
| RFC-0226:Zircon 分頁器回寫 | |
|---|---|
| 狀態 | 已接受 |
| 區域 |
|
| 說明 | 核心支援追蹤及將修改內容寫回分頁支援的 VMO |
| 問題 | |
| Gerrit 變更 | |
| 作者 | |
| 審查人員 | |
| 提交日期 (年-月-日) | 2023-04-13 |
| 審查日期 (年-月-日) | 2023-09-19 |
摘要
本文說明 Zircon 核心對分頁支援記憶體的支援,這類記憶體可以修改,然後寫回 (同步) 分頁來源,例如儲存磁碟。
提振精神
Zircon 支援建立由使用者空間分頁服務支援的 VMO (虛擬記憶體物件),通常由檔案系統代管。記憶體中的個別檔案會以 VMO 表示。存取 VMO 的頁面時,系統會視需要將這些頁面錯誤地讀取到使用者分頁器中,並從磁碟讀取頁面內容。
Zircon 分頁器 API 原本只支援唯讀檔案,沒有任何機制可將記憶體中已遭汙損的 VMO 頁面寫回磁碟。這項設計足以代管不可變動的檔案系統 (例如 blobfs),可提供 Fuchsia 上的所有可執行檔和其他唯讀檔案。不過,如果是一般用途的檔案系統,用戶端可以修改檔案內容,且需要同步回磁碟,就必須支援回寫。
如果沒有回寫支援,minfs 和 fxfs 等可變動的檔案系統就無法利用隨選分頁。做為解決方法,可變動的檔案系統必須使用匿名 (非分頁支援) VMO,將檔案快取在記憶體中,並自行管理這些 VMO 的內容。即使很少或從未存取這些 VMO 中的特定頁面,這些 VMO 可能仍需完整保留在記憶體中。將這些匿名 VMO 切換為分頁支援的 VMO,讓系統視需要錯誤地移入及逐出分頁,可變動的檔案系統就能更有效率地運用記憶體。此外,有了回寫支援,可變動檔案系統的用戶端就能直接對 VMO 執行讀取和寫入作業,而不必依賴資料傳輸管道,因為管道受限可能會非常緩慢。
在本文件的其餘部分,視情況會交替使用「使用者分頁」和「檔案系統」這兩個詞彙。
利害關係人
協助人員:
- cpu@google.com
審查者:
- adanis@google.com、csuter@google.com
已諮詢:
- brettw@google.com、cdrllrd@google.com、godtamit@google.com、 maniscalco@google.com、travisg@google.com
公共平台:
這項 RFC 經過 Local Storage 團隊的設計審查。
需求條件
建議的設計可達成下列目標:
- 強化 Zircon,支援將分頁支援的 VMO 寫回,以便建構高效能的可變動檔案系統 (使用 Zircon 串流)。
- 透過 VM 對應支援檔案讀取和寫入 (類似
mmap檔案)。 - 提供使用者分頁啟動最佳盡力清除髒頁面,以降低因非預期關機而導致資料遺失的風險。
- 在日後的疊代中,允許核心 (透過使用者分頁器) 驅逐髒頁面,以回應系統記憶體壓力。
此外,本課程不會涵蓋下列主題:
- 除了使用者分頁啟動的排清作業外,核心不會保證清除髒頁面的速率。不過,未來演進版本可能會新增功能,限制未處理的髒資料量,並讓核心根據該數量啟動回寫要求。
- 防止因違反核心/分頁通訊協定而導致資料遺失,並非本專案的目標。如果使用者分頁器無法查詢髒頁面,並在關閉 VMO 控制代碼 (或終止) 前將這些頁面寫回,就可能會發生資料遺失情形。
設計
總覽
提案設計旨在支援以下兩種立即應用情境:
- 檔案系統用戶端可透過串流存取檔案,串流是封裝檔案 VMO 的核心物件。這大致上可以視為類似
zx_vmo_read()和zx_vmo_write(),因為串流系統呼叫會在內部包裝 VMO 讀取/寫入核心常式。 - 檔案系統用戶端也可以
mmap檔案,這大致上會轉譯為將檔案 VMO (使用zx_vmar_map) 對應至用戶端程序的位址空間。
為求簡潔,本文其餘部分將說明如何透過系統呼叫 (zx_vmo_read/write) 或 VM 對應 (zx_vmar_map) 直接與檔案 VMO 互動。
以下列舉幾個範例,說明涉及回寫的互動情形。
示例 1
- 檔案系統用戶端會針對特定範圍,在檔案 VMO 上執行
zx_vmo_read()。 - 由於 VMO 是以分頁為基礎,核心會為相關聯的使用者分頁產生讀取要求。
- 檔案系統代管的使用者分頁程式會完成這項要求。從磁碟讀取內容,並提供給網頁。
- 檔案系統用戶端會對相同範圍的 VMO 執行
zx_vmo_write()。VMO 的頁面先前已在步驟 3 中填入,因此可以直接寫入。目前所做的修改只會儲存在記憶體中,但之後必須反映在磁碟上。 - 使用者分頁器會向核心查詢 VMO 中已變更 / 修改的範圍。這項作業可以做為檔案系統定期背景清除作業的一部分,也可以回應檔案系統用戶端要求清除作業。
- 使用者分頁器會將查詢到的髒範圍寫回磁碟。此時,修改後的檔案內容已成功保存到磁碟。
示例 2
- 檔案系統用戶端會使用
zx_vmar_map()對應檔案 VMO。對應作業會從地址addr開始。用戶端會讀取從addr開始的範圍。 - 與範例 1 相同。
- 與範例 1 相同。
- 檔案系統用戶端現在會寫入從
addr開始的相同範圍。基礎網頁已填入內容,因此內容會在記憶體中修改。修改內容必須在某個時間點反映回磁碟。 - 與範例 1 相同。
- 與範例 1 相同。
這裡的範例會先執行 VMO 讀取,再執行寫入。請注意,這麼做只是為了將使用者翻頁元素中的網頁群組分成獨立步驟,為求明確。用戶端可以直接寫入尚未在記憶體中的檔案偏移,寫入作業會遭到封鎖,直到使用者分頁程式先提供該頁面為止。
上述兩個範例都假設檔案系統遵循寫入的覆寫模型,也就是說,系統可以直接寫入已填入 (已提交) 的頁面,不必先要求額外空間。修改後的內容會寫回磁碟上的相同位置,因此不需要為修改內容分配額外空間。不過,fxfs 和 minfs 等檔案系統採用寫入時複製 (CoW) 模型,因此每次修改都必須在磁碟上分配新空間。因此,我們也需要一種機制,為已提交的頁面保留寫入空間;步驟 4 會經過修改,在寫入作業繼續進行前,先等待該保留項目。
如要執行回寫作業,Zircon 分頁器 API 會擴充,以支援下列項目:
- 核心會封鎖寫入使用者分頁器所指出應遵循「寫入時複製」配置的 VMO,並在使用者分頁器確認寫入後繼續。
- 核心會追蹤 VMO 中的髒頁面,並提供機制,將該資訊顯示給使用者分頁器。
- 使用者分頁程式會向核心指出何時同步處理 VMO 中的髒範圍,以及何時完成同步處理,以便核心相應更新髒追蹤狀態。
- 核心也會向使用者分頁程式顯示 VMO 大小調整資訊。
- 使用者分頁器可查詢核心代表追蹤的相關資訊,例如 VMO 的上次修改時間。
建立 Pager 和 VMO
分頁器建立系統呼叫保持不變,也就是說,系統會使用 zx_pager_create() 建立分頁器,並將 options 設為 0。
系統會使用 zx_pager_create_vmo() 建立以呼叫器為基礎的 VMO,並與呼叫器通訊埠和金鑰建立關聯,該金鑰會用於該 VMO 的頁面要求封包。zx_pager_create_vmo() 系統呼叫也支援新的 options 旗標 ZX_VMO_TRAP_DIRTY。這表示核心應攔截對 VMO 的任何寫入作業,並先向使用者呼叫器要求寫入確認。這個旗標適用於以「寫入時複製」模式運作的檔案。稍後會進一步說明這個旗標。
// Create a VMO (returned via |out|) backed by |pager|. Pager requests will be
// queued on |port| and will contain the provided |key| as an identifier.
// |size| will be rounded up to the page boundary.
//
// |options| must be 0 or a combination of the following flags:
// ZX_VMO_RESIZABLE - if the VMO can be resized.
// ZX_VMO_TRAP_DIRTY - if writes to clean pages in the VMO should be trapped by the
// kernel and forwarded to the pager service for acknowledgement before proceeding
// with the write.
zx_status_t zx_pager_create_vmo(zx_handle_t pager,
uint32_t options,
zx_handle_t port,
uint64_t key,
uint64_t size,
zx_handle_t* out);
所有分頁支援的 VMO 預設都會視為可變動,這也適用於實作唯讀檔案系統,且不需額外付費。修改網頁的程式碼路徑應該不會用於唯讀 VMO。如果 VMO 遭到修改 (可能是誤用),但使用者分頁器從未查詢其中的髒頁面,並嘗試將其寫回,修改後的內容只會保留在記憶體中。日後核心產生回寫要求時,使用者分頁器可以將這類 VMO 的回寫要求視為錯誤,也可以直接忽略。
提供 VMO 頁面
在分頁支援的 VMO 中,使用者分頁會在收到分頁讀取要求時,視需要填入頁面。zx_pager_supply_pages()這個系統呼叫已存在,可搭配唯讀 VMO 使用。
回寫的頁面狀態
以分頁器為後盾的 VMO 可以有三種狀態的頁面:Dirty、Clean 和 AwaitingClean。這些狀態會編碼在 vm_page_t 中。
三種狀態之間的轉換步驟如下:
- 新提供的頁面一開始會是
Clean。zx_pager_supply_pages() - 當頁面寫入時,會轉換為
Dirty。如果 VMO 是以ZX_VMO_TRAP_DIRTY建立,核心會先封鎖使用者呼叫器傳送的DIRTY呼叫器要求確認。稍後會詳細說明這項互動。 - 使用者分頁器會在稍後透過系統呼叫,向 VMO 查詢髒頁清單。
- 針對核心傳回的每個髒頁面,使用者分頁器會叫用系統呼叫,向核心發出信號,表示要開始寫回頁面,這會將頁面狀態變更為
AwaitingClean。 - 如果頁面寫入的內容超出這個點,狀態會切換回
Dirty。 - 使用者分頁在寫回頁面後,會發出另一個系統呼叫。
如果此時頁面狀態為
AwaitingClean,則會轉換為Clean。 - 如果使用者呼叫器在寫回時發生錯誤,頁面會停留在
AwaitingClean。日後查詢髒頁面時,會同時傳回AwaitingClean和Dirty頁面,因此使用者分頁器可以再次嘗試寫回頁面。
下圖顯示這些狀態之間的轉換。
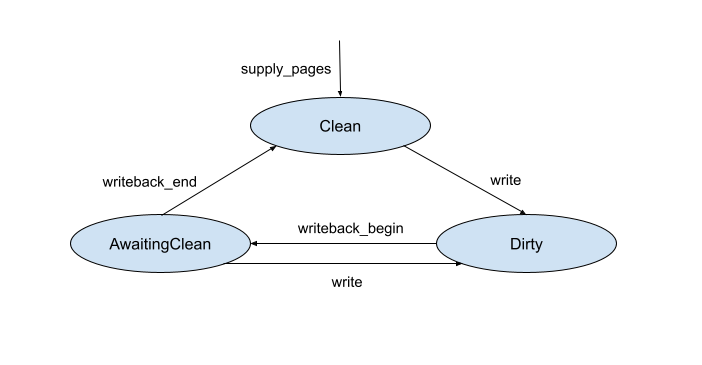
AwaitingClean 需要追蹤為個別狀態,原因如下:
即使
Clean和AwaitingClean狀態的頁面在寫入時都會轉換為Dirty,使用者分頁器正在寫回的頁面仍須與Clean頁面有所區別。在記憶體壓力下,Clean頁面符合回收資格,但正在寫回的頁面必須受到保護,以免遭到回收。核心需要知道寫回的網頁版本,才能在使用者分頁完成時,正確地將其轉換為
Clean。這項資訊很重要,因為可區分在排清前傳入的頁面寫入 (會安全地寫入磁碟),以及在排清後傳入的頁面寫入 (稍後需要寫回)。我們可以在回寫開始時避免來自使用者分頁的系統呼叫,而核心可以在將頁面傳回給使用者分頁做為髒頁面查詢的一部分時,簡單地將頁面標示為
AwaitingClean。不過,使用者分頁在查詢後可能仍需一段時間才會開始清除頁面,這會留下較長的時間視窗,讓頁面再次變髒。縮短回寫的括號時間範圍,可提高使用者分頁將網頁成功移至Clean狀態的機率。
為更新髒狀態,核心會追蹤頁面何時透過 VMO 和串流寫入系統呼叫,以及透過 VM 對映寫入。請注意,這適用於透過 VM 對應發生的任何寫入作業,無論是由使用者或核心執行,也就是說,這也適用於核心透過 user_copy 執行的寫入作業,例如 zx_channel_read()。
在 zx_vmo_write() 等系統呼叫期間推斷髒頁很簡單,因為系統會指定範圍。存取 VMO 的另一種方式,是透過程序位址空間中的 VM 對應。為了追蹤分頁支援的 VMO 中的髒狀態,可寫入的對應會先移除相應頁面表格項目中的寫入權限。因此寫入作業會產生保護錯誤,而解決方法是還原寫入權限,並將頁面狀態標示為 Dirty。
這裡所指的 Dirty 狀態是由 vm_page_t 追蹤的狀態,也就是軟體追蹤的髒狀態。x86 上的硬體頁面表格支援髒位元追蹤,但我們選擇不使用這項功能,在初始實作中衍生頁面的髒狀態。無論如何,我們都需要在軟體中追蹤髒位元,以支援不支援頁面表格中髒位元的舊版 arm64 平台。因此,為了確保實作一致性並簡化實作程序,我們選擇先不使用硬體髒位元,推斷頁面的髒 / 乾淨狀態。依賴硬體頁面表格位元也會造成頁面表格回收的複雜性,日後依賴硬體位元時,必須將這點納入考量。
請注意,只有由分頁器直接支援的 VMO 才符合髒追蹤資格。換句話說,以分頁器為後端的 VMO 的 CoW 副本不會選擇加入髒追蹤,也不會看到任何回寫要求。以副本撰寫的網頁會從父項網頁副本分出,副本會直接擁有這些網頁,視為獨立網頁。
為待處理的寫入作業保留空間
寫入標記為要使用 ZX_VMO_TRAP_DIRTY 建立選項旗標來擷取骯髒轉換的 VMO,需要檔案系統的確認。這項解決方案分為兩部分,v1 先從簡單的內容著手,著重於正確性,v2 則以 v1 為基礎,進一步提升效能。v1 提案主要採用同步模型,檔案系統會為新寫入作業保留空間。在 v2 中,我們會在核心中新增一層,用來表示髒預留配額,以及這些配額如何套用至 VMO,讓核心本身可以追蹤預留項目。這有助於減少核心和檔案系統之間的大部分來回通訊,進而提升效能。
ZX_VMO_TRAP_DIRTY v1
ZX_VMO_TRAP_DIRTY VMO 建立旗標表示核心應在 VMO 中截取任何 Clean->Dirty 頁面轉換 (或 AwaitingClean->Dirty 轉換)。當寫入作業進入尚未變更的頁面時,核心會產生 ZX_PAGER_VMO_DIRTY 分頁要求。如果是透過 VM 對應進行寫入,要求會涵蓋包含錯誤位址的單一頁面。如果是串流/VMO 寫入,核心會針對範圍內需要寫入的每個連續非髒頁面執行,傳送要求。
範圍 [start, end) 的髒要求如下所示。
zx_packet_page_request_t request {
.command = ZX_PAGER_VMO_DIRTY,
.flags = 0,
// |offset| and |length| will be page-aligned.
.offset = start,
.length = end - start,
};
ZX_VMO_TRAP_DIRTY 建立標記適用於以 CoW 模式寫入的檔案,以及覆寫模式中的稀疏檔案。如果未指定標記,系統會將網頁標示為 Dirty,並在沒有使用者呼叫器參與的情況下繼續寫入;這適用於以覆寫模式寫入的非稀疏檔案。
使用者呼叫器會透過 zx_pager_op_range() 確認 ZX_PAGER_VMO_DIRTY 要求:
ZX_PAGER_OP_DIRTY會將尚未Dirty的頁面狀態設為Dirty,核心會繼續執行遭封鎖的寫入作業。ZX_PAGER_OP_FAIL不會改變頁面的目前狀態,且會導致zx_vmo_write()呼叫端 (寫入作業的來源) 失敗,並為 VM 對應產生嚴重頁面錯誤例外狀況。如果是zx_stream_write(),則會成功傳回,但只寫入部分資料。
// |pager| is the pager handle.
// |pager_vmo| is the VMO handle.
// |offset| and |length| specify the range, i.e. [|offset|, |offset| + |length|).
//
// |op| can be:
//
// ZX_PAGER_OP_DIRTY - The userspace pager wants to transition pages in the range
// [offset, offset + length) from clean to dirty. This will unblock any writes that
// were waiting on ZX_PAGER_VMO_DIRTY page requests for the specified range.
// |data| must be 0.
//
// ZX_PAGER_OP_FAIL - The userspace pager failed to fulfill page requests for
// |pager_vmo| in the range [offset, offset + length) with command
// ZX_PAGER_VMO_READ or ZX_PAGER_VMO_DIRTY.
//
// |data| contains the error encountered, a zx_status_t error code sign-extended
// to a |uint64_t| value - permitted values are ZX_ERR_IO, ZX_ERR_IO_DATA_INTEGRITY,
// ZX_ERR_BAD_STATE and ZX_ERR_NO_SPACE.
zx_status_t zx_pager_op_range(zx_handle_t pager,
uint32_t op,
zx_handle_t pager_vmo,
uint64_t offset,
uint64_t length,
uint64_t data);
視檔案系統排清品質不佳的資料 (dirty data)和標記網頁的頻率而定,當用戶端寫入網頁時,這種做法可能會產生大量效能成本。Clean為避免這項費用,檔案系統可能會盡可能延遲排清品質不佳的資料,但這並非良好的誘因,因為髒頁面無法清除,會造成記憶體壓力,且排清間隔越長,資料遺失的可能性也越高。第 2 版提案嘗試減少部分用戶端寫入作業的效能成本。
ZX_VMO_TRAP_DIRTY v2
系統會新增 zx_pager_set_dirty_pages_limit() 系統呼叫,指定核心可累積的髒頁數量。這裡的預期情況是,檔案系統已預先為這麼多髒頁保留空間。這是每個分頁的限制,預設為零。
使用 zx_pager_set_dirty_pages_limit() 可將限制設為非零值 (視需要多次設定)。v1 設計基本上會將這項限制設為零。
zx_status_t zx_pager_set_dirty_pages_limit(zx_handle_t pager_handle,
uint64_t num_dirty_pages);
核心會追蹤每個分頁器中的髒頁數 (稍後會詳細說明符合追蹤資格的頁面類型),並在轉換至 Dirty 時遞增計數,在轉換至 Clean 時遞減計數。核心仍會像 v1 一樣擷取每個 Dirty 轉換,但如果不會超出分配的 Dirty 限制,核心只會遞增未處理的 Dirty 頁面數量。如果新計數未超過限制,核心會繼續寫入,不會涉及使用者分頁程式。這應該是正常運作模式,因此每次網頁變髒時,都會節省往返使用者分頁的成本。
採用這種做法時,使用者分頁需要向核心傳達兩件事:
- 整個分頁的髒污限制
- 網頁變髒時,會計入該限制的網頁
對於 2),我們再次依賴 ZX_VMO_TRAP_DIRTY VMO 建立旗標。這個標記現在會觸發產生新類型的呼叫器要求:ZX_VMO_DIRTY_MODE。現在,當核心擷取寫入內容時,會查詢檔案系統,判斷是否應將這些頁面計入髒頁限制。使用者分頁器會以 zx_pager_op_range 回應,並提供兩種新的作業類型。
ZX_PAGER_OP_DIRTY_MODE_POOLED會告知核心,範圍內的頁面將計入每個頁面的髒頁限制。這項功能適用於以 CoW 模式運作的檔案,以及以覆寫模式運作的檔案稀疏區域。ZX_PAGER_OP_DIRTY_MODE_UNPOOLED會告知核心,範圍內的頁面不會計入髒頁限制。這適用於以覆寫模式運作的稀疏檔案非稀疏區域。
標示為 ZX_PAGER_OP_DIRTY_MODE_POOLED 的頁面會轉換為 Dirty,且未處理的頁面髒亂計數會遞增 (前提是不超過頁面髒亂限制)。不過,如果弄髒頁面會超過分頁器髒污限制,核心就會開始產生 ZX_PAGER_VMO_DIRTY 封包,也就是 v1 中所述的預設模式。您可以提供選用旗標,在頁面寫回 (轉換為 Clean) 時設定髒模式,這樣就能節省擷取未來寫入內容的成本,進而產生 ZX_VMO_DIRTY_MODE 頁面要求。
這種設計可提供彈性模型,讓檔案系統在 VMO 上混合使用不同類型的寫入模式。以 CoW 模式寫入的檔案會使用 ZX_VMO_TRAP_DIRTY 建立 VMO,且頁面可使用 Pooled 模式。同樣地,您可以使用 ZX_VMO_TRAP_DIRTY 標記在「覆寫」模式中建立稀疏檔案,並分別針對稀疏和非稀疏區域使用「集區」和「非集區」模式。一律使用覆寫模式的檔案可以完全省略 ZX_VMO_TRAP_DIRTY 標記,且永遠不必支付寫入作業的呼叫器要求費用。
使用者分頁在超出髒配額時開始接收 ZX_PAGER_VMO_DIRTY 要求後,預期會開始清除頁面,以便為新的髒頁面建立空間。完成 zx_pager_set_dirty_pages_limit() 後,系統會發出信號,並使用與先前相同的限制或新的限制。完成這項呼叫後,核心會在日後的寫入作業中,繼續根據髒污限制檢查累積的髒污計數,並只在再次達到髒污限制時產生 ZX_PAGER_VMO_DIRTY 要求。
ZX_VMO_TRAP_DIRTY v1 和 v2 之間的差異
第 1 版和第 2 版的主要差異在於負責追蹤預訂次數的實體。在第 1 版中,檔案系統負責追蹤預留空間,核心則會通知檔案系統何時以及要增加多少預留空間計數。由於負責攔截預留項目潛在變更的實體 (核心) 與實際執行記帳作業的實體 (檔案系統) 不同,因此兩者之間必須緊密耦合。在第 2 版中,我們嘗試放寬這項限制,讓核心本身追蹤預訂計數。因此,只有在下列情況下,才需要與檔案系統通訊:1) 需要設定 VMO 範圍,選擇加入 (或退出) 核心預留追蹤功能;2) 核心用盡預留配額,檔案系統需要介入。
我們預期 2) 會是這裡的極端情況,因為檔案系統會定期將髒頁面排清至磁碟。大多數的通訊預計都是因為 1) 而產生。核心可以多次要求相同範圍的資訊 (例如,用於跨越重疊範圍的寫入作業),同樣地,檔案系統也可以多次向核心提供相同範圍的冗餘資訊。在網頁上設定髒模式不會實際耗用髒限制,因為只有在網頁實際寫入時,髒計數才會遞增。因此,檔案系統也可以推測性地在頁面上設定髒模式,以減少日後分頁器要求的效能成本 (但須注意,頁面逐出可能會介入)。
探索髒範圍
使用者分頁需要某種機制,才能找出 VMO 中的髒頁,以便將這些頁面寫回。這裡有兩種不同的模型可供考量:使用者分頁程式從核心查詢髒頁面資訊時的提取模型,以及核心傳送使用者分頁程式回寫要求來指出髒頁面時的推送模型。初始設計會先採用較簡單的提取模型,並導入可能如下所示的髒範圍查詢系統呼叫:
// |pager| is the pager handle.
// |pager_vmo| is the vmo handle.
// |offset| and |length| specify the VMO range to query dirty pages within.
// Must be page-aligned.
//
// |buffer| points to an array of type |zx_vmo_dirty_range_t| defined as follows.
// typedef struct zx_vmo_dirty_range {
// // Represents the range [offset, offset + length).
// uint64_t offset;
// uint64_t length;
// // Any options applicable to the range.
// // ZX_VMO_DIRTY_RANGE_IS_ZERO indicates that the range contains all zeros.
// uint64_t options;
// } zx_vmo_dirty_range_t;
//
// |buffer_size| is the size of |buffer|.
//
// |actual| is an optional pointer to return the number of dirty ranges that were
// written to |buffer|.
//
// |avail| is an optional pointer to return the number of dirty ranges that are
// available to read. If |buffer| is insufficiently large, |avail| will be larger
// than |actual|.
//
// Upon success, |actual| will contain the number of dirty ranges that were copied
// out to |buffer|. The number of dirty ranges that are copied out to |buffer| is
// constrained by |buffer_size|, i.e. it is possible for there to exist more dirty
// ranges in [offset, offset + length) that could not be accommodated in |buffer|.
// The caller can assume than any range that had been made dirty prior to
// making the call will either be contained in |buffer|, or will have a start
// offset strictly greater than the last range in |buffer|. Therefore, the caller
// can advance |offset| and make another query to discover further dirty ranges,
// until |avail| is zero.
//
zx_status_t zx_pager_query_dirty_ranges(zx_handle_t pager,
zx_handle_t pager_vmo,
uint64_t offset,
uint64_t length,
void* buffer,
size_t buffer_size,
size_t* actual,
size_t* avail);
使用者分頁器預期會多次叫用這項查詢,並推進查詢的位移,直到處理完所有髒頁面為止。
使用提取模型時,清除頁面的速率完全取決於檔案系統選擇查詢髒範圍並嘗試回寫的速率。不過,在某些情況下,核心本身需要啟動要求,將頁面寫回,例如在記憶體壓力下,以便清除髒頁面,隨後釋放。在這種情況下,核心可能會依 LRU 順序傳送髒頁面的回寫要求。這是要向使用者分頁程式提供提示,以便提高頁面排清速率,例如以延遲方式處理要求時。
VMO 中髒範圍 [start, end) 的回寫要求可能如下所示。
zx_packet_page_request_t request {
.command = ZX_PAGER_VMO_WRITEBACK,
.flags = ZX_PAGER_MEMORY_PRESSURE,
// |offset| and |length| will be page-aligned.
.offset = start,
.length = end - start,
};
寫回髒範圍
zx_pager_op_range() 系統呼叫會擴充為支援兩個額外的作業,ZX_PAGER_OP_WRITEBACK_BEGIN 和 ZX_PAGER_OP_WRITEBACK_END,分別用來發出信號,指出使用者分頁開始排清頁面,以及排清完成。
ZX_PAGER_OP_WRITEBACK_BEGIN會將指定範圍內所有Dirty頁面的狀態變更為AwaitingClean。如果網頁已處於AwaitingClean或Clean狀態,系統會忽略這項要求,且網頁狀態不會變更。ZX_PAGER_OP_WRITEBACK_END會將指定範圍內所有AwaitingClean頁面的狀態變更為Clean。如果網頁已是Clean或Dirty,系統會忽略這項要求,且網頁狀態不會變更。
如果在執行清除作業時發生任何錯誤 (即 ZX_PAGER_OP_WRITEBACK_BEGIN 之後但 ZX_PAGER_OP_WRITEBACK_END 之前),使用者分頁程式不需要執行任何其他動作。假設沒有其他寫入作業,這些頁面在核心中仍會處於 AwaitingClean 狀態。當核心再次查詢髒頁面時,會一併納入 AwaitingClean 頁面和 Dirty 頁面,使用者分頁器隨後可再次嘗試對這些失敗的頁面執行回寫作業。
// Supported |op| values are:
// ZX_PAGER_OP_WRITEBACK_BEGIN indicates that the user pager is about to
// begin writing back the specified range and the pages are marked |AwaitingClean|.
// ZX_PAGER_OP_WRITEBACK_END indicates that that user pager is done writing
// back the specified range and the pages are marked |Clean|.
//
// |pager| is the pager handle.
// |pager_vmo| is the VMO handle.
// |offset| and |length| specify the range to apply the |op| to, i.e. [|offset|,
// |offset| + |length|).
// For ZX_PAGER_OP_WRITEBACK_*, |data| is unused and should be 0.
zx_status_t zx_pager_op_range(zx_handle_t pager,
uint32_t op,
zx_handle_t pager_vmo,
uint64_t offset,
uint64_t length,
uint64_t data);
對於 ZX_PAGER_OP_WRITEBACK_BEGIN,data 可以選擇性地設為 ZX_VMO_DIRTY_RANGE_IS_ZERO,表示呼叫端想將指定範圍寫回為零。當呼叫端處理 zx_pager_query_dirty_ranges() 傳回的範圍,且 options 設為 ZX_VMO_DIRTY_RANGE_IS_ZERO 時,應使用這個方法。這可確保在查詢後但開始回寫前,範圍內建立的任何非零內容不會因錯誤假設仍為零而遺失,並標示為乾淨 (因此可逐出)。
調整 VMO 大小
Pager 支援的 VMO 與匿名 (非 pager 支援) VMO 的不同之處,在於處理 VMO 中沒有內容的方式。匿名 VMO 的隱含初始內容為零,因此未提交的頁面表示零。但這不適用於以分頁備份的 VMO,因為未提交的頁面不代表零,只是表示分頁器尚未提供這些頁面的內容。不過,如果調整為較大的大小,分頁器無法在新的擴充範圍中提供頁面,因為備份來源 (例如儲存磁碟) 上還沒有這類內容,因此沒有可分頁的內容。核心可以在這個新擴充範圍中提供頁面做為零,不必諮詢使用者分頁程式。
系統會追蹤跨越新調整大小範圍的零間隔,藉此處理大小調整作業,而核心會隱含地提供零頁面。使用者分頁器尚未察覺這個零間隔,因此當使用者分頁器查詢髒範圍時,這個範圍會回報為髒範圍。此外,這個範圍的 zx_vmo_dirty_range_t 中的選項欄位會設為 ZX_VMO_DIRTY_RANGE_IS_ZERO,表示全為零。
如果 VMO 是以 ZX_VMO_TRAP_DIRTY 標記建立,且頁面寫入這個新擴充的範圍,核心會在提交頁面之前,為這些頁面產生 ZX_PAGER_VMO_DIRTY 分頁要求。這是因為檔案系統可能需要為實際 (非零) 頁面保留空間。這個模型假設檔案系統可將零有效表示為磁碟上的稀疏區域,因此只有在新的擴充範圍中提交頁面時,才會查詢檔案系統。
從呼叫器卸離 VMO
A zx_pager_detach_vmo() 會將 ZX_PAGER_COMPLETE 封包排入佇列,表示使用者呼叫器日後不應再對該 VMO 提出呼叫器要求。這也表示使用者分頁程式應查詢並寫回任何未處理的髒頁面。請注意,在髒頁面寫回之前,分離作業不會遭到封鎖;這項作業只會通知使用者分頁器可能需要排清。
卸離後,原本需要產生呼叫器要求的 zx_vmo_read() / zx_vmo_write() 會因 ZX_ERR_BAD_STATE 而失敗。透過對應讀取及寫入,這類對應同樣會要求呼叫分頁程式,產生嚴重的分頁錯誤例外狀況。核心可自由捨棄 VMO 中的乾淨頁面。不過,核心會保留髒頁面,直到使用者分頁程式清理完畢為止。也就是說,即使 VMO 已分離,系統仍會繼續支援 ZX_PAGER_OP_WRITEBACK_BEGIN 和 ZX_PAGER_OP_WRITEBACK_END。zx_pager_op_range() 對所有其他作業和zx_pager_supply_pages()失敗,並在已卸離的 VMO 上發生 ZX_ERR_BAD_STATE。
如果分頁器在相關聯的 VMO 中有髒頁面時遭到刪除,核心可以隨時移除這些頁面,無論是否有任何待處理的回寫要求。換句話說,只要有分頁器可清除髒頁面,髒頁面就一定會保留在記憶體中。
查詢呼叫器 VMO 統計資料
核心也會追蹤 VMO 是否經過修改,使用者分頁程式可以查詢這項資訊。使用者分頁程式會使用這項功能追蹤 mtime。
// |pager| is the pager handle.
// |pager_vmo| is the VMO handle.
// |options| can be ZX_PAGER_RESET_VMO_STATS to reset the queried stats.
// |buffer| points to a struct of type |zx_pager_vmo_stats_t|.
// |buffer_size| is the size of the buffer and should be large enough to
// accommodate |zx_pager_vmo_stats_t|.
//
// typedef struct zx_pager_vmo_stats {
// uint32_t modified;
// } zx_pager_vmo_stats_t;
zx_status_t zx_pager_query_vmo_stats(zx_handle_t pager,
zx_handle_t pager_vmo,
uint32_t options,
void* buffer,
size_t buffer_size);
如果 VMO 經過修改,傳回的 zx_pager_vmo_stats_t 的 modified 欄位會設為 ZX_PAGER_VMO_STATS_MODIFIED,否則會設為 0。未來可能會擴充 zx_pager_vmo_stats_t 結構,加入更多使用者分頁可能實用的查詢欄位。
系統會在修改 VMO 的系統呼叫 (例如 zx_vmo_write() 和 zx_vmo_set_size()) 中更新 modified 狀態,也會在寫入頁面錯誤首次透過對應傳送時更新。系統會追蹤頁面上的第一個寫入錯誤,以便正確管理 Clean 至 Dirty 的轉換,因此 modified 狀態會在當時更新。不過,系統不會追蹤透過髒頁面上的對應檔傳入的後續寫入作業,否則會大幅降低寫入對應 VMO 的速度。因此,對應的 VMO modified 狀態可能不完全準確。
options,如果使用者分頁也想重設查詢的統計資料,則可以為 ZX_PAGER_RESET_VMO_STATS。options 值為 0 不會重設任何狀態,且會執行純查詢。請注意,如果指定 ZX_PAGER_RESET_VMO_STATS 選項,這個呼叫可能會消耗可查詢的狀態,進而影響日後的 zx_pager_query_vmo_stats() 呼叫。舉例來說,如果 zx_vmo_write() 後面有兩個連續的 zx_pager_query_vmo_stats() 呼叫 (使用 ZX_PAGER_RESET_VMO_STATS 選項),只有第一個呼叫會看到 modified 設為 由於第一個 zx_pager_query_vmo_stats() 之後沒有任何修改,第二個 zx_pager_query_vmo_stats() 會將 modified 傳回為 0。
實作
Pager 回寫功能已開發一段時間,所有新 API 片段都可在 @next vDSO 中使用。fxfs 已採用回寫 API,支援串流讀取/寫入和 mmap。
效能
透過分頁回寫,fxfs 能夠從透過管道執行 I/O 切換為使用串流,進而使各種基準的效能提升約 40 至 60 倍。
安全性考量
無。
隱私權注意事項
無。
測試
我們已編寫核心測試和壓力測試,以執行分頁程式系統呼叫。此外,還有儲存空間測試和效能基準。
說明文件
核心系統呼叫說明文件已更新。
缺點、替代方案和未知事項
限制回寫要求頻率
在未來的疊代中,當核心產生回寫要求時 (在記憶體壓力下或以穩定的背景速率),我們需要某種政策來控管在分頁器埠排隊的回寫要求數量。其中一個選項是讓核心追蹤待處理的要求數量,並盡量將數量維持在特定限制內。
另一種做法是讓使用者分頁器設定可調整的項目,直接或間接決定回寫要求產生率。舉例來說,使用者分頁器可以指定網頁在排入回寫佇列前可保持髒狀態的建議時間長度,或是使用者分頁器可支援的寫入資料移轉率。有些檔案系統可能需要比全域系統預設值高得多的背景回寫率。使用者分頁器也可以指定處理要求的精細度 (系統頁面大小的倍數)。核心在計算範圍時,可能會將這項資訊納入考量,進而減少整體要求。
追蹤及查詢網頁年齡資訊
在初始實作中,核心會在頁面佇列中追蹤髒頁面,並依頁面首次變髒的時間排序。這個佇列可用於在日後產生回寫要求,且網頁清理完畢後,即可從髒佇列移至 (乾淨) 分頁器支援的佇列,目前這些佇列會追蹤唯讀網頁並記錄其存留時間。我們可能也想更精細地追蹤髒頁面的年齡;將髒頁面和乾淨頁面統一到共用集區,以利用老化和存取位元追蹤 w.r.t. 全域工作集,可能是有意義的做法。我們可能也會想透過新的 API,向使用者分頁器公開這項年齡資訊,以便在處理回寫要求時納入考量。
在回寫期間封鎖後續寫入作業
這裡提出的設計不會封鎖寫回作業進行期間 (即 ZX_PAGER_OP_WRITEBACK_BEGIN 和 ZX_PAGER_OP_WRITEBACK_END 之間) 的新寫入作業。而是會再次標示為髒頁。或許某些檔案系統會在頁面處於 AwaitingClean 狀態時,封鎖寫入作業。我們可能會在日後新增 ZX_PAGER_OP_WRITEBACK_BEING_SYNC,在回寫期間封鎖寫入作業。請注意,ZX_VMO_TRAP_DIRTY 第 1 版提供解決這個問題的方法,也就是 ZX_PAGER_VMO_DIRTY 分頁器要求,檔案系統可以在排清作業進行期間暫緩處理。