
| RFC-0117:元件模糊測試架構 | |
|---|---|
| 狀態 | 已接受 |
| 區域 |
|
| 說明 | Fuchsia 原生跨程序模糊測試架構。 |
| 問題 | |
| Gerrit 變更 | |
| 作者 | |
| 審查人員 | |
| 提交日期 (年-月-日) | 2021-05-24 |
| 審查日期 (年-月-日) | 2021-07-28 |
摘要
導向模糊測試是減少錯誤並提高平台信賴度的有效方法,但目前沒有可用的模糊測試框架,能夠跨越多個程序界線進行模糊測試,如 Fuchsia 元件拓撲所示。本文建議這類架構的設計,可在程序和測試領域之間共用涵蓋範圍和測試輸入,讓元件以最典型的設定進行模糊測試。
提振精神
程式測試可用於顯示錯誤的存在,但絕不能顯示錯誤不存在!
導向模糊測試是指在回饋迴圈中,使用產生的資料測試軟體的程序:
- 模糊測試器會產生一些測試輸入資料,並用來測試目標軟體。
- 如果測試結果為失敗,模糊測試器會記錄輸入內容並結束。
- 目標軟體會產生 意見回饋,並由模糊測試器收集。
- 模糊測試器會根據意見回饋產生其他測試輸入內容,並重複執行。
引導式模糊測試非常適合找出與專案需求無關 (因此通常未經測試) 的軟體錯誤。自動化測試涵蓋範圍也能提升開發人員對系統重要部分的信心,這些部分需要考慮安全性、正確性和/或穩定性。
引導式模糊測試架構可使用下列分類法說明:
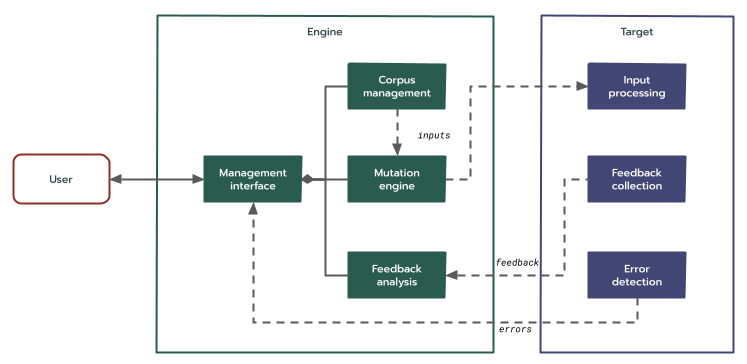
- 引擎:與目標無關的回饋迴路。
- 語料庫管理:維護模糊測試輸入內容的集合 (語料庫)。記錄新輸入內容並修改現有內容 (例如合併)。
- 種子語料庫是一組手動建立的初始輸入內容。
- 即時語料庫:系統會持續更新這組生成的輸入內容。
- 突變器:一組突變策略和確定性偽隨機來源,用於從語料庫建立新輸入內容。
- 意見回饋分析:根據意見回饋處置輸入內容。
- 管理介面:與使用者互動,協調工作流程:
- 使用特定輸入內容執行目標,也就是執行單一模糊測試器執行。
- 對目標執行模糊測試,也就是執行 (可能無限期) 一連串的模糊測試。
- 分析或操控特定語料庫。
- 回應偵測到的錯誤,和/或處理導致錯誤的構件。
- 語料庫管理:維護模糊測試輸入內容的集合 (語料庫)。記錄新輸入內容並修改現有內容 (例如合併)。
- 目標:要模糊處理的特定目標領域。
- 輸入處理:將單次執行的模糊測試器輸入內容對應至受測程式碼,例如透過特定函式、I/O 管道等。
- 收集意見回饋:觀察輸入內容造成的行為。可能會收集硬體或軟體追蹤記錄、程式碼涵蓋範圍資料、時間等。
- 錯誤偵測:判斷輸入內容何時導致錯誤。收集及記錄測試構件,例如輸入內容、記錄、回溯等。
其中有幾項可能需要作業系統和/或工具鍊的特定支援,例如意見回饋收集和錯誤偵測。目前在 Fuchsia 上,最受支援的模糊測試架構是 libFuzzer,這個架構會透過預先建構的 clang 工具鍊,以編譯器執行階段的形式提供。我們已在用於收集程式碼涵蓋率意見回饋的 sanitizer_common 執行階段,以及 libFuzzer 本身中新增支援功能,以偵測例外狀況。開發人員可搭配一組 GN 範本和主機工具,快速為 Fuchsia 上的程式庫開發模糊測試器。
不過,與 Linux 不同的是,在 Fuchsia 上,軟體的基本可執行單元是元件,而非程式庫。使用現有的導引模糊測試架構對元件進行模糊測試相當麻煩,因為這些架構的回饋細微程度不是太窄 (例如單一程序中的 libFuzzer),就是太廣 (例如 qemu 執行個體上的 TriforceAFL)。
Fuchsia 中用於模糊測試元件的理想架構應具備下列功能:
- 與現有的持續模糊測試基礎架構整合,例如 ClusterFuzz。
- 模組化方法,可運用其他模糊測試架構中與平台無關的部分,例如突變策略。
- 高效能的跨程序程式碼涵蓋率機制。
- 與現有 Fuchsia 工作流程整合,例如
ffx。 - 密封環境,可隔離受測元件,並/或為依附元件提供模擬元件。
- 目標元件的未修改來源。
- 強大且彈性的方法,可分析執行作業及偵測錯誤。
- 開發人員故事與 Fuchsia 中的其他測試樣式類似。
設計
這項設計的目標是:
- 符合 Fuchsia 的慣用語。
- 重複使用現有導入項目。
從高層次來看,這項設計會運用測試執行元件架架構,並新增下列項目:
- 用於驅動模糊測試的
fuzzer_engine。 ffx外掛程式和模糊測試管理員,可與模糊測試器互動及管理模糊測試器。fuzz_test_runner,將fuzzer_engine連線至模糊測試管理工具。
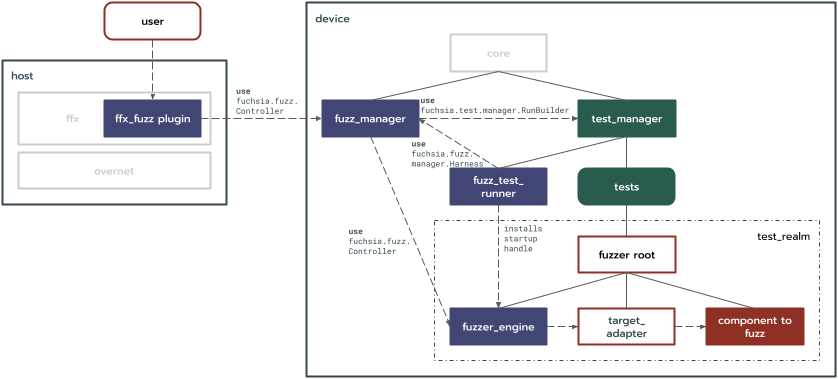
本文件大致是依據控制流程編排,也就是從想執行模糊測試工作的人員或機器人開始,逐步說明模糊測試目標領域。請注意,部分章節會提及後續章節詳細說明的概念。
ffx fuzz主辦人工具
使用者 (包括真人與機器人) 會透過ffx外掛程式與架構互動。這個外掛程式將可透過下列方式與fuzz_manager服務通訊:
fuchsia.fuzzer.Manager通訊協定。- 資料移轉通訊協定。
ffx fuzz 的子指令與 fx fuzz 的子指令相同,例如:
analyze:回報特定語料庫和/或字典的涵蓋範圍資訊。check:檢查一或多個模糊測試器的狀態。coverage:為測試產生涵蓋範圍報表。list:列出目前建構版本中可用的模糊測試器。repro:重播測試單元,重現模糊測試結果。start:啟動特定模糊測試工具。stop:停止特定模糊測試器。update:更新模糊測試語料庫的 BUILD.gn 檔案。
模糊測試管理工具
測試執行元件架構提供兩項重要功能:
- 您可輕鬆建立複雜但密封的測試領域,並透過可自訂的測試執行器加以驅動。
- 這項工具可收集重要診斷資訊,例如記錄和回溯追蹤。
此外,單一模糊測試執行作業可以自然地以元件測試架構的術語表示:程式碼會使用指定的測試輸入內容執行,並根據是否發生錯誤,視為通過或失敗。
不過,模糊測試與其他形式的測試不同,而且與持續測試相比,持續模糊測試的差異更明顯:
- 測試輸入內容無法事先得知。
- 模糊測試會產生測試輸入。
- 持續模糊測試基礎架構 (例如 ClusterFuzz) 會有多個模糊測試工具執行個體,並在模糊測試進行期間「交叉傳播」測試輸入內容。
- 模糊測試執行作業沒有時間限制。模糊測試永遠不會真正「通過」,只會失敗或提早停止。
- 因此,您必須提供隨選狀態,包括其他測試通常不會提供的詳細資料,例如執行速度、收集到的意見回饋總數、耗用的記憶體等。
- 這個狀態必須持續提供給監控模糊測試器執行的專人或模糊測試基礎架構機器人。
- 模糊測試結果比單純的通過/失敗更豐富。
- 如果失敗,輸出內容必須包含觸發輸入內容,以及任何相關聯的記錄和回溯。
- 提早終止時,輸出內容可能包含累積的回饋和建議參數 (例如字典),供日後模糊測試使用。
- 模糊處理的領域可用於 模糊測試基礎架構選擇依序執行的多個不同工作流程,例如「模糊測試一段時間。如果發現錯誤,請清除錯誤,否則請合併並壓縮語料庫。將每個步驟都視為測試套件,會導致大量工作從一個步驟中擷取狀態,然後在下一個步驟中還原狀態。
其中部分問題可透過擴充測試執行元件架構解決,例如提供結構化輸出內容。不過,如果將這種方法用於所有模糊測試需求,會為不需要這些功能的其他測試新增大量功能。因此,設計會新增 fuzz_manager,以:
- 透過
ffx為使用者提供管理介面。 - 與
test_manager互動,在測試執行元件架構的模糊測試領域中啟動模糊測試器。 - 為這些模糊測試器提供
fuchsia.fuzzer.manager.Harness,以便連線回來並處理使用者要求。 - 提供資料移轉通訊協定,方便將資料注入模糊測試器或從中擷取資料。
然後,測試執行工具架構會修改如下:
- 新增
fuzz_test_runner。這個執行元件會以現有的elf_test_runner為基礎,啟動fuzzer_engine並將模糊測試器網址傳遞給該執行器。 test_manager已修改為將fuchsia.fuzzer.manager.Harness能力路徑設定為fuzz_test_runner。這項能力不會導向測試,非模糊測試工具的密封性也不會受到影響。fuzz_test_runner會為fuchsia.fuzzer.Controller通訊協定建立管道配對。它會將一端安裝為fuzzer_engine中的啟動控制代碼,並使用fuchsia.fuzzer.manager.Harness將另一端傳遞至fuzz_manager。
模糊測試引擎
fuzzer_engine 是模糊處理領域的元件。就模糊測試器分類而言,這項功能:
- 實作
fuchsia.fuzzer.Controller通訊協定,提供管理介面。 - 建立及使用儲存空間能力,管理每個語料庫。
- 突變主體中的輸入內容,以建立新的測試輸入內容。(例如連結 libMutagen)。
UsesAdapter能力,可傳送要處理的新輸入內容。Exposes一項fuchsia.fuzzer.ProcessProxy能力,可供模糊測試領域中經過檢測的遠端程序使用,以提供收集到的意見回饋和回報錯誤。- 分析意見回饋。
如果將模糊測試視為一系列具有不同輸入內容的測試,其中一種方法是讓模糊測試引擎為每個輸入內容例項化新的測試領域,也就是讓測試執行器依序執行每個模糊測試執行。這種做法的主要問題是回饋分析和變動迴圈的效能。模糊測試器的品質與處理量直接相關,且主要迴圈必須極快:「變動、處理輸入內容、收集意見回饋及分析意見回饋」的負擔應以微秒為單位。
因此,模糊測試引擎會以類似於測試複雜拓撲所用測試驅動程式庫的方式,納入測試領域本身。由 eventpairs 協調的共用 VMO 用於將測試輸入內容傳輸至模糊測試目標介面卡,並以盡可能低的延遲時間,從經過檢測的遠端程序取得意見回饋。
模糊測試引擎由 fuzz_test_runner 啟動。這個執行元件與現有的 elf_test_runner 極為相似,但新增了一項重要功能:為 fuchsia.fuzzer.Controller 通訊協定建立管道配對。並將其中一端安裝為 fuzzer_engine 中的啟動控制代碼。它會使用 test_manager 路由傳送至 fuchsia.fuzz.manager.Harness 的能力,將其他項目傳遞至 fuzz_manager。這樣一來,test_manager 就只會為 fuzz_test_runner 和啟動的模糊測試器提供 Harness 能力,而不是所有測試。
目標轉接器
在 Fuzzer 分類中,模糊測試目標轉接程式會執行輸入處理角色。使用上述共用 VMO 和 eventpair,從模糊測試引擎產生的測試輸入內容,對應至與模糊測試目標領域的檢測設備遠端程序的特定互動。
這些特定互動由模糊測試器作者提供,通常是指「編寫模糊測試器」的貢獻。
模糊測試器作者可以提供自己的模糊測試目標介面卡自訂實作項目,也可以使用其中一個提供的架構。
可能的介面卡架構範例如下:
llvm_fuzzer_adapter:作者應實作 LLVM 的模糊測試目標函式。- 如果是 C/C++,作者會實作:
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size);- 如果是 Rust,作者會使用
#[fuzz]proc_macro屬性實作方法。 - 對於 Go,作者會實作:
func Fuzz(s []byte);realm_builder_adapter:除了 LLVM 模糊測試目標函式,作者還會實作修改所提供RealmBuilder的方法。這個函式會提供預設建構工具,並使用結果建構要模糊測試的元件領域。作者可以新增其他路徑、功能、模擬等,藉此修改該檔案:pub trait FuzzedRealmBuilder { fn extend(builder : &mut RealmBuilder); }libfuzzer_adapter:與llvm_fuzzer_adapter類似,但其元件資訊清單會省略模糊測試器引擎、公開Controller能力本身,並直接連結至 libFuzzer。這種截然不同的元件拓撲,可讓您在這個架構中,使用 libFuzzer 進行傳統程式庫模糊測試。honggfuzz-persistent-adapter:預期模糊測試作者會實作:extern HF_ITER(uint8_t** buf, size_t* len);目前不支援
honggfuzz本身,但為其編寫的模糊測試目標函式仍可與這個架構整合。
請注意,目標介面卡可以 (也應該) 連結至遠端程式庫,並與經過插碼的目標中的介面卡一起做為經過插碼的遠端程序。
檢測設備遠端程序
如要收集意見回饋及偵測錯誤,所有模糊測試目標領域內的程序都必須使用額外的檢測點 (例如 SanitizerCoverage) 建構。如果是樹狀結構內建的模糊測試器,可以透過工具鍊變體達成此目的,將 flags 和 deps 傳播至 GN 目標的依附元件。必要旗標 (例如 -fsanitize-coverage=inline-8bit-counters) 也會記錄在文件中,以便進行樹狀結構外的編譯。
此外,這些程序也需要 fuchsia.fuzzer.ProcessProxy 用戶端實作。如上所述,相同的工具鍊變體可以自動將依附元件新增至連結程序,以針對遠端程式庫的樹狀結構內模糊測試器。
就模糊測試分類而言,遠端程式庫提供:
- 透過回呼收集意見回饋,例如
__sanitizer_cov_inline_8bit_counters_init。 - 在啟動初期連線至
fuzzer_engine的ProcessProxy。 - 可偵測錯誤的背景執行緒,例如監控例外狀況、記憶體用量等。
樹外模糊測試器可以提供自己的用戶端實作項目。在 SDK 中新增 fuchsia.fuzzer.ProcessProxy FIDL 介面和遠端程式庫實作,可簡化樹狀結構外的模糊測試器編寫作業。
最後,所需的編譯時間修改作業只會轉換 LLVM IR。所有其他修改作業都只會在連結時間進行。這項功能可讓服務供應商為願意提供元件 LLVM 位元碼的 SDK 消費者提供「模糊測試即服務」,無須提供原始碼。
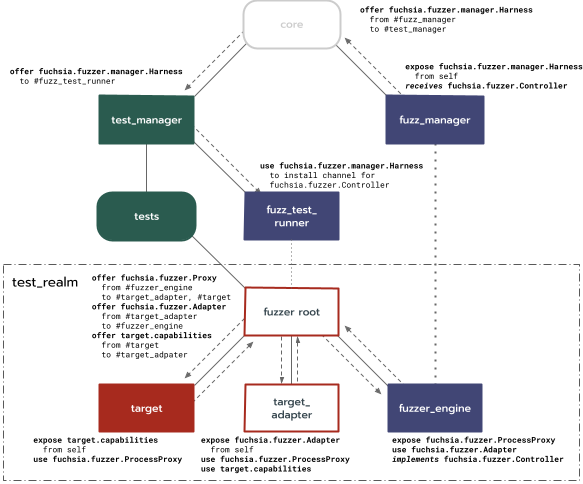
元件拓撲
綜合上述所有內容,模糊測試器元件拓撲包括:
core:系統根元件。fuzz_manager:模糊測試器與主機工具之間根領域的橋接器。test_manager:如執行元件架構所示。target_fuzzer:模糊處理的領域進入點。fuzzer_engine:與目標無關的模糊測試驅動程式庫。target_adapter:特定目標的元件,其中包含使用者提供的輸入處理程式碼。instrumented_target:正在模糊處理的元件。
adapter 和 target 元件可能會有其他子項,例如模擬和模糊處理的目標領域。
上述各個部分之間的互動方式如下圖所示:
FIDL 介面
架構會新增兩個 FIDL 程式庫:一個用於與 fuzz_manager 互動,另一個用於與模糊測試器本身互動。
fuchsia.fuzzer.manager
fuchsia.fuzzer.manager 定義的型別包括:
LaunchError:可擴充的enum清單,列出與尋找及啟動模糊測試器相關的錯誤。
fuchsia.fuzzer.manager 定義的通訊協定包括:
fuchsia.fuzzer.manager.Coordinator:由fuzz_manager透過ffx提供給使用者。包括啟動模糊測試器和連結fuchsia.fuzzer.Controller的方法,以及停止模糊測試器的方法。fuchsia.fuzzer.manager.Harness:由fuzz_manager透過core和test_manager的靜態路由,提供給fuzz_test_runner。執行器會使用這個通訊協定,將管道的一端傳遞至管理員,以用於fuchsia.fuzzer.Controller通訊協定。
fuchsia.fuzzer
fuchsia.fuzzer 定義的型別包括:
Options:可擴充的table,內含用於設定執行作業、錯誤偵測等的參數。Feedback:代表目標意見回饋的彈性union,例如程式碼涵蓋範圍、追蹤記錄、時間等。Status:可擴充的table,具有各種模糊測試指標,例如總涵蓋範圍、速度等。FuzzerError:可擴充的enum清單,列出錯誤類別,例如 ClusterFuzz 識別的錯誤類別。
fuchsia.fuzzer 定義的通訊協定包括:
fuchsia.fuzzer.Controller:由fuzzer_engine提供,並透過fuzz_test_runner傳遞至fuzz_manager。由fuzz_manager向使用者發出。包括將輸入內容或構件傳輸至模糊測試器或從模糊測試器傳輸的方法,以及在模糊測試器上執行工作流程,例如輸入內容縮減、語料庫合併和正常模糊測試。fuchsia.fuzzer.CorpusReader:向fuchsia.fuzzer.Controller要求。 用於從特定種子或即時語料庫取得輸入內容。fuchsia.fuzzer.CorpusWriter:向fuchsia.fuzzer.Controller要求。 用於將輸入內容新增至特定種子或即時語料庫。fuchsia.fuzzer.Adapter:由開發人員提供的target_adapter提供給fuzzer_engine。包括註冊協調事件配對的方法,以及用於傳送測試輸入內容的共用 VMO。fuchsia.fuzzer.ProcessProxy:由fuzzer_engine提供給模糊測試領域中的每個檢測程序。包括註冊協調事件配對的方法,以及註冊用於提供意見回饋的共用 VMO。
建構公用程式
這個架構會為開發人員提供 fuchsia_fuzzer_package GN 範本。這樣他們就可以:
- 自動加入 fuzzer_engine。
- 產生可供工具使用的中繼資料,例如種子語料庫的位置。
- 選取非模糊測試工具鍊變數時,請建構整合測試,而非模糊測試器,詳情請參閱「測試」一節。
- 從相關整合測試中,重複使用受測元件的建構規則。
這個框架也包含元件資訊清單分片,其中包含模糊測試器所需的常見元素,例如 fuzzer_engine 及其能力、fuzz_test_runner 等。模糊測試器的元件資訊清單包含:
- 預設模糊測試器分片。
- 目標介面卡元件的網址。
- 要模糊處理的元件資訊清單網址。這通常應可從相關整合測試重複使用。
這些建構公用程式的設計宗旨,是讓模糊測試器開發體驗與整合測試開發體驗類似。比較:

實作
實作計畫很簡單:在一連串的變更中開發及單元測試個別類別,然後如「測試」一節所述,從 libFuzzer 衍生整合測試。
語言
fuzzer_engine 和 remote_library 是以 C++ 實作,可簡化其特質:
fuzzer_engine和remote_library都必須與其他 CABI 整合,例如 libMutagen、SanitizerCoverage 等。- 大部分
remote_library功能都發生在「main之前和之後」,也就是建構和/或載入 LLVM 模組時、執行atexit處理常式時,或引發嚴重例外狀況時。exit因此,架構需要明確控管 ELF 執行檔生命週期的細微細節。
其他部分 (例如 realm_builder_adapter) 則是以 Rust 編寫。
資料移轉通訊協定
使用者可能需要在多種情況下提供或擷取任意資料量,包括:
- 提供特定測試輸入內容,以執行、清除或減少。
- 將模糊測試器語料庫與開發人員主機上的語料庫同步,或跨多個 ClusterFuzz 執行個體同步。
- 擷取觸發錯誤的測試輸入內容。
為盡量減少維護負擔,建議使用 overnet 轉移這項資料。不過,任何單一轉移作業都可能超出 Zircon 管道中單一 FIDL 訊息的大小。相反地,Controller 通訊協定包含多種方法,可提供 zx_socket 物件,模糊測試引擎會使用這些物件,將資料串流至 VMO 和/或本機儲存的檔案,或從這些位置串流資料。
資料會透過最小通訊協定串流傳輸,以讀取或寫入具名位元組序列。由於傳送的資料可能超過 FIDL 訊息長度上限,因此通訊協定「並非」FIDL。但具名位元組序列在概念上等同於下列 FIDL 結構體:
struct NamedByteSequence {
uint32 name_length;
uint32 size;
bytes:name_length name;
bytes:size data;
};
堆疊回溯
目前 libFuzzer 使用 LLVM 的 unwinder,並假設 unwinder 是從 POSIX 信號處理常式呼叫,且該常式是在觸發信號的執行緒上執行。對於 Fuchsia,這需要複雜的例外狀況處理方法,包括修改當機執行緒的堆疊,以及插入保留回溯的組語跳板,以便在 unwinder 中「復活」執行緒。
如果 libFuzzer 未處理錯誤,則不需要上述任何項目。而是以最方便有效的方式處理不同類型的錯誤,例如:
- 例外狀況由 模糊測試引擎處理,該引擎會從模糊測試執行元件接收例外狀況管道,而執行器是從測試工作的控制代碼建立。
- 逾時也由模糊測試引擎管理。
- 清除器回呼和 OOM 會由遠端程式庫處理,並通知模糊測試引擎。
效能
模糊測試不會在正式版系統上執行,因此不會影響任何出貨程式碼的效能。雖然納入模糊測試工具鍊變體會對建構 Fuchsia 的效能造成輕微影響,但這個框架會重複使用現有變體,因此不會造成新的影響。
同樣地,從未插樁建構作業的模糊測試器產生單元測試,也與目前的方法類似,預計不會比目前的方法增加任何顯著的模糊測試器測試成本。
就模糊測試器本身而言,判斷模糊測試器品質最關鍵的指標是單位時間涵蓋範圍,這可透過測量兩項額外指標得出:
- 在固定時間內執行的模糊測試器涵蓋範圍總計。
- 在固定時間內執行的總次數。
ClusterFuzz 已在資訊主頁上監控及發布每個模糊測試器的指標。
人體工學
人體工學是這項設計的重要環節,因為其影響取決於開發人員的採用情況。
這個架構嘗試透過多種方式,盡可能簡化模糊測試。開發人員可透過這項功能執行下列操作:
- 如「目標介面卡」一節所述,以熟悉且彈性的方式編寫模糊測試器。
- 使用現有的 GN 模糊測試範本系列建構模糊測試器。
- 使用熟悉的工作流程執行模糊測試器。
ffx fuzz的用法刻意與fx fuzz相似。 - 取得可做為修正依據的結果。與 ClusterFuzz 整合後,系統會自動回報錯誤,並附上符號化的回溯追蹤和重現說明。
回溯相容性
現有的 libFuzzer 基礎模糊測試工具會實作模糊測試目標函式。只要提供 libFuzzer 專用的模糊測試目標轉接器,這些模糊測試器就能在這個架構中運作,不必修改任何來源。
安全性考量
這個架構不會用於正式版產品設定。對於以模糊測試設定建構的裝置,與裝置之間的通訊會使用 overnet 和 ffx 提供的現有驗證和安全通訊功能。
模糊測試器輸出內容可能涉及安全考量,例如測試輸入內容可能導致可供利用的記憶體損毀。這些疑慮「必須」由模糊測試人員 (真人或模糊測試基礎架構) 處理,方式與任何其他可供利用的錯誤報告相同 (例如正確標示、防止未經授權揭露等)。
隱私權注意事項
考量隱私權影響時,我們不會假設模糊測試人員如何處理模糊測試輸出內容。這些輸出內容包括符號化記錄、導致錯誤的輸入內容、產生的字典和產生的語料庫。我們假設記錄檔中已沒有使用者資料,因為這是另一個受到嚴密監控的隱私權問題。其餘輸出內容皆直接衍生自測試輸入內容。因此,只要確保模糊測試器輸入內容不含使用者資料,就能確保模糊測試器輸出內容不含使用者資料。
將輸入內容新增至模糊測試器語料庫的方式有三種:
- 做為種子輸入內容。種子語料庫應簽入來源存放區。 通常禁止在來源存放區中加入使用者資料的限制也適用。
- 手動新增至即時語料庫。
- 這項作業通常會由模糊測試基礎架構 (例如 ClusterFuzz) 執行,因為這類基礎架構會將其他執行個體產生的輸入內容「交叉傳播」給模糊測試器。在這種情況下,其他執行個體不會包含使用者資料,新增的輸入內容也不會。
- 人類操作員也可以透過
ffx新增輸入內容。 以這種方式新增手動輸入內容時,工具會顯示使用者資料相關警告。
- 做為即時語料庫的生成內容。這些輸入內容是從現有輸入內容突變而來。由於這些輸入內容不含使用者資料,因此產生的內容也不會包含。某些輸入內容可能純粹是巧合,例如模糊測試器設法產生有效的使用者名稱。不過,在本例中,這類資料與使用者資料沒有明確關聯。
即使模糊測試器並非密封 (且不具決定性!),並使用測試領域公開的來源資料,語料庫也不會包含其他資料。架構不會將該資料視為測試輸入內容的一部分,也不會儲存該資料。
最糟的情況是,模糊測試器刻意設計成非密封式,並使用公開功能將資料傳送到測試領域外,交由其他服務驗證 PII,例如傳回使用者名稱是否有效。這需要投入大量心力,才能規避模糊測試和測試架構為鼓勵密封性所做的嘗試。此外,由於外部服務未經過儀器化,這與隨機猜測沒有什麼不同。
此外,在實務上,模糊測試器會完全密封。這些測試不會在含有使用者資料的產品設定中執行,只會在開發模糊測試器時在本機執行,以及在 ClusterFuzz 上執行。
測試
模糊測試引擎、目標轉接程式庫和遠端程式庫會使用一般方法 (例如 GoogleTest、#[cfg(test)] 等) 進行單元測試。此外,整合測試會使用預設 ELF 測試執行元件,根據適用的 subset from compiler-rt,執行一組搭配專用範例目標的模糊測試工作流程。
對於使用框架編寫的模糊測試器,框架會採用與 GN 模糊測試器範本目前支援的相同方法:在未插碼的建構版本中建構模糊測試器時,引擎會由測試驅動程式庫取代,該程式只會執行種子語料庫中的每個輸入內容。這可確保所有模糊測試器都能建構及執行,進而減輕「位元腐敗」問題。此外,這項工具也能做為迴歸測試,特別是當模糊測試作者在修正模糊測試發現的缺陷時,會新增輸入內容來維護種子語料庫。
說明文件
模糊測試文件樹狀結構需要更新,並提供使用新 GN 範本的具體範例。其他計畫中的文件變更 (例如程式碼研究室等) 也應反映這個架構。
缺點和替代方案
建議方法可能有的缺點包括:
- 效能可能降低,但可透過實作密切模仿高度最佳化模糊測試器效能關鍵部分的內容來減輕影響。
- 維護負擔,但可省下維護不便整合的成本,例如 POSIX 模擬。
- 耦合風險,例如測試執行器架構可能會在未來以某種方式變更,導致這項設計中斷,或可能因為這項設計而無法變更。如果日後發生問題,可以將更多
test_manager的功能直接併入fuzz_manager,例如讓後者直接建立獨立的測試領域,即可解決。
這些缺點不像其他替代方案那麼嚴重:
只能使用 libFuzzer 進行程式庫模糊測試。
libFuzzer 已新增足夠的 Fuchsia 支援功能,可讓您在 Fuchsia 上使用 libFuzzer 建構模糊測試器。過去幾年,這些計畫已成功找出數百個錯誤。
但同時也僅限於以程式庫形式建構的單一程序。由於元件是 Fuchsia 上可執行的軟體單元,且元件會透過 FIDL 大量通訊,因此這種方法會導致大量且不斷增加的 Fuchsia 程式碼「無法模糊處理」。
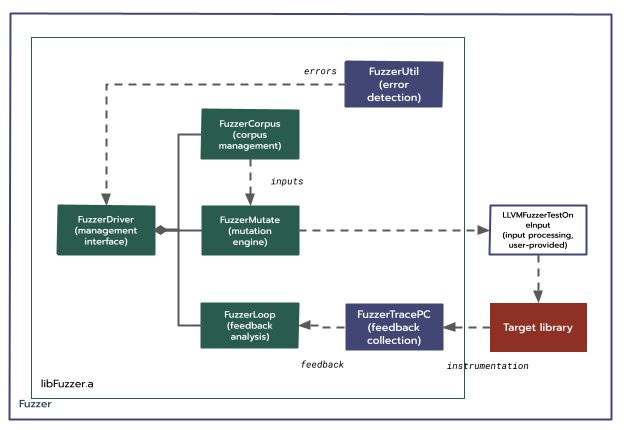
程序內 FIDL 模糊測試。
Chrome 等專案嘗試在單一程序中執行用戶端和伺服器執行緒,以解決遠端程序呼叫 (RPC) 模糊測試問題。這需要修改用戶端和伺服器,才能以新的非標準設定執行。這可以在服務之間重複使用,但往往會對元件生命週期做出不靈活的假設,和/或針對每個語言繫結重新實作。
從根本上來說,互動式元件的封閉性越來越難模糊。許多元件的拓撲結構都相當複雜。就複雜度、額外負荷和效能而言,要執行或模擬整個結案程序,很快就會變得難以維持。
Fuchsia 已提供這個方法,但由於上述限制,尚未廣泛採用。
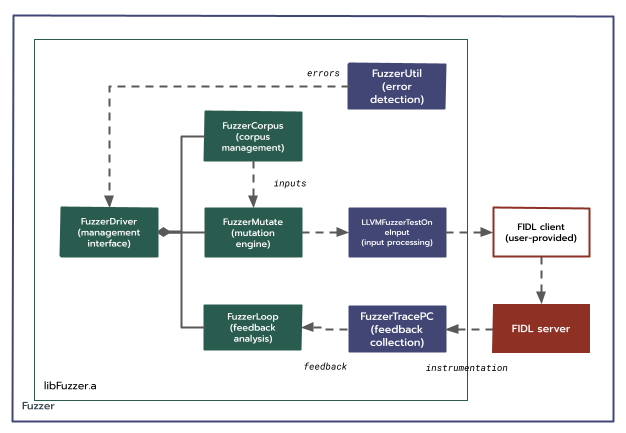
單一服務 FIDL 模糊測試。
在設計跨程序 FIDL 模糊測試架構的初步嘗試中,我們考慮了單一用戶端和服務。在這個設計中,libFuzzer 會連結至服務,而用戶端則會維持簡單的 Proxy。保留用戶端與伺服器之間的 FIDL 介面,可讓目標維持在更典型的設定中,進而提供更彈性的服務生命週期,並減少需要重新實作的程式碼。
不過,這無法解決模糊測試元件關閉的問題,因此與程序內 FIDL 模糊測試相比,效益非常有限。
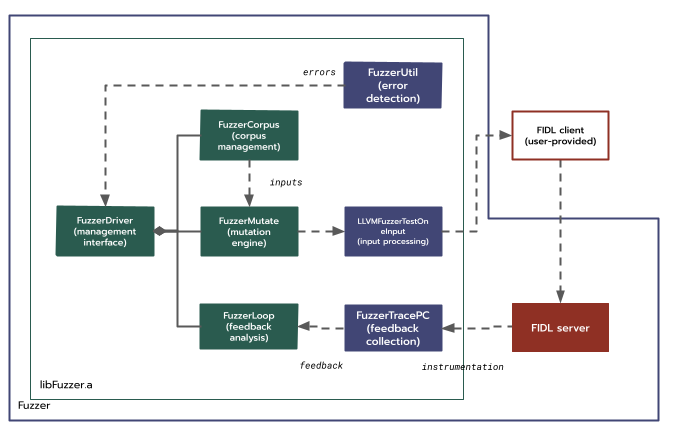
支援跨程序模糊測試的 LibFuzzer。
一般來說,重複使用程式碼比重新實作程式碼有幾個優點:程式碼通常更「成熟」,效能更好、錯誤較少,而且維護成本較低且可共用。基於上述原因,先前的嘗試是擴充 libFuzzer,而非設計及實作新的模糊測試架構。新的編譯器執行階段 clang_rt.fuzzer-remote.a 會做為上述的遠端程式庫,而 libFuzzer 本身則可做為引擎。這兩個編譯器執行階段都會使用一對 OS 專屬的 IPC 傳輸程式庫,將方法呼叫 Proxy 至其他程序。
我們與 libFuzzer 維護人員協調,在兩個執行階段實作了一系列變更,並發布以供審查。此外,我們也為 Linux 和 Fuchsia 開發了 IPC 傳輸程式庫的實作項目。維護人員明確要求支援 Linux,以利持續測試,因此再次送交審查。
- 在 Linux 上,共用記憶體是透過
memfd_create建立為匿名對應檔案,而訊號只是透過 Unix 網域通訊端傳遞的訊息。這些通訊端也用於傳輸共用記憶體檔案描述元,也就是透過sendmsg和recvmsg。 - 在 Fuchsia 上,共用記憶體是使用 VMO 實作,信號是透過 eventpair,交換是透過 FIDL 訊息,方式與本提案中的設計類似。
很遺憾,在延長審查期間,我們發現這個方法不可行,並非技術問題,而是程序問題:隨著時間推移,libFuzzer 維護人員越來越擔心,為了讓 libFuzzer 執行原本並非設計用途的動作,需要進行的變更範圍越來越廣。最後,團隊決定無限期延後提議的變更。
AFL
LibFuzzer 絕非唯一的模糊測試架構。有些 (例如 AFL) 從一開始就明確設計為跨程序。不過,有幾個原因會導致 AFL 需要的投資超出預期:
- AFL 假設要模糊測試單一程序,因此仍面臨關閉問題。
- AFL 會大量使用特定 Linux 和/或 POSIX 功能,進行意見回饋和錯誤偵測。包括 POSIX 信號,但更重要的是,大量使用
/proc檔案系統,而 Fuchsia 上 (正確地) 沒有類似的檔案系統。 - AFL 使用修改過的 GCC 來檢測程式碼,但這並非 Fuchsia 工具鍊的一部分。
AFLplusplus 是 AFL 的改良分支版本,由一組安全研究人員和 CTF 競賽者維護。在 FuzzBench 上表現優異,且已模組化 AFL。很抱歉,第一個版本已淘汰,第二個版本尚未推出 (或至少還不夠成熟,無法強制變更上述設計)。不過,有幾項功能與這項提案的設計一致,未來有機會整合這些功能,以提升架構的涵蓋範圍和速度,或兩者兼具。
搭配 QEMU 使用 AFL
此外,也有幾個專案結合了 AFL 和 qemu:
- afl-unicorn 結合了 AFL 和 Unicorn,這個專案會透過相當簡潔的介面,公開 qemu 的 CPU 模擬核心。這樣一來,您就能透過 CPU 模擬收集涵蓋範圍意見回饋,對不透明的二進位檔進行模糊測試,而不必使用來源。基於以下幾項原因,這不適合做為元件架構:
- 與 qemu 的核心 CPU 模擬整合相當複雜,因此 Unicorn 決定放棄追蹤 qemu 開發作業,並鎖定 v2.1.2 (相較於目前的 qemu 6.0.0 版)。如果程式碼需要較新的模擬功能,可能就無法正常運作。
- 因此不需要進行不透明二進位模糊測試。事實上,設計只需要檢測目標程式碼,並連結至遠端程式庫;LLVM 位元組碼就足以達成此目的。
- TriforceAFL 會在完整的檢測 qemu 執行個體上使用 AFL。這項功能同樣可讓您從 qemu 本身收集涵蓋範圍,藉此對不透明的二進位檔進行模糊測試,而不必提供來源。由於與 afl-unicorn 類似的原因,這項工具並不適用:
- 同樣地,不透明二進位模糊測試的需求並不顯著。
- 此外,由於收集的涵蓋範圍是整個執行個體,因此使用 TriforceAFL 模糊測試時,往往會產生大量雜訊,尤其是在執行許多元件時。這通常只適用於模糊測試極度受限的設定,例如開機後立即執行的 USB 驅動程式庫。