
| RFC-0050:FIDL 語法大改造 | |
|---|---|
| 狀態 | 已接受 |
| 區域 |
|
| 說明 | 我們為語法選擇制定指導原則,並根據這些原則進行一些語法變更。 |
| 作者 | |
| 提交日期 (年-月-日) | 2020-02-26 |
| 審查日期 (年-月-日) | 2019-06-04 |
摘要
我們為語法選擇建立指導原則,並根據這些原則進行一些語法變更。
變更
- 將型別放在第二個位置,例如在方法參數名稱中,型別會放在各自的名稱前面;在資料表宣告中,成員名稱會放在各自的型別前面;
- 將型別從限制條件中分離版面配置,將版面配置相關型別資訊放在
:分隔符的左側,限制條件資訊則放在右側,例如array<T, 5>與vector<T>:5更清楚地傳達陣列大小會影響版面配置,但對向量而言是限制條件。 - 推出匿名版面配置。舉例來說,
table { f1 uint8; f2 uint16; }可直接用於方法參數清單中。 - 頂層型別的宣告是透過匿名版面配置完成,並使用 型別簡介宣告,形式為
type Name = Layout;。 - 最後,針對通訊協定
P,請將P和request<P>分別重新命名為client_end:P和server_end:P。請注意,通訊協定是用戶端或伺服器端的限制,而不是先前的位置,否則會錯誤地指出與版面配置相關的問題。
與其他 RFC 的關係
- 這項 RFC 包含 RFC-0038:將版面配置與限制條件分開和 RFC-0039:型別排在第二位,也就是說,接受 RFC-0050 就表示 RFC-0038 和 RFC-0039 都「過時」而遭拒。
- 本 RFC 提議的替代解決方案,適用於 RFC-0044:可擴充的方法引數,也就是說,接受 RFC-0050 代表拒絕 RFC-0044,因為後者「已過時」。
這項 RFC 後來經過以下修訂:
- RFC-0086:更新 RFC-0050:FIDL 屬性語法
- RFC-0087:更新 RFC-0050:FIDL 方法參數語法
- RFC-0088:更新 RFC-0050:FIDL 位元、列舉和限制語法
提振精神
入門範例
代數資料型別
語法用途廣泛,可流暢地表示代數資料型別 (ADT),不需要任何其他語法糖。舉例來說:
/// Describes simple algebraic expressions.
type Expression = flexible union {
1: value int64;
2: bin_op struct {
op flexible enum {
ADD = 1;
MUL = 2;
DIV = 3;
};
left_exp Expression;
right_exp Expression;
};
3: un_op struct {
op flexible enum {
NEG = 1;
};
exp Expression;
};
};
就模式而言,我們選擇使用 union 的 struct:union 提供擴充性,因此不需要 (且最好不要) 使用更嚴格的變體。如需變更變化版本,我們可以改為批次新增變化版本,然後改用這個新版本。(在其他需要可演化性的位置,例如二元或一元運算子清單,會選擇彈性列舉。)
支援 ADT 不只需要符合人體工學的語法來描述資料型別,舉例來說,其中一項預期功能是輕鬆建構和毀損 (例如透過模式比對或訪客模式)。
這項 RFC 不會為 FIDL 導入新功能,且遞迴型別的限制會導致範例無法編譯。我們計畫新增對一般遞迴型別的支援,而這項擴充功能將成為日後 RFC 的主題。
更輕鬆地將不可演進的訊息與可演進的訊息合併
舉例來說,表示「可擴充的結構體」,其中同時具有結構體元素 (精簡、內嵌、快速編碼/解碼),以及擴充的可能性:
type Something = struct {
...
/// Provide extension point, initially empty.
extension table {};
};
舉例來說,fuchsia.test.breakpoints 程式庫需要定義名為 Invocation 的可擴充事件。這些事件都共用相同的值,以及每個事件變體的特定酬載。現在可以更直接且簡潔地表示為:
type Invocation = table {
1: target_moniker string:MAX_MONIKER_LENGTH;
2: handler Handler;
3: payload InvocationPayload;
};
type InvocationPayload = union {
1: start_instance struct{};
2: routing table {
1: protocol RoutingProtocol;
2: capability_id string:MAX_CAPABILITY_ID_LENGTH;
3: source CapabilitySource;
};
};
可擴充的方法引數
舉例來說,可擴充的方法引數:
protocol Peripheral {
StartAdvertising(table {
1: data AdvertisingData;
2: scan_response AdvertisingData;
3: mode_hint AdvertisingModeHint;
4: connectable bool;
5: handle server_end:AdvertisingHandle;
}) -> () error PeripheralError;
};
使用 table 做為引數並非「最佳做法」。這或許是適當的做法,但會帶來一連串問題,例如 N 個欄位有 2N 種可能性,可能會為收件者增加許多複雜度。
指導原則
FIDL 主要用於定義應用程式二進位介面 (ABI) 相關事項,其次則用於定義應用程式設計介面 (API) 相關事項。這可能會導致語法比您習慣的更冗長,或與其他程式設計語言相比,可能超出您的預期。舉例來說,聯集中的 unit 變體會表示為空結構體,如上方的 InvocationPayload 範例所示。我們可以選擇導入語法糖來省略這個型別,但這會與將 ABI 問題放在首要位置的目標背道而馳。
將版面配置與限制分開
語法對齊
layout:constraint
如果是型別,也就是控制版面配置的任何項目,都會放在冒號前;控制限制的任何項目,則會放在冒號後。版面配置說明位元組的排列方式,而非解讀方式。這項限制會根據版面配置限制可呈現的內容,是編碼/解碼期間執行的驗證步驟。
這個語法提供簡化的方式,可考量變更對 ABI 的影響,特別是會產生兩項簡寫規則:
- 如果兩種型別的版面配置不同,就無法從一種型別軟轉換至另一種,反之亦然 1,也就是說變更左側會破壞 ABI
- 限制可能會演變,只要寫入者受到的限制比讀取者多,兩者就能相容,也就是可以演變右側並保留 ABI
以下是根據這項原則進行變更的範例:
array<T>:N「」會變成「」array<T, N>handle<K>「」會變成「」handle:Kvector<T>?「」會變成「」vector<T>:optionalStruct?「」會變成「」box<Struct>Table?「」會變成「」Table:optionalUnion?「」會變成「」Union:optional
這些變更會在 RFC 的「設計」一節中討論。
二進位線路格式優先
雖然許多格式都能代表 FIDL 訊息,但 FIDL 線路格式 (或「FIDL 二進位線路格式」) 享有優先處理權,且會優先處理。
也就是說,為了與 ABI 一致性保持一致,語法選擇應考量二進位線路格式下的 ABI (而非 JSON 等其他格式)。
舉例來說,就型別的 ABI 而言,名稱並不重要;但對於通訊協定和方法,名稱確實很重要。雖然名稱可能對我們選擇的 JSON 格式很重要,但我們在選擇語法時,會傾向於二進位 ABI 格式,且不會為了有利於文字表示法而變更語法,因為這樣會妨礙對 ABI 規則的理解。
功能最少
萊特「形式與功能應合而為一」的理念,促使我們努力讓外觀相似的建構體具有相似的意義,反之亦然。舉例來說,所有可擴充資料 (內部使用信封) 一律會以 ordinal: 呈現。
layout {
ordinal: name type;
};
我們致力於減少功能和規則,並整合功能來達成使用情境。實務上,考慮新功能時,我們應先嘗試調整或泛化其他現有功能,而不是導入新功能。舉例來說,雖然可以為可擴充的方法引數 (和傳回值) 設計特殊語法,如 RFC-0044:可擴充的方法引數中所述,但我們偏好使用 table 和這些引數的正常語法。
有人可能會認為,我們甚至應該要求方法要求和回應採用匿名 struct 版面配置,而不是目前從大多數程式設計語言借用的引數語法糖。不過,競爭設計考量是協助程式庫作者整體達成一致性:在 enum 版面配置宣告中,我們偏好語法糖,而非明確選擇包裝型別,因為有合理的預設值可為 FIDL 程式庫中的列舉提供更高的一致性。這會提供遷移路徑,以便日後切換列舉,例如程式庫定義一般用途的 ErrorStatus 列舉時,之後可以替換為另一個「更佳」的一般用途 ErrorStatusV2。
設計
類型
類型採用一般格式:
Name<Param1, Param2, ...>:<Constraint1, Constraint2, ...>
空白型別參數化必須省略 < 和 >,也就是 uint32 (而非 uint32<>)。
如果類型沒有限制,則必須省略 : 分隔符和 <、>,也就是 uint32 (而非 uint32:<> 或 uint32:)。
如果型別只有單一限制,可以省略 < 和 >,也就是說,vector<uint32>:5 和 vector<uint32>:<5> 都是允許的,而且兩者等效。
內建
支援的基本型別如下:
- 布林值
bool - 帶正負號的整數
int8、int16、int32、int64 - 不帶正負號的整數
uint8、uint16、uint32、uint64 - IEEE 754 浮點
float32、float64
固定大小的重複值:
array<T, N>
這可以視為具有 T 型別 N 元素的 struct。
大小可變的重複值:
vector<T>
vector<T>:N
也就是說,可以省略大小 N。
可變大小的 UTF-8 字串:
string
string:N
也就是說,可以省略大小 N。
核心物件的參照,也就是控制代碼:
handle
handle:S
子類型 S 為 bti、buffer、channel、debuglog、event、eventpair、exception、fifo、guest、interrupt、iommu、job、pager、pcidevice、pmt、port、process、profile、resource、socket、suspendtoken、thread、timer、vcpu、vmar、vmo 其中之一。
RFC-0028:控制代碼權限中導入的權限控制代碼:
handle:<S, R>
其中權利 R 可以是權利值或權利運算式。
通訊協定物件的參照,即目標用途的管道控制代碼:
client_end:P
server_end:P
即 client_end:fuchsia.media.AudioCore 或 server_end:fuchsia.ui.scenic.Session。
具體來說,單獨參照通訊協定並不合法:通訊協定宣告不會導入型別,只會導入可視為用戶端或伺服器端點的項目。詳情請參閱「傳輸一般化」一節。
版面配置
除了內建版面配置,我們還提供五種版面配置,可設定為導入新類型:
enumbitsstructtableunion
有限版面配置
enum 和 bits 版面配置的表示方式類似:
layout : WrappedType {
MEMBER = expression;
...;
};
其中 : WrappedType 為選用 [^2],如省略則預設為 uint32。
enum 範例:
enum {
OTHER = 1;
AUDIO = 2;
VIDEO = 3;
...
};
bits 範例:
bits : uint64 {
TOTAL_BYTES = 0x1;
USED_BYTES = 0x2;
TOTAL_NODES = 0x4;
...
};
彈性版面配置
table 和 union 版面配置的表示方式類似:
layout {
ordinal: member_name type;
...;
};
此處的 ordinal: 可視為描述 envelope<type> 的語法糖。
如果是資料表,成員通常稱為欄位。對於聯集,成員通常稱為變體。此外,成員可能保留:
layout {
ordinal: reserved;
...
};
固定版面配置
唯一的固定版面配置 struct 採用接近彈性版面配置的表示方式,但不含彈性標記:
layout {
member_name type;
...;
};
如果是結構體,成員通常稱為欄位。
屬性
版面配置前面可能會有該版面配置的屬性:
[MaxBytes = "64"] struct {
x uint32;
y uint32;
};
這樣一來,您就能明確將屬性附加至版面配置的成員和該成員的型別:
table {
[OnMember = "origin"]
1: origin [OnLayout] struct {
x uint32;
y uint32;
};
};
如果是導入版面配置的新類型,屬性在新導入的類型上可能有兩種放置位置:
- 新類型:
[Attr] type MyStruct = struct { ... }。 - 在版面配置上:
type MyStruct = [Attr] struct { ... }。
fidlc 會將這兩者視為等效,如果兩個位置都指定了屬性,就會引發錯誤。
無論使用哪個位置指定屬性,屬性在概念上都是附加至版面配置本身,而非整個型別節。舉例來說,在任何 IR 中,偏好做法都是將型別節點上的屬性降至版面配置,而不是將版面配置上的屬性提升至型別節點。
命名情境和版面配置用法
版面配置本身沒有名稱,所有版面配置都是「匿名」。 而是版面配置的特定用途,決定了在目標語言中的名稱。
舉例來說,版面配置最常見的用途是導入新的頂層型別:
library fuchsia.mem;
type Buffer = struct {
vmo handle:vmo;
size uint64;
};
在這裡,結構體版面配置用於頂層程式庫中的「新類型」宣告。
在匿名環境中使用的範例已在可擴充方法引數的簡介附註中說明:
library fuchsia.bluetooth.le;
protocol Peripheral {
StartAdvertising(table {
1: data AdvertisingData;
2: scan_response AdvertisingData;
3: mode_hint AdvertisingModeHint;
4: connectable bool;
5: handle server_end:AdvertisingHandle;
}) -> () error PeripheralError;
};
在此,表格版面配置用於 StartAdvertising 方法的要求中,位於 Peripheral 通訊協定宣告中。
我們將名稱清單 (從最不具體到最具體) 稱為「命名環境」,用來識別版面配置的使用情形。在上述兩個範例中,我們分別有 fuchsia.mem/Buffer 和 fuchsia.bluetooth.le/Peripheral, StartAdvertising, request 這兩個命名環境。
在 JSON IR 中,版面配置宣告會包含命名環境,也就是上述名稱的階層式清單。
命名脈絡
在程式庫 some.library 中,type Name = 宣告會為 some.library/Name 導入命名情境。
在要求 (或回應) 中使用 Method 內的 Protocol,會導入 some.library/Protocol, Method,
request/response 的命名環境。
在版面配置中使用時,會將欄位名稱 (或變體名稱) 新增至命名環境。例如:
type Outer = struct {
inner struct {
...
};
};
第一個外部結構體配置的命名環境是 some.library/Outer,第二個內部結構體配置的命名環境是 some.library/Outer, inner。
產生的扁平化名稱
許多目標語言可以階層式表示命名環境。舉例來說,在 C++ 中,型別可以在封閉型別中定義。不過,部分目標語言不具備這項功能,因此我們必須考量因命名環境扁平化而導致的名稱衝突。
舉例來說,請考慮命名環境 some.library/Protocol, Method,
request。這可能會在 Go 中扁平化為 some.library/MethodRequestOfProtocool。如果其他定義剛好使用命名環境 some.library/MethodRequestOfProtocool,Go 繫結就會面臨難題:必須重新命名其中一個宣告。最糟的情況是,如果具有一個宣告 (沒有名稱衝突) 的程式庫演變成具有兩個宣告 (有名稱衝突) 的程式庫,則 Go 繫結必須與先前產生的內容一致,才能避免來源重大變更。
我們的經驗顯示,這些決策最好交由核心 FIDL 編譯器處理,而不是委派給工具鍊中的 FIDL 繫結。因此,我們會計算並保證穩定的扁平化名稱。
在 JSON IR 中,命名環境會包含產生的扁平化名稱,編譯器保證該名稱在全域範圍內是唯一的,也就是前端編譯器負責產生扁平化名稱,並驗證扁平化名稱不會與其他宣告衝突 (無論是其他扁平化名稱,還是頂層宣告)。
以前述範例來說,如果程式庫作者新增的宣告 type
MethodRequestOfProtocool = ... 與另一個宣告產生的扁平化名稱衝突,編譯就會失敗。
繫結使用的命名環境
繫結大致可分為兩類:
- 能夠以目標語言表示命名背景資訊範圍,例如 C++ 語言的繫結;
- 無法表示命名環境,並回退至使用產生的扁平化名稱,例如 Go 語言的繫結。
這比目前的情況有所改善,因為我們至少會在繫結之間保持一致,並在前端提供編譯器輔助。目前我們必須在遊戲後期 (在後端) 生成部分名稱,這種做法危險且容易出錯。
舉例來說,請看以下定義:
type BinOp = union {
add struct {
left uint32;
right uint32;
};
};
在 C++ 繫結中,我們可能會遇到以下情況:
class BinOp {
class Add {
...
};
};
變數 add 的存取子為:
BinOp.add();
這不會與類別定義衝突。
或者在 Go 中,使用扁平化名稱:
type BinOp struct { ... };
type BinOpAdd struct { ... };
如果程式庫作者稍後決定導入名為 BinOpAdd 的頂層宣告,前端編譯器就會偵測到,並回報為錯誤。程式庫作者可自行決定這項變更的影響,並選擇是否要導入這項新宣告,進而中斷來源相容性。同樣地,相較於目前在稍後才發現這類來源相容性中斷問題,這項做法可說是進步許多,而且距離做出決策的地點也更近。
型別別名和新類型
在 RFC-0052:型別別名和新型別中,我們演進了型別別名和新型別宣告。
別名宣告方式如下:
alias NewName = AliasedType;
也就是說,與 RFC-0052 中提議的語法相同。
新類型會宣告為:
type NewType = WrappedType;
也就是說,無論包裝的型別是另一個現有型別 (包裝) 或某個版面配置 (新的頂層型別),新型別的語法都相同。這與 RFC-0052 中最初提議的語法不同。
選填性
某些型別本質上就是選用型別:vectors、strings、envelopes,以及使用這類建構體的版面配置,例如 table (信封向量) 和 union (標記加上信封)。因此,這些型別是否為選用型別是限制,可以演變為 (放寬限制而成為是否可為空值),或演變為 (收緊限制而成為必要型別)。
另一方面,int8 或 struct 版面配置等類型本質上無法設為選用。如要加入選用性,必須導入間接性,例如透過結構體案例中的間接參照。因此,與本質上為選用的型別不同,這類型別無法演進。
為區分這兩種情況,並遵循「將 ABI 相關問題放在左側,可演進的問題放在右側」的原則:
| 自然選用 | 非自然選填 |
|---|---|
string:optional |
box<struct> |
vector:optional |
|
union:optional |
就命名而言,我們偏好使用「選用」、「必要」、「存在」、「不存在」等字詞。
(我們應避免使用「可為空值」、「不可為空值」、「空值欄位」。)根據命名偏好設定,我們選擇 box<T> 而不是 pointer<T>。box 是預設選用的結構,也就是說,新語法中的 box<struct> 等同於舊語法中的 struct?,而 box<struct>:optional 是多餘的,可能會觸發編譯器或 Linter 的警告。這是為了更符合我們預期的用途:使用者通常會將結構體裝箱,以取得選用性,而不是新增間接性。
常數
常數的宣告方式如下:
const NAME type = expression;
限制排序
根據版面配置和限制條件將型別參數化時,這些引數的順序會針對特定型別固定。本 RFC 定義了下列限制條件順序 (目前沒有任何型別有多個版面配置引數):
- 控點:子類型、權限、選用性。
- 通訊協定用戶端/伺服器端:通訊協定、選用性。
- 向量:大小、選用性。
- 聯集:選用性。
做為指導原則,選用性一律排在最後,而對於控制代碼,子型別則排在權利之前。
舉例來說,請參考這個結構體,其中所有可能的限制都定義在其成員上:
type Foo = struct {
h1 zx.handle,
h2 zx.handle:optional,
h3 zx.handle:VMO,
h4 zx.handle:<VMO,optional>,
h5 zx.handle:<VMO,zx.READ>,
h6 zx.handle:<VMO,zx.READ,optional>,
p1 client_end:MyProtocol,
p2 client_end:<MyProtocol,optional>,
r1 server_end:P,
r2 server_end:<MyProtocol,optional>,
s1 MyStruct,
s2 box<MyStruct>,
u1 MyUnion,
u2 MyUnion:optional,
v1 vector<bool>,
v2 vector<bool>:optional,
v3 vector<bool>:16,
v4 vector<bool>:<16,optional>,
};
未來方向
除了變更現有功能的語法,我們也為近期預計推出的功能設定方向。這裡的重點是預期的表達能力和語法算繪 (而非精確的語意,這需要另外的 RFC)。舉例來說,我們在說明傳輸一般化時,不會討論各種棘手的設計問題 (例如可設定的範圍、JSON IR 中的表示法)。
本節內容也應視為指引,而非未來的規格。推出新功能時,系統會評估對應的語法,以及這些功能的確切運作方式。
內容相關名稱解析
例如:
const A_OR_B MyBits = MyBits.A | MyBits.B;
簡化為:
const A_OR_B MyBits = A | B;
例如:
zx.handle:<zx.VMO, zx.rights.READ_ONLY>
簡化為:
zx.handle:<VMO, READ_ONLY>
限制
宣告網站限制
type CircleCoordinates = struct {
x int32;
y int32;
}:x^2 + y^2 < 100;
使用網站限制
type Small = struct {
content fuchsia.mem.Buffer:vmo.size < 1024;
};
獨立限制條件
constraint Circular : Coordinates {
x^2 + y^2 < 100
};
信封限制
資料表和可擴充聯集的語法會隱藏封包的使用情形:
table是vector<envelope<...>>,且union是struct { tag uint64; variant envelope<...>; }。
目前,出現在 table 和 union 宣告中的 ordinal: 是波封存在的唯一位置,將這個語法視為波封的「糖衣」導入方式很有幫助。基本上,我們可以依下列方式去除糖分:
| 取消糖化資料表和彈性聯集 | |
table ExampleTable { 1: name string; 2: size uint32; }; |
table ExampleTable { @1 name envelope |
union ExampleUnion { 1: name string; 2: size uint32; }; |
union ExampleUnion { @1 name envelope |
如果我們想限制 envelope,例如限制為 require 元素,我們會將這項限制放在序數 ordinal:C 上,例如:
| 取消糖化資料表和彈性聯集 | |
table ExampleTable { 1:C1 name string:C2; 2:C size uint32; }; |
table ExampleTable { @1 name envelope<string:C2>:C1; @2 size envelope |
union ExampleUnion { 1:C1 name string:C2; 2:C size uint32; }; |
union ExampleUnion { @1 name envelope<string:C2>:C1; @2 size envelope |
屬性
FIDL 的型別系統已具備限制的概念。我們有
vector<uint8>:8,表示向量最多有 8 個元素,或 string:optional
放寬選用性限制,允許字串為選用。
各種需求都促使我們朝向更具表達力的限制,以及如何統一和處理這些限制的觀點邁進。
例如:fuchsia.mem/Buffer notes "This size must not be greater than the physical size of the VMO." 我們正在努力導入 RFC-0028:處理控制代碼權限,也就是限制控制代碼。或需要表格欄位的想法,也就是限制其他選用信封上的存在。
目前無法描述所操控的值或實體的執行階段屬性。雖然 string 值有大小,但無法命名。雖然 handle 具有相關聯的權利,但無法命名這些權利。
如要妥善解決與受限型別相關的表現力問題,我們必須先連結值的執行階段層面,以及 FIDL 對這些值的有限檢視畫面。我們計畫推出「屬性」,可視為附加至值的虛擬欄位。屬性不會影響連線格式,純粹是語言層級的建構體,會出現在繫結的 JSON IR 中,為屬性提供執行階段意義。屬性的唯一用途是表示對屬性的限制。每個屬性都需要繫結瞭解,就像繫結瞭解內建屬性一樣。
以上述範例為例,string 值可能具有 uint32 size 屬性,控制代碼可能具有 zx.rights rights 屬性。
例如:
layout name {
properties {
size uint32;
};
};
交通運輸一般化
宣告新傳輸方式時,至少需要定義新名稱、指定傳輸方式支援的訊息限制 (例如「無控制代碼」、「無表格」),以及指定通訊協定的限制 (例如僅限「即發即忘方法」、「無事件」)。
預計的語法類似於以未輸入型別的 FIDL 文字表示的設定:
transport ipc = {
methods: {
fire_and_forget: true,
request_response: true,
},
allowed_resources: [handle],
};
然後用作:
protocol SomeProtocol over zx.ipc {
...
};
處理一般化
目前控制代碼是 Fuchsia 專屬的概念,直接與 Zircon 核心繫結,對應至 zx_handle_t (或 C 以外語言的對等項目),且種類僅為核心公開的物件,例如 port、vmo、fifo 等。
考慮其他情況 (例如程序內通訊) 時,理想的擴充點是能夠直接在 FIDL 中定義控制代碼,而不是將其納入語言定義。
舉例來說,定義 Zircon 控制代碼:
library zx;
resource handle : uint32 {
properties {
subtype handle_subtype;
rights rights;
};
};
type handle_subtype = enum {
PROCESS = 1;
THREAD = 2;
VMO = 3;
CHANNEL = 4;
};
type rights = bits {
READ = ...;
WRIE = ...;
};
這會允許 handle 或 handle:VMO (或在另一個程式庫中 zx.handle:zx.handle.VMO)。
目前有實驗性實作項目,將用於打破 Zircon 和 FIDL 之間的循環依附元件 (在此變更之前,Zircon 的 API 是以 FIDL 說明,但 FIDL 部分是以 Zircon 的 API 定義)。
導入策略
系統會在所有 .fidl 檔案頂端加入暫時的「版本宣告」,供 fidlc 偵測 .fidl 檔案是否採用舊版或新版語法。
這個權杖會緊接在程式庫陳述式之前:
// Copyright notice...
deprecated_syntax;
library fidl.test;
...
建議使用明確標記,簡化 fidlc 偵測語法的角色,並提升可讀性。舉例來說,如果將語法解讀為任一語法都會導致編譯錯誤,這就是偵測語法時會遇到的挑戰。在這些情境中,系統需要使用經驗法則來判斷要使用舊語法還是新語法,這可能會導致結果出乎意料。
此外,這個符記會新增至先前語法中的所有檔案,而非新增至新語法 (例如 new_syntax;"),目的是為了宣傳即將進行的遷移作業,讓 FIDL 檔案的讀者瞭解語法即將變更,並透過其他管道 (例如文件、郵寄清單) 尋找其他脈絡。
系統會新增 fidlconv 主機工具,可將舊格式的 FIDL 檔案轉換為新格式的檔案,在本節中稱為 .fidl_new。雖然這項工具與 fidlc 無關,但仍需運用編譯器的內部表示法,才能正確執行這項轉換。舉例來說,只有在類型 Foo 是通訊協定的情況下,才需要轉換為 client_end:Foo,判斷案例 fidlconv 是否會先利用 fidlc 編譯 FIDL 程式庫。
FIDL 前端編譯器 fidlc 和格式器/Linter 等隨附工具將會擴充,以支援上述標記定義的語法。
新增這項功能後,建構管道會擴充如下:
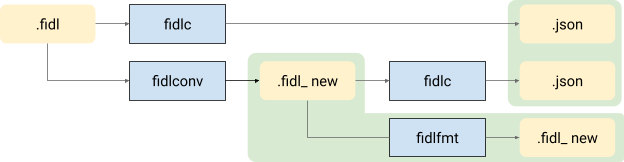
也就是:
fidlconv工具會將舊語法的 FIDL 檔案轉換為新語法。fidlc編譯器會編譯舊語法,輸出.json。- 此外,
fidlc編譯器會編譯新語法,輸出.jsonIR。 fidlfmt格式化工具會格式化產生的新程式庫檔案.fidl_new。
測試及驗證:
- 系統會比較這兩個 JSON IR,並驗證是否相符 (跨度資訊除外)。
- 系統會驗證新程式庫檔案格式化的等冪性,檢查
fidlc編譯器和fidlfmt格式化工具的輸出內容是否採用新語法。
實作這項功能時,FIDL 團隊也會將編碼表後端移至獨立二進位檔 (與其他後端相同),並產生最後一次使用 C 繫結後端的情況,然後在 fuchsia.git 樹狀結構存放區中檢查,藉此淘汰並刪除 C 繫結後端。
人體工學
這項 RFC 主要與人體工學有關。
我們願意讓熟悉目前語法的開發人員在重新訓練使用修改後的語法時,短期內工作效率下降,因為我們深信未來會有更多開發人員使用 FIDL,他們將會受益良多。
說明文件和範例
這需要變更下列項目:
回溯相容性
這項變更不具備回朔相容性。如需轉換計畫,請參閱導入部分。
效能
這項變更不會影響成效。
安全性
這項變更不會影響安全性。
測試
請參閱實作一節的轉換計畫,並驗證其正確性。
缺點、替代方案和未知事項
使用半形冒號分隔名稱和類型
由於我們將型別移至第二個位置,因此也可以考慮使用相當常見的 : 分隔符,如型別理論、Rust、Kotlin、ML 語言 (SML、Haskell、OCaml)、Scala、Nim、Python、TypeScript 等等:
field: int32 rather than the proposed field int32
這項提案拒絕採用這種做法。
: 分隔符主要用於分隔版面配置與限制。也用於表示 enum 和 bits 宣告的「包裝型別」。最後,它用於標示 table 和 union 宣告中的信封。
進一步多載 : 分隔符號,特別是在語法上與主要用途接近時,會導致混淆 (例如表格成員 1: name:
string:128;)。
省略分號
我們已討論過要省略終止宣告的分號 (無論是成員、常數或其他)。
本提案選擇不探討這項簡化作業。
對 FIDL 作者而言,移除半形分號在語法上幾乎沒有差異。這也不是需要進行的重大變更,如果我們想在日後探索這項功能,也很容易修改 (例如 Go 移除半形分號的方法)。
不過,如果成員和宣告以半形分號結尾,就能更輕鬆地確保語法規則明確無誤,尤其是在探索限制 (使用位置和宣告位置) 時。舉例來說,使用宣告網站版面配置限制 (C),例如 struct Example { ... }:C;,我們會在 : 分隔符和 ; 終止符之間清楚劃分限制。
統一列舉和聯集
從型別理論的角度來看,列舉代表單元型別的總和,聯集則代表任何型別的總和。因此,我們很想將這兩個概念統整為一。支援 ADT 的程式設計語言 (例如 ML 或 Rust) 採用這種做法。
不過,就版面配置而言,只有單元型別 (列舉) 的總和型別,比可擴充的對應項目 (聯集) 更有效率。雖然兩者都提供擴充性,可新增成員,但只有聯集提供擴充性,可從單元型別 (例如 struct
{}) 擴充至任何型別。但這種可擴充性會耗用內嵌信封。
我們選擇了實用的方法,兼顧兩種建構體的複雜性,以及列舉特例的效能優勢。
參考資料
語法
可擴充的方法引數
型別別名和具名型別
Footnote2
雖然偏好語法簡潔而非明確選擇包裝型別可能看似奇怪,但有合理的預設值可讓 FIDL 程式庫中的列舉保持一致。這項功能可提供遷移路徑,以便日後切換列舉,例如程式庫定義一般用途的 ErrorStatus 列舉時,稍後可替換為另一個「更好」的一般用途 ErrorStatusV2。
-
或者至少要充分瞭解線路格式並謹慎處理,例如: https://fxrev.dev/360015 ↩