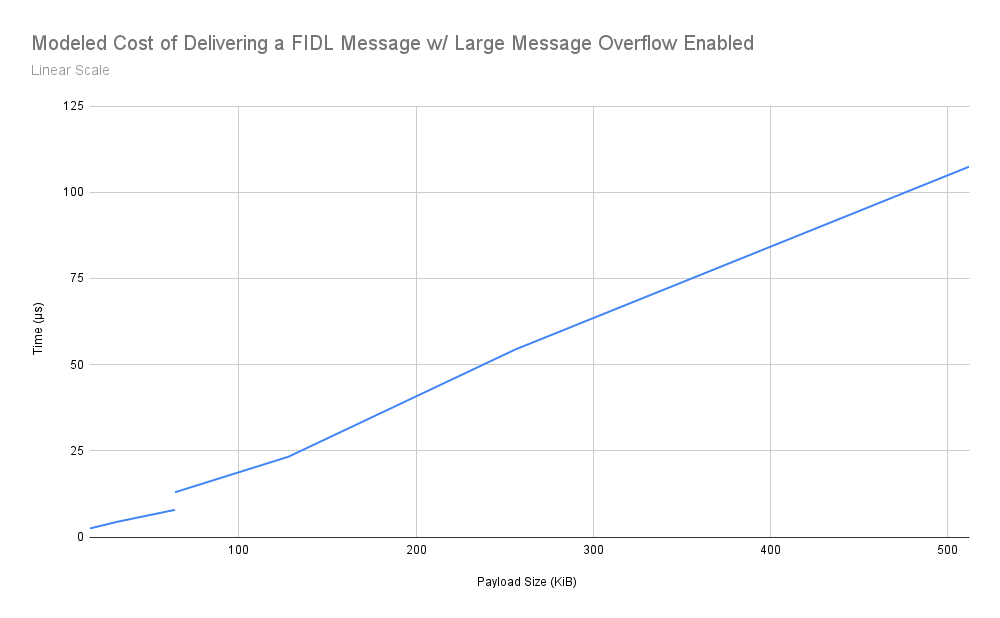
清單 5:線性比例圖,顯示本文所述設計的預估運送時間成效。請注意,從一般訊息切換為大型訊息時,64 KiB 處會出現不連續的情況。
人體工學
這項變更大幅提升了人體工學,因為基本上所有 zx.handle:VMO、fuchsia.mem.Buffer 和 fuchsia.mem.Data 的目前用途,現在都可以改用一流的 FIDL 概念來描述。下游繫結程式碼也會受益,因為先前必須透過未輸入的線路傳送的資料,現在可以使用一般的 FIDL 路徑處理。本質上,大型訊息產生的 FIDL API 現在與非大型訊息對應項目相同。
回溯相容性
這些變更完全向下相容。現有 API 的語意略有變更 (從每個訊息 64 KiB 的限制改為無限制),但由於這是放寬先前的限制,因此不會影響現有 API。
安全性考量
這些變更對安全性的影響極小。使用 fuchsia.mem.Data 結構即可將模式提升為「一流」狀態,且不會對安全性造成負面影響。不過,在所有情況下,確保實作安全仍相當重要。
這項設計也會擴大與 FIDL 通訊協定相關的阻斷攻擊風險。先前,只有明確傳送含有型別的 fuchsia.mem.Data/fuchsia.mem.Buffer/zx.handle:VMO 的通訊協定,才能透過傳送 VMO 分配大量記憶體,導致接收端當機的攻擊向量。現在,凡是包含至少一種方法且具有無界或半界酬載的所有通訊協定,都會面臨這項風險。目前之所以認為可以容忍,單純是因為 Zircon 中存在許多阻斷攻擊向量。我們將在設計範圍外,尋求更全面的解決方案來解決這個問題。
這項設計並未強制在接收端檢查 ZX_INFO_VMO,因此會產生額外的阻斷攻擊向量。這會導致伺服器停止回應,因為 VMO 永遠不會提供承諾提供的頁面。實務上,我們認為發生這種情況的風險很低,因為只有相對少量的程式會使用分頁支援的 VMO 機制。與上述原因類似,在未來的設計中實作更全面的解決方案之前,我們容許這種阻斷攻擊向量。
隱私權注意事項
隱私權方面的重要考量是,訊息傳送者必須確保為每則以 VMO 為基礎的訊息使用新建立的 VMO。不得在訊息之間重複使用 VMO,否則可能會洩漏資料。如要強制執行這些限制,必須繫結。
測試
單元測試的標準 FIDL 測試策略 (適用於 fidlc) 和下游及繫結輸出的黃金準則,將會擴充以因應大型訊息的使用情境。
說明文件
FIDL 電線格式規格需要更新,以說明本文介紹的電線格式變更。
缺點、替代方案和未知事項
缺點
這種設計有許多缺點。雖然這些問題相較於無所作為或實作替代方案的成本而言,可說是微不足道,但仍值得指出。
效能懸崖
如效能探索一節所述,本 RFC 中說明的策略會在 ZX_CHANNEL_MAX_MSG_BYTES 截斷點造成效能「懸崖」,使用者開始支付「稅金」來傳送較大的訊息。具體來說,如果郵件大小超過 64 KiB 一個位元組,接收時間會比 64 KiB 的郵件長約 60% (13μs 而非 7.9μs)。雖然這種陡峭的曲線並不理想,但相對較小,而且可以透過未來的核心變更改善。
阻斷攻擊
現在,只要通訊協定至少有一個方法會採用無界或半界酬載,就可能因記憶體而遭受阻斷攻擊:惡意攻擊者可以在 message_info struct 的 msg_byte_count 欄位中傳送值非常大的溢位訊息,並附加同樣大的 VMO。接收端隨後會被迫分配足夠的記憶體來處理這個酬載,如果惡意酬載夠大,就會導致系統崩潰。
如上文安全考量所述,這是非常實際的風險,而這個設計會將解決方案延後至日後再行處理,屆時可望找到更全面的解決方案。
處理溢位特殊情況
不過,如果訊息過大 (例如超過 64 個控制代碼的一般訊息,或超過 63 個控制代碼的大型訊息),仍會觸發錯誤狀態,因此這個設計無法完全避免在執行階段發生意外的 PEER_CLOSED。目前可接受這種做法,因為作者並未發現實際使用這類酬載的情況。如有需要,可以處理這個極端情況。在 message_info 結構體中加入 reserved 欄位,可確保日後設計控制代碼溢位支援功能時,具有彈性。
視情況而定的訊息屬性
byte_overflow 和旗標會是第一個標頭旗標,對不同傳輸方式而言意義不同 (但取決於我們是否將「靜態 FIDL」視為「傳輸方式」,靜態旗標可能例外)。這會造成一些模糊不清的情況:如果不知道是哪個傳輸方式傳送的訊息,光是查看以線路編碼的 FIDL 交易訊息,可能已不足以處理該訊息。現在需要「前處理」步驟,視標頭旗標和傳送郵件的傳輸方式而定,我們會執行特殊程序來組裝完整郵件內容。舉例來說,如果非控制代碼攜帶訊息在 Zircon 管道傳輸時溢位,現在會取得控制代碼陣列中的控制代碼,但 fdf 訊息溢位時可能不會。
遭拒的替代項目
在設計本 RFC 時,我們考慮了大量替代解決方案。以下列出最有趣的提案。
提高 Zircon 訊息大小上限
大型訊息最迫切的需求是透過 zx.channel 傳輸,目前訊息大小上限為 64 KiB。顯而易見的解決方法是提高這項限制。
這並非理想的情況,原因如下:首先,這只是將問題延後處理。由於這類 ABI 中斷核心限制遷移並非易事,因此情況更加複雜,因為必須謹慎管理,確保限制提高後編譯的二進位檔不會意外傳送超出限制提高前編譯二進位檔可處理的資料量。
許多 FIDL 實作項目也會根據限制做出實用假設。
部分繫結 (例如 Rust 的繫結) 會對收到的訊息採用「猜測並檢查」的分配策略。它們會分配小型緩衝區,並嘗試
zx_channel_read_etc。如果該系統呼叫失敗並傳回 ZX_ERR_BUFFER_TOO_SMALL,則會傳回實際訊息大小。這樣繫結就能分配適當大小的緩衝區,並重試。
其他繫結 (例如 C++ 的繫結) 則會不顧一切,一律為傳入訊息分配 64 KiB,避免多次系統呼叫,但會分配較大的空間。後者策略無法任意縮放至大型訊息。
最後,使用 VMO 是經過充分測試的解決方案:多年來,透過 fuchsia.mem.Data 和 fuchsia.mem.Buffer 類型,VMO 已成為大型訊息傳輸的首選。提高核心限制的解決方案較不成熟,且可能存在更多未知問題。
以 zx_vmar_map 取代 zx_vmo_read
如果想最佳化目前的設計,FIDL 編碼器會使用 zx_vmar_map 直接從 VMO 緩衝區讀取資料。這種做法有兩個問題。
主要問題是這個方法不安全,需要修改核心基本類型才能解決。問題在於,對應記憶體會導致訊息傳送者在接收者閱讀訊息時修改訊息內容,造成 TOCTTOU 風險。讀取器可以嘗試直接從對應的 VMO 讀取資料,而不用先複製,但即使執行防禦性副本,也很難安全地完成這項作業。這些安全風險可透過 zx_vmo_create_child 呼叫強制執行 VMO 的不可變動性來降低,但會產生額外的系統呼叫和最糟的複製作業負擔。
記憶體對應效能的其他問題,以及 C++ 繫結線路的複雜性 (例如決定何時可釋放記憶體),都讓這個選項不太適合。
封包化
這裡的概念是將非常大的訊息分割成多個訊息,每個區塊不得超過 64 KiB,然後在另一端組裝這些訊息。交易訊息標頭會包含某種延續旗標,指出是否預期後續會有「更多資料」。這項做法的優點是內建流量控制,且對於來自標準程式庫中含有串流基本體的語言的程式設計師來說,也相當熟悉。
這種做法的缺點是,如果訊息不容易分塊,就無法明顯提供協助。此外,這項技術也複雜許多:當多個執行緒傳送資料時,大量的部分訊息區塊會塞爆傳輸作業,需要在另一端重新組裝。
最令人擔憂的是,這項策略會造成阻斷攻擊風險,而且光靠新的核心基本元素或未來新增的有界通訊協定,都無法修正這項問題:惡意或有錯誤的用戶端可能會傳送非常長的訊息封包串流,但隨後卻無法傳送「關閉」封包。接收端必須將所有剩餘封包保留在記憶體中,等待最後一個封包,讓用戶端在伺服器上「預訂」可能無限的持續性記憶體配置。當然,您可以透過逾時和政策限制等方式解決這個問題,但這很快就會演變成透過 FIDL 重新實作 TCP。
明確溢位
本文提出的設計會將大型訊息從使用者端傳送的詳細資料抽象化。使用者只要定義酬載,繫結就會在幕後完成其餘作業。
替代設計可讓使用者以宣告方式指定何時要使用 VMO,無論是針對每個酬載或每個酬載成員。從本質上來說,這只會涉及修改 FIDL 語言,為 fuchsia.mem.Data 提供更清楚的拼字。
現有設計會以效能提升和 API 相容性為代價,換取較低的決定性和精細控制項,我們認為這項交換值得。
只允許值類型
這項設計的早期版本僅建議為值類型啟用 overflowing。原因很簡單:現有用途都不是資源類型,而且單一 FIDL 訊息不太可能需要一次傳送超過 64 個控制代碼,因此我們判斷這項功能優先順序較低。
在為fuchsia.component.resolution 程式庫製作這個解決方案的原型時,我們發現了一個問題。某些方法已使用表格來攜帶酬載,與其全面取代方法,不如擴充表格,逐步淘汰 fuchsia.mem.Data 的使用。具體來說:
// Instead of adding a new method to support large messages, the preferred
// solution is to extend the existing table and keep the current method.
protocol Resolver {
Resolve(struct {
component_url string:MAX_COMPONENT_URL_LENGTH;
}) -> (resource struct {
component Component;
}) error ResolverError;
};
type Component = resource table {
// Existing fields - note the two uses of `fuchsia.mem.Data`.
1: url string:MAX_COMPONENT_URL_LENGTH;
2: decl fuchsia.mem.Data;
3: package Package;
4: config_values fuchsia.mem.Data;
5: resolution_context Context;
// Proposed additions for large message support.
6: decl_new fuchsia.component.decl.Component;
7: config_values_new fuchsia.component.config.ValuesData;
};
這些方法會產生一個有趣的問題:雖然在實務上,酬載過大和酬載攜帶控制代碼的情況互斥,但 fidlc 編譯器並不知道這一點。從這個角度來看,這些只是資源類型。雖然可以想像出一些權宜之計,教導編譯器瞭解這個特定情況,但我們認為,在開發出更合適的 Kernel 原始型別之前,允許大型訊息使用 63 個控制代碼會比較簡單。
overflowing 修飾符
這個設計的早期疊代版本允許使用者在 FIDL 中設定 overflowing 值區,定義通訊協定方法,如下所示:
// Enumerates buckets for maximum zx.channel message sizes, in bytes.
type msg_size = flexible enum : uint64 {
@default
KB64 = 65536; // 2^16
KB256 = 262144; // 2^18
MB1 = 1048576; // 2^20
MB4 = 4194304; // 2^22
MB16 = 16777216; // 2^24
};
@transport("Channel")
protocol Foo {
// Requests up to 1MiB are allowed, responses must still be less than or equal
// to 64KiB.
Bar overflowing (BarRequest):zx.msg_size.MB1
-> (BarResponse) error uint32;
};
這項做法最終被認為過於複雜且難以捉摸,因為它提供多個選項,但沒有明確的選擇指引。最終,大多數使用者可能只想回答簡單的是/否問題 (「我是否需要支援大型訊息?」),而不是擔心特定限制對效能的細微影響。
此外,我們也考慮使用單一 overflowing 關鍵字,不含任何值區,向使用者明確表示他們接受的 API 可能效能較差。最終決定效能差距不夠大,且無論如何都足以縮小,因此語言本身不需要這類呼叫。
潛在的未來工作
雖然啟用大型訊息功能並非必要,但有許多相關工作可做為這項功能的輔助和最佳化措施。
核心異動
有許多可能的 Kernel 變更,雖然不是實作這項功能的關鍵路徑,但無疑有助於減少系統呼叫的抖動,並提升效能。大型訊息的使用者面向 API 不應在實作這些額外最佳化措施時有所變更。fuchsia.mem.Data 的大多數現有使用者對延遲並不特別敏感 (否則他們就不會使用 fuchsia.mem.Data!),因此修改核心的主要用途是改善效能,以因應在 FIDL 中啟用大型訊息後出現的新興用途。
一流的串流
每當出現大型訊息的使用案例時,難免會有人問:「難道不能在 FIDL 中實作一流的串流來解決這個問題嗎?」如要回答任何特定案例的問題,可以考慮大量資料可分類的兩個實用屬性:chunkability 和 appendability。
可分塊性是指相關資料是否可分割成有用的子部分,更重要的是,資料接收者是否能只對子集執行有用的工作。基本上,這就是 T 類型資料與 vector<T> 或 array<T> 類型資料之間的差異,後者仍可對清單的部分檢視畫面執行動作。分頁清單可分塊,但要傳送排序的項目清單則無法分塊。同樣地,樹狀結構也無法分塊,因為一般來說,樹狀結構的 (任意) 部分用途不大。
可附加性是指資料傳送後是否可以修改。 可附加 API 的經典範例是 Unix 管道:從讀取端讀取資料時,可能會從寫入端新增更多資料,甚至預期會發生這種情況。傳送後可新增資料的資料稱為可附加資料。即使是清單形式,傳送時不可變更的資料也不會。
清單 6:針對所有可能的區塊化和附加性組合,列出偏好的大型資料處理策略矩陣。
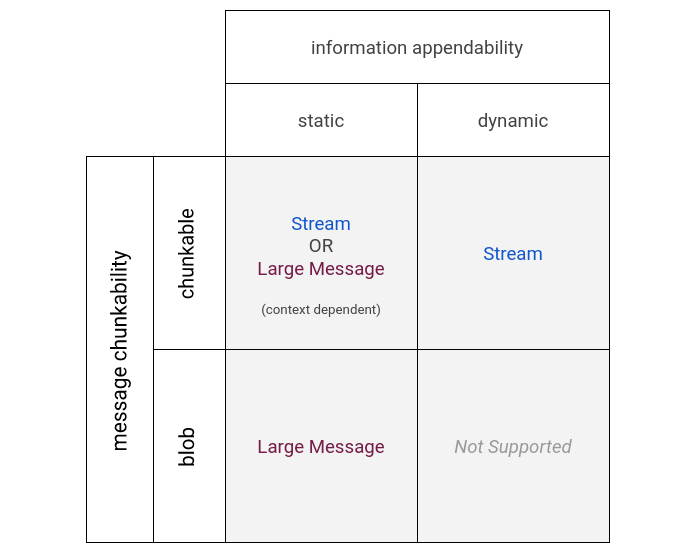
這兩項區別相當實用,因為將兩者合併成矩陣後,就能清楚瞭解哪些大型訊息或串流更適合。
如果是靜態 Blob (例如資料傾印、B 樹狀結構或大型 JSON 字串),使用者不會想串流處理:對他們來說,這是一則訊息,而這則訊息 (或至少可能) 對 FIDL 來說太大,這點是意外的複雜性,通常與他們的疑慮相去甚遠。在這種情況下,他們希望有一種方法可以告訴系統「盡一切努力,透過網路傳送這則訊息,但不要超過最不合理的尺寸」。資料具體化到裝置某處的記憶體後,再以零碎的方式在程序之間移動就沒有什麼意義。
對於可分塊的動態資料結構 (例如網路封包串流),串流是顯而易見的選擇 (名稱就說明一切!)。使用者已建立自訂疊代器來處理這個情況,並編寫程式庫來處理傳送端的串流設定,以及在接收端清楚地公開串流,因此這似乎很適合做為第一類處理方式。此外,這也是非常自然的模式,在 FIDL 繫結的大部分語言 (C++、Dart、Rust) 中,都具有強大的支援和程式設計師熟悉度。
如果訊息可分塊,但大部分是靜態內容,例如列出連線至裝置的周邊裝置快照,該怎麼辦?將這些內容分塊並以串流形式公開相當容易,但這是否有利並不顯而易見:在公開這類資訊的 API 中,有幾個案例的作者認為分頁是為了滿足 FIDL 而加入的權宜之計,而非核心功能。在這種情況下,串流或大型訊息是否為較佳選擇,似乎取決於具體情境。
總而言之,大型訊息只是工具箱中的其中一項工具,可用於透過網路傳輸大量資料。FIDL 很可能在未來提供一流的串流實作,這項實作會與大型訊息提供的功能互補,而非取代。
受限通訊協定和彈性信封大小限制
這項設計有非常實際的阻斷攻擊風險,某些通訊協定 (尤其是許多其他獨立用戶端共用的通訊協定) 可能會想避免這種情況。為此,您可以想像在通訊協定中加入 bounded 修飾符,在編譯時強制所有方法僅使用有界型別:
// Please note that this syntax is very speculative!
bounded protocol SafeFromMemoryDoS {
// The payload is bounded, so this method compiles.
MySafeMethod(resource struct {
a bool;
b uint64;
c array<float32, 4>;
d string:32;
e vector<zx.handle, 64>;
});
};
這種設計的後果之一是,FIDL 通訊協定作者面臨「分叉」選擇:新增 bounded 可避免通訊協定因無限制的大型訊息而可能發生阻斷攻擊,但會導致該方法的酬載無法遞移使用 table 或 flexible union 型別。這是一項令人遺憾的取捨,因為可演化性和 ABI 相容性是 FIDL 語言的核心目標。強制使用者採用 ABI 穩定型別,會大幅限制他們日後演進酬載的能力。
其中一個可能的折衷方案,是為封裝版面配置導入明確的大小限制。flexible這樣可提供 ABI 相容性,因為彈性定義會隨時間改變,但仍會對型別的最大大小強制執行 ABI 中斷限制:
// Please note that this syntax is very speculative!
@available(added=1)
type SizeLimitedTable = resource table {
1: orig vector<zx.handle>:100;
// Version 2 still compiles, as it contains <=4096 bytes AND <=1024 handles.
@available(added=2)
2: still_ok string:3000;
// Version 3 fails to compile, as its maximum size is greater than 4096 bytes.
@available(added=2)
3: causes_compile_error string:1000;
}:<4096, 1024>; // Table MUST contain <=4096 bytes AND <=1024 handles.
這類大小限制提供某種「軟性」彈性:酬載仍可隨時間變更,但首次定義酬載時,系統會對成長範圍設下硬性 (即 ABI 中斷) 限制。
既有技術和參考資料
這項提案有充分的先例,因為 fuchsia.mem.Data,以及之前的 fuchsia.mem.Buffer 和 zx.handle:VMO,都已廣泛使用並支援 fuchsia.git 程式碼集。這項決策基本上是經過充分測試的模式,可說是「一流」的演進。
先前已放棄的 RFC 描述的內容與此類似,同樣使用 VMO 做為大型訊息的基礎傳輸機制。
附錄 A:fuchsia.git 中 FIDL 酬載的界限
下表顯示截至 2022 年 8 月初,fuchsia.git 程式碼集內溢位 (大於 64 KiB) 和標準酬載的界限分佈情形。這項資料是透過建構 fuchsia.git 的「所有內容」版本收集而來。接著,透過一系列 jq 查詢分析產生的 JSON IR。
清單 7:表格,顯示 fuchsia.git 存放區中每種酬載界限和大小的測量頻率。
| 有界性 / 訊息種類 | 標準 | 溢位 | 總計 |
|---|---|---|---|
| 有界 | 3851 (76%) | 45 (%) | 3896 (77%) |
| 半有界 | 530 (10%) | 70 (1%) | 600 (11%) |
| 無界限 | 0 (0%) | 602 (12%) | 602 (12%) |
| 總計 | 4381 (86%) | 717 (14%) | 5098 (100%) |