
本文档介绍了用于收集、存储和传输 Fuchsia 轨迹记录的二进制格式。您可以使用本文档搜索有关 Fuchsia 跟踪格式中每个字段的详细信息。
概览
在跟踪运行期间,跟踪提供程序会使用本文档中描述的二进制格式将记录写入与跟踪管理器共享的跟踪缓冲区 VMO 中。
二进制格式旨在最大限度地减少在写入轨迹时对被跟踪对象性能的影响。记录也是按顺序写入的,因此如果轨迹终止(正常或异常),轨迹管理器仍可通过读取最后一个格式正确的记录之前的所有内容来恢复已存储在轨迹缓冲区中的部分轨迹数据。
随着跟踪的进行,跟踪管理器会汇总参与跟踪收集的所有跟踪提供程序的记录,并将它们与一些特殊的元数据记录串联在一起,以形成跟踪归档。
轨迹完成后,trace 命令行程序等工具可以读取轨迹归档中的轨迹记录,以直观呈现结果或将其保存到文件中供日后使用。您还可以使用 Perfetto 界面直观呈现跟踪记录归档。
功能
- 占用空间小
- 轨迹记录非常紧凑,可将信息打包到少量位中。
- 对字符串、进程和线程进行池化可进一步压缩轨迹数据。
- 内存对齐
- 轨迹记录在内存中保持 8 字节对齐,以便直接将它们写入内存映射的 VMO。
- 大小可变的记录
- 记录总大小不得超过 32 KB。
- 大型对象可能需要拆分为多条记录。
- 可扩展
- 您可以根据需要定义新的记录类型。
- 系统可以跳过无法识别或格式错误的轨迹记录。
编码基元
Fuchsia 轨迹格式具有以下编码原语:
Atoms
每条记录都构建为原子序列。
每个原子都以 8 字节对齐方式写入,并且大小也是 8 字节的倍数,以便保持对齐。
原子有两种类型:
- 字:一个 64 位的值,可以进一步细分为位字段。 字词以机器字顺序存储(在所有当前支持的架构上均为小端字节序)。
- Stream:一个字节序列,用零填充到下一个 8 字节边界。流以字节顺序存储。长度正好是 8 字节的倍数的流不会进行填充(没有零终止符)。
字段是 64 位字的细分,表示为 [<least significant bit> .. <most significant bit>],其中第一个和最后一个位位置是包含在内的。所有未使用的位均预留以供日后使用,且必须设置为 0。
除非记录格式另有规定,否则字和字段存储的是无符号整数。
流可以存储 UTF-8 字符串或二进制数据,具体取决于记录格式。
记录
轨迹记录是一段二进制编码的轨迹信息,由一系列原子组成。
所有记录都包含一个标题字,其中包含以下基本信息:
- 记录类型:一个 4 位字段,用于标识记录的类型及其包含的信息。请参阅记录类型。
- 记录大小:通常是一个 12 位字段,用于指示记录中的字数(8 字节单位的倍数),包括记录头本身。记录的最大可能大小为 4095 个字(32760 字节)。非常简单的记录可能只有 1 个字(8 字节)长。 大型记录使用 32 位大小字段,因此最大大小更大。
记录的长度始终为 8 字节的倍数,并且以 8 字节对齐方式存储。
存档
轨迹归档是一系列轨迹记录,这些记录首尾相连,用于存储轨迹提供程序在轨迹运行期间收集的信息,以及用于标识和分隔每个轨迹提供程序生成的轨迹部分的元数据记录。
跟踪归档旨在按顺序读取,因为跟踪中较早出现的记录可能会影响对跟踪中较晚出现的记录的解读。会影响归档中后续记录的记录示例包括字符串引用和线程引用。
具有关联时间戳的事件记录不一定按时间戳顺序排列。某些记录类型(例如流程事件)需要按时间戳顺序处理事件,因此处理轨迹数据的程序应先按时间戳对事件进行排序,然后再进行处理。
轨迹系统提供了一些工具,用于从轨迹归档中提取信息并将其转换为其他形式以进行可视化。
时间戳
时间戳表示为从硬件计数器派生的 64 位时钟周期。 轨迹初始化记录描述了每秒的实际时间节拍数。
默认情况下,我们假设 1 个 tick 等于 1 纳秒。
字符串引用
字符串编码为字符串引用,即以下形式的 16 位值:
- 空字符串:值为零。
- 索引字符串:最高有效位为零。低 15 位表示之前使用 String 记录分配的字符串表中的索引。
- 内嵌字符串:最高有效位为 1。低 15 位表示字符串的长度(以字节为单位)。字符串的内容会以内嵌方式显示在记录的另一部分中,具体取决于记录格式。
为了使轨迹更紧凑,应使用字符串记录将经常引用的字符串(例如事件类别和名称常量)注册到字符串表中,然后通过索引引用。
字符串表中最多可以有 32767 个字符串。如果达到此限制,则可以通过替换现有条目或内嵌编码字符串来编码其他字符串。
字符串内容本身以不带终止符的 UTF-8 流形式存储。
字符串的理论最大长度为 32767 字节,但实际上,存储包含该字符串的其余记录所需的空间会进一步减少这一长度,因此我们将保守的最大字符串长度限制设置为 32000 字节。
Thread 参考
线程和进程内核对象 ID (koid) 编码为线程引用,后者是以下形式的 8 位值:
- 内嵌线程:值为零。线程和进程 koid 会以内嵌方式显示在记录的另一部分中,具体取决于记录格式。
- 已编入索引的线程数:值不为零。该值表示之前使用线程记录分配的线程表中的索引。
为了使轨迹更紧凑,应使用线程记录将经常引用的线程注册到线程表中,然后通过索引引用。
字符串表中最多可以有 255 个线程。如果达到此限制,则可以通过替换现有条目或内嵌编码线程来编码其他线程。
用户空间对象信息
轨迹可以包含有关用户空间对象(可以使用类似指针的值(例如 C++ 或 Dart 对象)引用的任何内容)的注释,这些注释以用户空间对象记录的形式呈现。轨迹提供程序通常会在创建对象时生成此类记录。
此后,引用同一指针的任何指针实参都将与被引用对象的注释相关联。
这样一来,您就可以轻松地将人类可读的标签和其他信息与稍后出现在轨迹中的对象相关联。
内核对象信息
轨迹可以包含有关内核对象(可以使用 Zircon koid 引用的任何内容,例如进程、渠道或事件)的注释,这些注释以内核对象记录的形式呈现。跟踪提供程序通常会在创建对象时生成此类记录。
此后,任何引用同一 koid 的内核对象 ID 实参都将与被引用者的注释相关联。
这样一来,您就可以轻松地将人类可读的标签和其他信息与稍后出现在轨迹中的对象相关联。
具体来说,跟踪系统就是通过这种方式将名称与进程和线程 koid 相关联的。
参数
实参是带类型的键值对。
许多记录类型允许在记录中附加最多 15 个实参,以提供来自开发者的其他信息。
实参会像普通记录一样添加大小前缀,以便跳过无法识别的实参类型。
如需了解详情,请参阅实参类型。
扩展格式
可以通过以下方式扩展轨迹格式:
- 定义新的记录类型。
- 在现有记录类型的预留字段中存储新信息。
- 将新信息附加到现有记录类型(通过检查记录的大小和载荷可以检测到是否存在此信息)。
- 定义新的实参类型。
记录类型
记录类型如下:
- 记录标题
- 大型记录标头
- 元数据记录(记录类型 = 0)
- 初始化记录(记录类型 = 1)
- 字符串记录(记录类型 = 2)
- 线程记录(记录类型 = 3)
- 活动记录(记录类型 = 4)
- Blob 记录(记录类型 = 5)
- 用户空间对象记录(记录类型 = 6)
- 内核对象记录(记录类型 = 7)
- 调度记录(记录类型 = 8)
- 日志记录(记录类型 = 9)
- 大型 BLOB 记录(记录类型 = 15,大型类型 = 0)
记录标题
所有记录都包含此标头,用于指定记录的类型和大小,以及 48 位数据(其用途因记录类型而异)。
格式

标题字词
[0 .. 3]:记录类型[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 63]:因记录类型而异(如果未使用,则必须为零)
大型记录标题
提供对大于 32KB 的记录的支持。大型记录具有 32 位大小字段,而不是正常的 12 位。
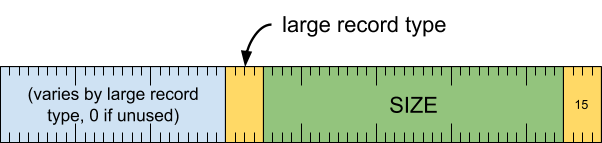
标题字词
[0 .. 3]:记录类型 (15)[4 .. 35]:记录大小(包括此字),以 8 字节的倍数表示[36 .. 39]:大型记录类型[40 .. 63]:因大型记录类型而异(如果未使用,则必须为零)
元数据记录(记录类型 = 0)
提供有关后续跟踪记录数据的元数据。
此记录类型预留供 trace manager 在生成轨迹归档时使用。不得由轨迹提供程序本身发出。 如果轨迹管理器在轨迹提供程序生成的轨迹中遇到元数据记录,则会将其视为垃圾并跳过。
元数据记录有多种子类型,每种子类型都包含不同的信息。
格式
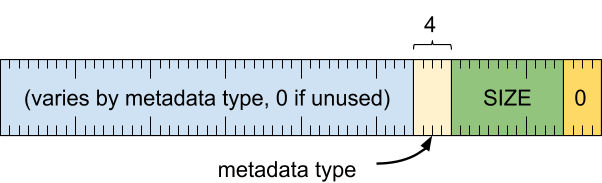
标题字词
[0 .. 3]:记录类型 (0)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:元数据类型[20 .. 63]:因元数据类型而异(如果未使用,则必须为零)
提供商信息元数据(元数据类型 = 1)
此元数据用于标识向轨迹贡献信息的轨迹提供程序。
在遇到下一个提供商部分元数据或提供商信息元数据之前的所有后续数据都必须来自同一提供商。
格式
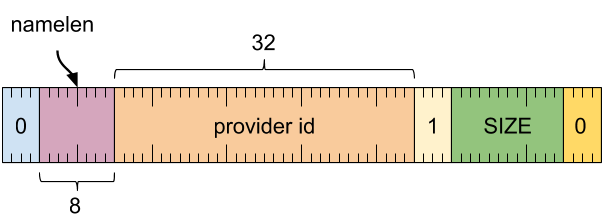
标题字词
[0 .. 3]:记录类型 (0)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:元数据类型 (1)[20 .. 51]:提供方 ID(用于在轨迹中标识提供方的令牌)[52 .. 59]:名称长度(以字节为单位)[60 .. 63]:保留(必须为零)
提供商名称流
- UTF-8 字符串,用零填充到 8 字节对齐
提供方部分元数据(元数据类型 = 2)
此元数据用于分隔从不同提供商处获取的轨迹部分。
在遇到下一个提供方部分元数据或提供方信息元数据之前的所有后续数据均假定为从同一提供方收集。
读取由不同轨迹提供程序累积的轨迹时,读取器必须为每个提供程序的轨迹单独维护状态(例如初始化数据、字符串表、线程表、用户空间对象表和内核对象表),并在遇到新的提供程序部分元数据记录时切换上下文。
格式
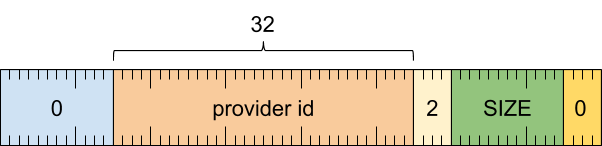
标题字词
[0 .. 3]:记录类型 (0)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:元数据类型 (2)[20 .. 51]:提供方 ID(用于在轨迹中标识提供方的令牌)[52 .. 63]:保留(必须为零)
提供方事件元数据(元数据类型 = 3)
此元数据提供提供方想要报告的事件的正在运行的通知。
此记录可以出现在输出中的任何位置,并且不会限制其之前或之后的内容。
格式
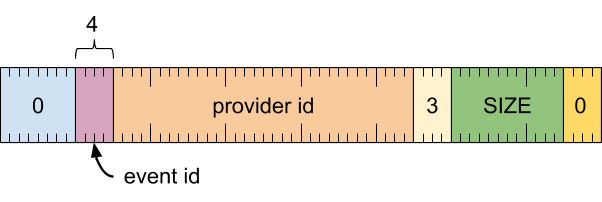
标题字词
[0 .. 3]:记录类型 (0)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:元数据类型 (3)[20 .. 51]:提供方 ID(用于在轨迹中标识提供方的令牌)[52 .. 55]:活动 ID[56 .. 63]:保留(必须为零)
事件
定义了以下事件。
0:缓冲区已满,可能丢弃了记录
轨迹信息元数据(元数据类型 = 4)
此元数据提供有关整个轨迹的信息。此记录未与特定提供商相关联。
格式
标题字词
[0 .. 3]:记录类型 (0)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:元数据类型 (4)[20 .. 23]:轨迹信息类型[24 .. 63]:因跟踪信息类型而异(如果未使用,则必须为零)
魔数记录(轨迹信息类型 = 0)
此记录用于指示二进制数据采用的是 Fuchsia 跟踪格式。通常,它应出现在轨迹的开头。不包含任何其他信息。神奇数字 0x16547846 是字符串“FxT”,后跟一个随机选择的字节。
为了允许将轨迹的前 8 个字节一起视为魔数,而不必关心内部记录结构,此记录类型是不可扩展的。记录不得包含标题字词以外的任何字词,并且没有预留字段。作为 8 字节数字,整个记录的值为 0x0016547846040010。
请注意,相应值以及轨迹中的所有其他字词的字节顺序取决于写入轨迹的系统的字节序。对于小端系统,前 8 个字节为 10 00 04 46 78 54 16 00。在大端字节序系统中,顺序将相反:00 16 54 78 46 04 00 10。
格式
标题字词
[0 .. 3]:记录类型 (0)[4 .. 15]:记录大小(包括此字),以 8 字节为单位 (1)[16 .. 19]:元数据类型 (4)[20 .. 23]:轨迹信息类型 (0)[24 .. 55]:魔数 0x16547846[56 .. 63]:零
初始化记录(记录类型 = 1)
提供了解释后续记录所需的参数。如果没有此记录,读取器可能会假设 1 个时钟周期为 1 纳秒。
格式
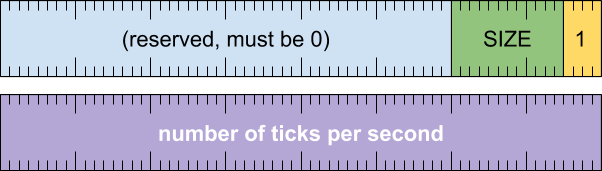
标题字词
[0 .. 3]:记录类型 (1)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 63]:保留(必须为零)
“加倍”字词
[0 .. 63]:每秒的 tick 数
字符串记录(记录类型 = 2)
在字符串表中注册一个字符串,并为其分配一个介于 0x0001 到 0x7fff 之间的字符串索引。在解读后续记录时,注册会替换给定字符串索引的任何先前注册。
尝试为字符串索引 0x0000 设置值的字符串记录必须被忽略,因为此值预留用于表示空字符串。
必须容忍包含空字符串的字符串记录,但这些记录毫无意义,因为空字符串可以简单地编码为字符串引用中的零。
格式
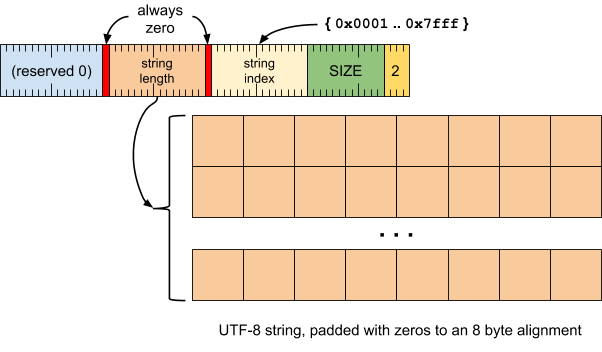
标题字词
[0 .. 3]:记录类型 (2)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 30]:字符串索引(范围为 0x0001 到 0x7fff)[31]:始终为零 (0)[32 .. 46]:字符串长度(以字节为单位)(范围为 0x0000 到 0x7fff)[47]:始终为零 (0)[48 .. 63]:保留(必须为零)
字符串值流
- UTF-8 字符串,用零填充到 8 字节对齐
线程记录(记录类型 = 3)
在线程表中注册进程 ID 和线程 ID 对,并为其分配一个介于 0x01 到 0xff 之间的线程索引。在解读后续记录时,该注册会替换给定线程索引的任何先前注册。
线程索引 0x00 保留用于表示线程引用中使用了内联线程 ID。必须忽略尝试为此值设置值的线程记录。
格式

标题字词
[0 .. 3]:记录类型 (3)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 23]:线程索引(永远不为 0x00)[24 .. 63]:保留(必须为零)
进程 ID 字词
[0 .. 63]:进程 koid(内核对象 ID)
线程 ID 字词
[0 .. 63]:线程 koid(内核对象 ID)
活动记录(记录类型 = 4)
描述带时间戳的事件。
此记录包含有关事件的一些基本信息,包括事件发生的时间和地点,后跟事件实参和事件子类型特定数据。
格式
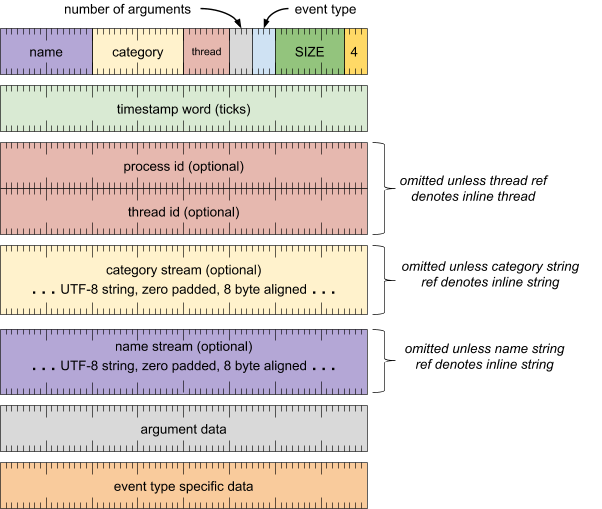
标题字词
[0 .. 3]:记录类型 (4)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:活动类型[20 .. 23]:实参数量[24 .. 31]:线程(线程引用)[32 .. 47]:类别(字符串引用)[48 .. 63]:名称(字符串引用)
时间戳字词
[0 .. 63]:计时周期数
进程 ID 字词(除非线程引用表示内嵌线程,否则会省略)
[0 .. 63]:进程 koid(内核对象 ID)
线程 ID 字词(除非线程引用表示内嵌线程,否则会省略)
[0 .. 63]:线程 koid(内核对象 ID)
类别流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参数据(针对每个实参重复)
- (请参见下文)
特定于事件类型的数据
- 可以是以下任意一项:
即时活动(活动类型 = 0)
标记相应消息串中的某个时间点。这些等效于 Zircon 内核探测。
格式
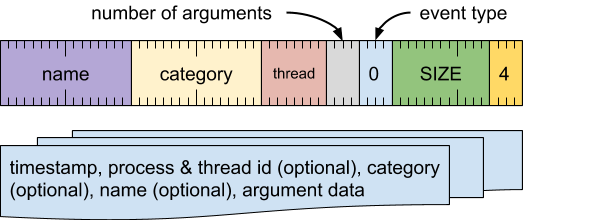
无需提供事件类型特定数据。
计数器事件(事件类型 = 1)
将每个实参的样本值记录为与计数器的名称和 ID 相关联的时间序列中的数据。这些值可以图形化地呈现为堆叠面积图。
格式
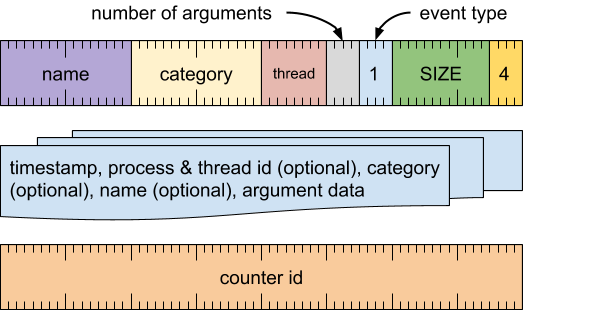
量词
[0 .. 63]:计数器 ID
时长开始事件(事件类型 = 2)
标记特定线程上操作的开始。必须与时长结束事件相匹配。可以嵌套。
格式
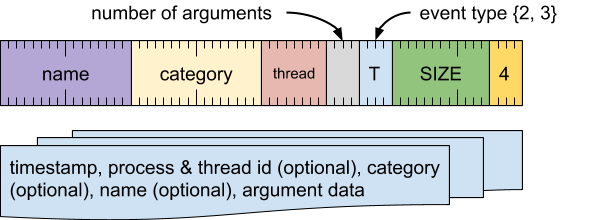
无需提供事件类型特定数据。
时长结束事件(事件类型 = 3)
标记特定线程上操作的结束。
格式
无需提供事件类型特定数据。
时长完成事件(事件类型 = 4)
标记特定线程上操作的开始和结束。
格式
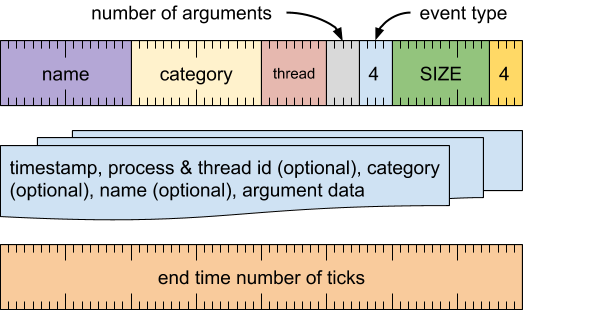
结束时间字词
[0 .. 63]:结束时间(以 tick 为单位)
异步开始事件(事件类型 = 5)
标记可能跨线程的操作的开始。必须通过使用相同异步相关 ID 的异步结束事件进行匹配。
格式
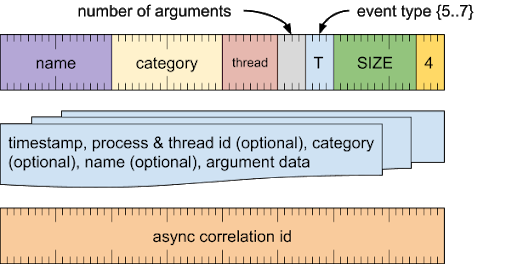
异步相关字词
[0 .. 63]:异步相关 ID
异步即时事件(事件类型 = 6)
标记可能跨线程的操作中的某个时刻。必须使用相同的异步相关 ID 出现在异步开始事件和异步结束事件之间。
格式
异步相关字词
[0 .. 63]:异步相关 ID
异步结束事件(事件类型 = 7)
标记可能跨线程的操作的结束。
格式
异步相关字词
[0 .. 63]:异步相关 ID
流程开始事件(事件类型 = 8)
标记操作的开始,该操作会产生一系列可能跨多个线程或抽象层的操作。必须通过使用相同流程相关 ID 的流程结束事件进行匹配。这可以看作是时长事件之间的一条箭头。
流程的开始时间与相应线程的封装时长事件相关联;它从封装时长事件的结束时间开始。
格式
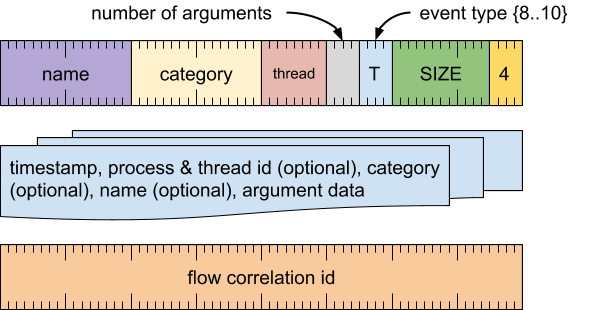
流程相关词
[0 .. 63]:流程关联 ID
流程步骤事件(事件类型 = 9)
标记流程中的某个点。
该步骤与相应线程的封装时长事件相关联;流程会在封装时长事件开始的位置恢复,然后在封装时长事件结束的位置暂停。
格式
流程相关词
[0 .. 63]:流程关联 ID
流程结束事件(事件类型 = 10)
标记流程的结束。
流程的结束与相应线程的封装时长事件相关联;流程会在封装时长事件开始的位置恢复。
格式
流程相关词
[0 .. 63]:流程关联 ID
BLOB 记录(记录类型 = 5)
提供要包含在轨迹中的未解释的批量数据。这对于以其他格式嵌入捕获的轨迹数据非常有用。
Blob 名称可唯一标识轨迹中的各个 Blob 数据流。通过写入多个具有相同名称的 blob 记录,可以将更多数据块附加到之前创建的 BLOB。
BLOB 类型表示 BLOB 内容的表示形式。
格式
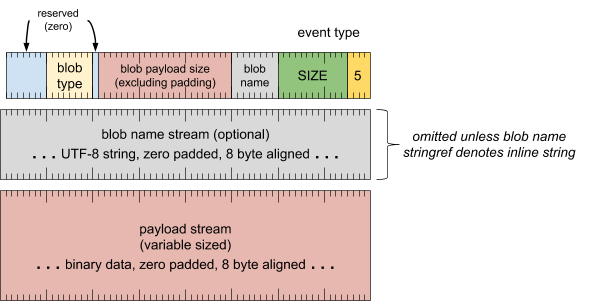
标题字词
[0 .. 3]:记录类型 (5)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 31]:blob 名称(字符串引用)[32 .. 46]:blob 载荷大小(以字节为单位,不包括填充)[47 .. 47]:保留(必须为零)[48 .. 55]:blob 类型[56 .. 63]:保留(必须为零)
blob 名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
载荷流(大小可变)
- 二进制数据,用零填充到 8 字节对齐
Blob 类型
定义了以下 blob 类型:
TRACE_BLOB_TYPE_DATA=0x01:原始的无类型数据。使用方应知道如何使用该结果,或许是根据上下文来确定。TRACE_BLOB_TYPE_LAST_BRANCH=0x02:Intel Performance Monitor 的最后分支记录。 格式由 CPU 性能监控器定义。TRACE_BLOB_TYPE_PERFETTO =0x03:blob 包含从 Perfetto 说话组件记录的数据。数据以 Perfetto 的 Proto 格式进行编码。
用户空间对象记录(记录类型 = 6)
描述用户空间对象,为其分配标签,并可选择性地将键/值数据作为实参与其关联。有关对象的信息会添加到每个进程的用户空间对象表中。
当轨迹消费者遇到具有指针实参(其值与进程的对象表中的条目匹配)的事件时,它可以将实参的指针值与之前的用户空间对象记录进行交叉引用,以查找被引用对象的说明。
格式
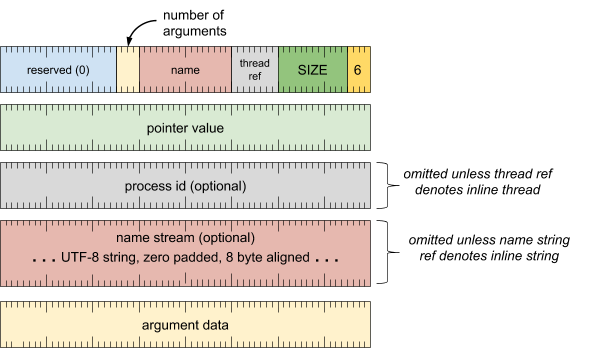
标题字词
[0 .. 3]:记录类型 (6)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 23]:进程(线程引用)[24 .. 39]:名称(字符串引用)[40 .. 43]:实参数量[44 .. 63]:保留(必须为零)
pointer word
[0 .. 63]:指针值
进程 ID 字词(除非线程引用表示内嵌线程,否则会省略)
[0 .. 63]:进程 koid(内核对象 ID)
名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参数据(针对每个实参重复)
- (请参见下文)
内核对象记录(记录类型 = 7)
描述一个内核对象,为其分配标签,并可选择性地将键/值数据作为实参与其关联。有关对象的信息会添加到全局内核对象表中。
当轨迹消费者遇到具有 koid 实参(其值与内核对象表中的条目匹配)的事件时,它可以将该实参的 koid 值与之前的内核对象记录进行交叉引用,以查找被引用对象的说明。
格式
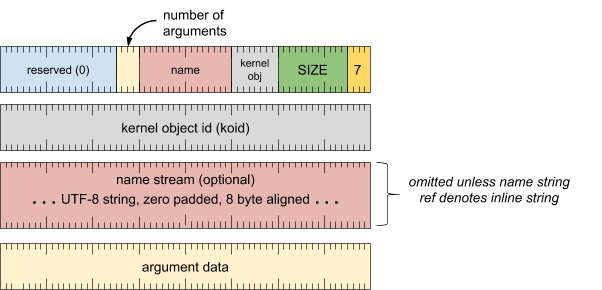
标题字词
[0 .. 3]:记录类型 (7)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 23]:内核对象类型(来自 zircon/syscalls/types.h 的 ZX_OBJ_TYPE_XXX 常量之一)[24 .. 39]:名称(字符串引用)[40 .. 43]:实参数量[44 .. 63]:保留(必须为零)
内核对象 ID 字
[0 .. 63]:koid(内核对象 ID)
名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参数据(针对每个实参重复)
- (请参见下文)
实参惯例
按照惯例,当写入有关特定类型对象的内核对象记录时,轨迹写入器应包含以下命名实参。这有助于跟踪消费者关联内核对象之间的关系。
"process":对于ZX_OBJ_TYPE_THREAD对象,指定包含相应线程的进程的 koid
调度记录(记录类型 = 8)
描述调度事件,例如线程何时被唤醒,或从一个线程到另一个线程的上下文切换。
格式
+---------(4)--------------+--------(48)--------+--(8)--+-(4)-+
| scheduling record type | <type specific> | size | 8 |
+--------------------------+--------------------+-------+-----+
标题字词
[0 .. 3]:记录类型 (8)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 59]:调度记录类型特定数据[60 .. 63]:调度记录类型
上下文切换记录(调度事件记录类型 = 1)
格式
+-(4)-+----(20)---+--------(4)-------+----(16)---+-------(4)-------+----(8)--+-(4)-+
| 1 | reserved | out thread state | cpu | argument count | size | 8 |
+-----+-----------+------------------+-----------+-----------------+---------+-----+
+---------------------------(64)------------------------------+
| timestamp |
+-------------------------------------------------------------+
+---------------------------(64)------------------------------+
| outgoing thread id |
+-------------------------------------------------------------+
+---------------------------(64)------------------------------+
| incoming thread id |
+-------------------------------------------------------------+
+--------------------------(...)------------------------------+
| argument data |
+-------------------------------------------------------------+
标题字词
[0 .. 3]:记录类型 (8)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:实参数量[20 .. 35]:CPU 编号[36 .. 39]:传出线程状态[40 .. 59]:预留[60 .. 63]:调度记录类型 (1)
时间戳字词
[0 .. 63]:计时周期数
传出线程 ID
[0 .. 63]:线程 koid(内核对象 ID)
传入的线程 ID
[0 .. 63]:线程 koid(内核对象 ID)
实参数据(每个实参的重复次数)
- (有关实参格式,请参阅实参)
实参惯例
按照惯例,轨迹写入器还可以在写入此记录时选择性地包含以下命名实参,以向轨迹使用者提供额外信息。
"incoming_weight":Int32,用于描述传入线程的相对权重"outgoing_weight":Int32,用于描述传出线程的相对权重
线程唤醒记录(调度事件记录类型 = 2)
格式
+-(4)-+----(24)---+----(16)---+-------(4)-------+----(8)--+-(4)-+
| 2 | reserved | cpu | argument count | size | 8 |
+-----+-----------+-----------+-----------------+---------+-----+
+---------------------------(64)------------------------------+
| timestamp |
+-------------------------------------------------------------+
+---------------------------(64)------------------------------+
| waking thread id |
+-------------------------------------------------------------+
+--------------------------(...)------------------------------+
| argument data |
+-------------------------------------------------------------+
标题字词
[0 .. 3]:记录类型 (8)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 19]:实参数量。[20 .. 35]:CPU 数量。[60 .. 63]:调度记录类型 (2)
时间戳字词
[0 .. 63]:计时周期数
唤醒线程 ID
[0 .. 63]:线程 koid(内核对象 ID)
实参数据(每个实参的重复次数)
- (有关实参格式,请参阅实参)
实参惯例
按照惯例,轨迹写入器还可以在写入此记录时选择性地包含以下命名实参,以向轨迹使用者提供额外信息。
"weight":Int32,用于描述唤醒线程的相对权重
旧版上下文切换记录(上下文切换记录类型 = 0)
随着 Fuchsia 的调度不断发展,此记录不再是有效的上下文切换模型。保留此属性是为了实现向后兼容性。
该记录指定了上下文切换后传出线程的新状态。根据定义,传入线程的新状态为“正在运行”,因为该线程刚刚恢复。
格式
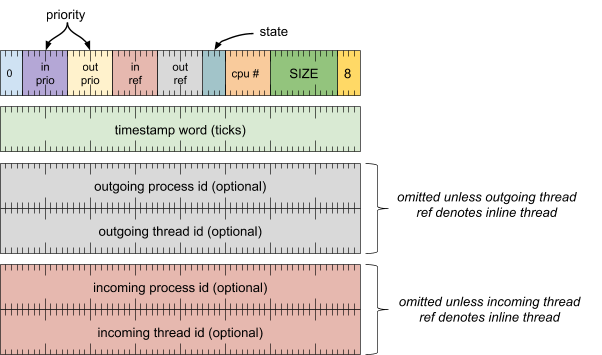
[0 .. 3]:记录类型 (8)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 23]:CPU 编号[24 .. 27]:传出线程状态(以下任何值,但“running”除外)[28 .. 35]:出站线程(线程引用)[36 .. 43]:传入的线程(线程引用)[44 .. 51]:传出线程优先级[52 .. 59]:传入线程优先级[60 .. 63]:调度记录类型 (0)
时间戳字词
[0 .. 63]:计时周期数
传出进程 ID 字词(除非传出线程引用表示内嵌线程,否则会省略)
[0 .. 63]:进程 koid(内核对象 ID)
传出消息的线程 ID 字词(除非传出消息的线程引用表示内嵌线程,否则会省略)
[0 .. 63]:线程 koid(内核对象 ID)
传入进程 ID 字词(除非传入线程引用表示内嵌线程,否则会省略)
[0 .. 63]:进程 koid(内核对象 ID)
传入的线程 ID 字词(除非传入的线程引用表示内嵌线程,否则会省略)
[0 .. 63]:线程 koid(内核对象 ID)
线程状态
定义了以下线程状态:
0:新1:跑步2:已暂停3:已屏蔽4:正在终止5:失效
这些值与 zircon/syscalls/object.h 中的 ZX_THREAD_STATE_XXX 常量保持一致。
日志记录(记录类型 = 9)
描述在特定时间点写入日志的消息。
格式
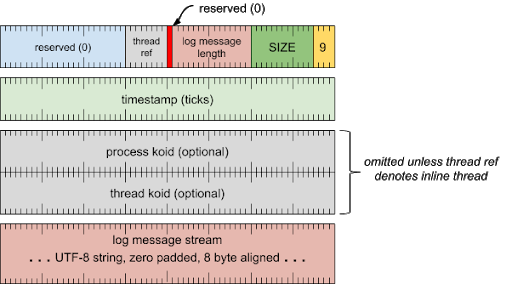
标题字词
[0 .. 3]:记录类型 (9)[4 .. 15]:记录大小(包括此字),以 8 字节的倍数表示[16 .. 30]:日志消息长度(以字节为单位)(范围为 0x0000 到 0x7fff)[31]:始终为零 (0)[32 .. 39]:线程(线程引用)[40 .. 63]:保留(必须为零)
时间戳字词
[0 .. 63]:计时周期数
进程 ID 字词(除非线程引用表示内嵌线程,否则会省略)
[0 .. 63]:进程 koid(内核对象 ID)
线程 ID 字词(除非线程引用表示内嵌线程,否则会省略)
[0 .. 63]:线程 koid(内核对象 ID)
日志消息流
- UTF-8 字符串,用零填充到 8 字节对齐
大型 BLOB 记录(记录类型 = 15,大型类型 = 0)
提供要嵌入到轨迹中的大型二进制 BLOB 数据。它使用大型记录标头。
大型 BLOB 记录支持多种不同的格式。这些格式可用于更改记录中包含的 BLOB 数据和元数据的类型。
格式
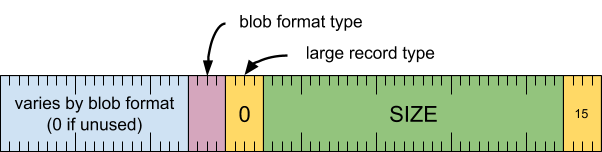
标题字词
[0 .. 3]:记录类型 (15)[4 .. 35]:记录大小(包括此字),以 8 字节的倍数表示[36 .. 39]:大型记录类型 (0)[40 .. 43]:blob 格式类型[44 .. 63]:保留,必须为零
在带元数据的大型 Blob 记录中(Blob 格式 = 0)
此类型包含记录本身中的 blob 数据和元数据。元数据除了包含类别和名称之外,还包含时间戳、线程/进程信息和实参。
该名称应足以标识 blob 中包含的数据类型。
格式
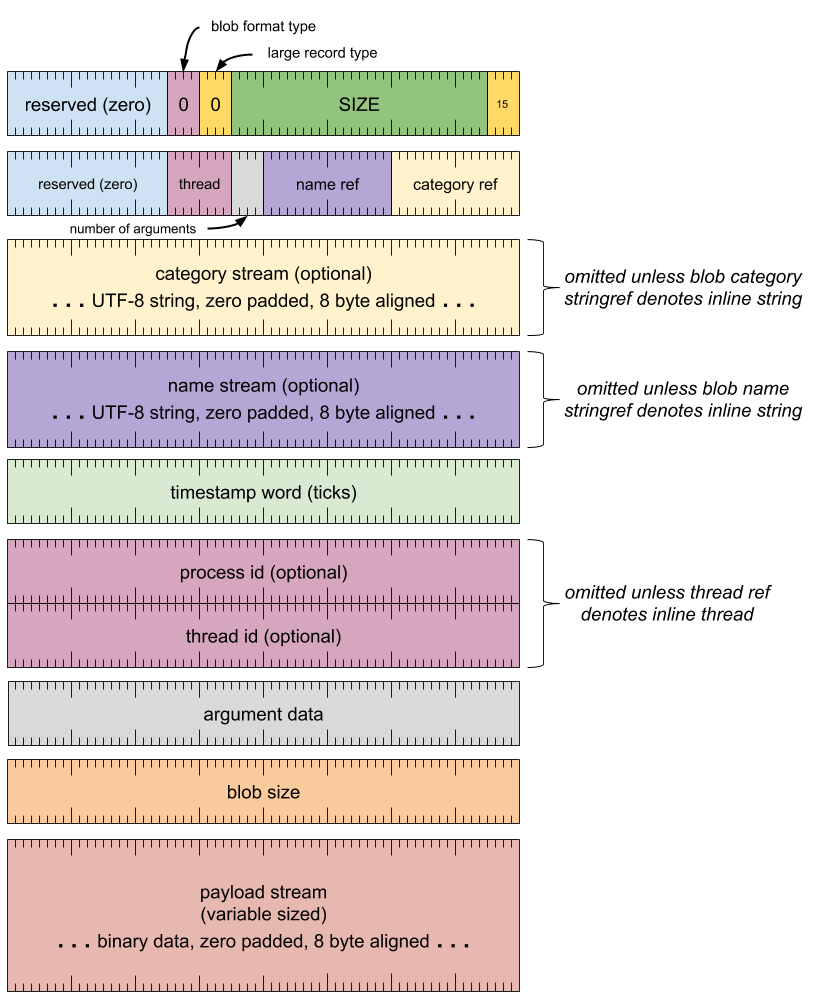
标题字词
[0 .. 3]:记录类型 (15)[4 .. 35]:记录大小(包括此字),以 8 字节的倍数表示[36 .. 39]:大型记录类型 (0)[40 .. 43]:blob 格式类型 (0)[44 .. 63]:保留,必须为零
格式标题字词
[0 .. 15]:类别(字符串引用)[16 .. 31]:名称(字符串引用)[32 .. 35]:实参数量[36 .. 43]:线程(线程引用)[44 .. 63]:保留,必须为零
类别流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
时间戳字词
[0 .. 63]:计时周期数
进程 ID 字词(除非线程引用表示内嵌线程,否则会省略)
[0 .. 63]:进程 koid(内核对象 ID)
线程 ID 字词(除非线程引用表示内嵌线程,否则会省略)
[0 .. 63]:线程 koid(内核对象 ID)
实参数据(针对每个实参重复)
- (请参见下文)
blob 大小字词
[0 .. 63]:blob 载荷大小(以字节为单位,不包括填充)
载荷流(大小可变)
- 二进制数据,用零填充到 8 字节对齐
带内大型 Blob 记录(无元数据)(Blob 格式 = 1)
此类型包含记录本身中的 blob 数据,但不包含元数据。记录仅包含类别和名称。
该名称应足以标识 blob 中包含的数据类型。
格式
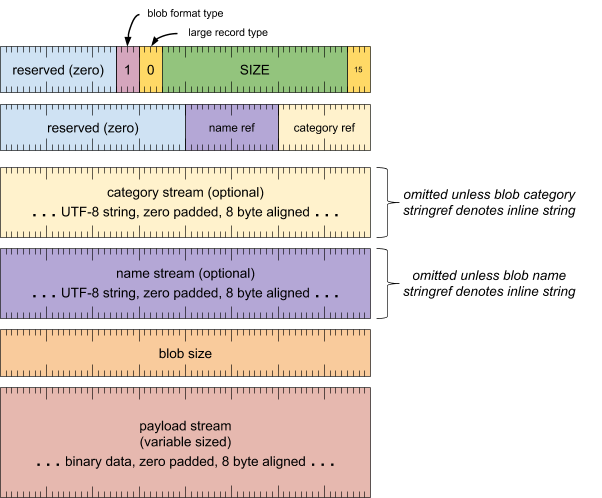
标题字词
[0 .. 3]:记录类型 (15)[4 .. 35]:记录大小(包括此字),以 8 字节的倍数表示[36 .. 39]:大型记录类型 (0)[40 .. 43]:blob 格式类型 (1)[44 .. 63]:保留,必须为零
格式标题字词
[0 .. 15]:类别(字符串引用)[16 .. 31]:名称(字符串引用)[32 .. 63]:保留,必须为零
类别流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
blob 大小字词
[0 .. 63]:blob 载荷大小(以字节为单位,不包括填充)
载荷流(大小可变)
- 二进制数据,用零填充到 8 字节对齐
实参类型
实参关联了带类型的键和值数据记录。它们与事件记录、用户空间对象记录和内核对象记录一起使用。
每个实参都包含一个单字标头,后跟数量不等的载荷字词。在许多情况下,标头本身足以对实参的内容进行编码。
实参类型如下:
- 实参标题
- Null 实参
- 32 位有符号整数实参
- 32 位无符号整数实参
- 64 位有符号整数实参
- 64 位无符号整数实参
- 双精度浮点实参
- 字符串实参
- 指针实参
- 内核对象 ID 实参
- 布尔值实参
- Blob 实参
实参标题
所有实参都包含此标头,其中指定了实参的类型、名称和大小,以及 32 位数据(其用途因实参类型而异)。
格式
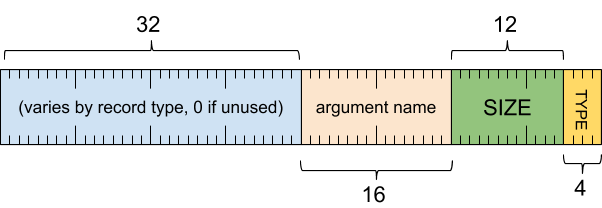
实参标题字词
[0 .. 3]:实参类型[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:可变(如果未使用,则必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
null 实参(实参类型 = 0)
表示仅显示名称而不显示值的实参。
格式
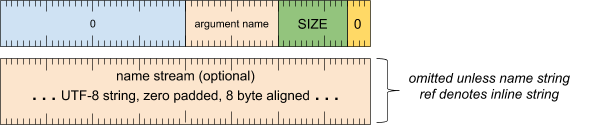
实参标题字词
[0 .. 3]:实参类型 (0)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:保留(必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
32 位有符号整数实参(实参类型 = 1)
表示 32 位有符号整数。
格式
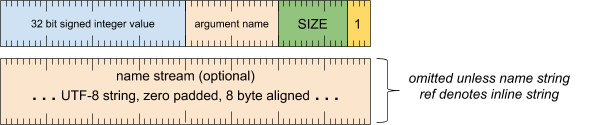
实参标题字词
[0 .. 3]:实参类型 (1)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:32 位有符号整数
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
32 位无符号整数实参(实参类型 = 2)
表示 32 位无符号整数。
格式
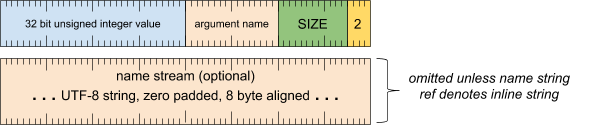
实参标题字词
[0 .. 3]:实参类型 (2)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:32 位无符号整数
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
64 位有符号整数实参(实参类型 = 3)
表示 64 位有符号整数。如果某个值适合 32 位,请改用 32 位有符号整数实参类型。
格式

实参标题字词
[0 .. 3]:实参类型 (3)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:保留(必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参值字词
[0 .. 63]:64 位有符号整数
64 位无符号整数实参(实参类型 = 4)
表示 64 位无符号整数。如果某个值适合 32 位,请改用 32 位无符号整数实参类型。
格式

实参标题字词
[0 .. 3]:实参类型 (4)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:保留(必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参值字词
[0 .. 63]:64 位无符号整数
双精度浮点实参(实参类型 = 5)
表示双精度浮点数。
格式
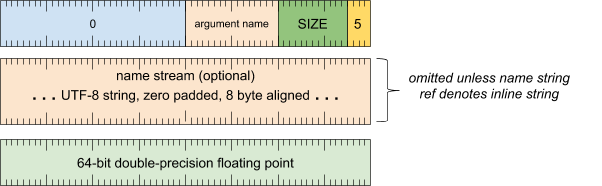
实参标题字词
[0 .. 3]:实参类型 (5)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:保留(必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参值字词
[0 .. 63]:双精度浮点数
字符串实参(实参类型 = 6)
表示字符串值。
格式
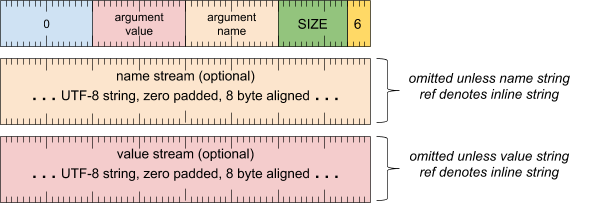
实参标题字词
[0 .. 3]:实参类型 (6)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 47]:实参值(字符串引用)[48 .. 63]:保留(必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参值流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
指针实参(实参类型 = 7)
表示指针值。有关被引用对象的其他信息可以通过与同一指针关联的用户空间对象记录来提供。
格式
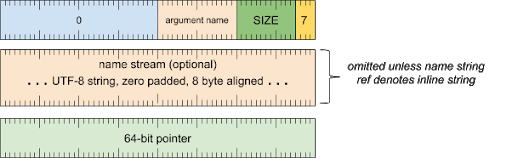
实参标题字词
[0 .. 3]:实参类型 (7)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:保留(必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参值字词
[0 .. 63]:指针值
内核对象 ID 实参(实参类型 = 8)
表示内核对象 ID (koid)。与同一 koid 关联的内核对象记录可以提供有关被引用对象的其他信息。
格式
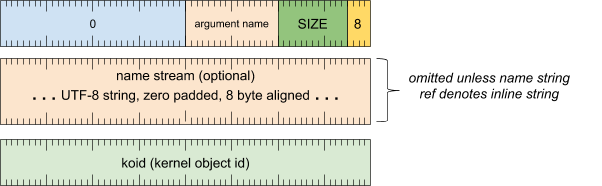
实参标题字词
[0 .. 3]:实参类型 (8)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:保留(必须为零)
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
实参值字词
[0 .. 63]:koid(内核对象 ID)
布尔值实参(实参类型 = 9)
表示一个布尔值。
格式
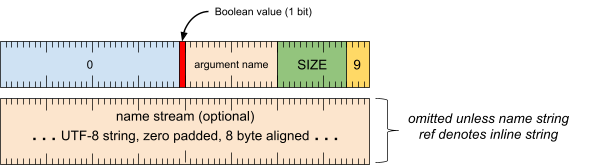
实参标题字词
[0 .. 3]:实参类型 (9)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:1 位,用零填充
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
Blob 实参(实参类型 = 10)
表示不透明的二进制数据。最大大小略小于 32k。
格式
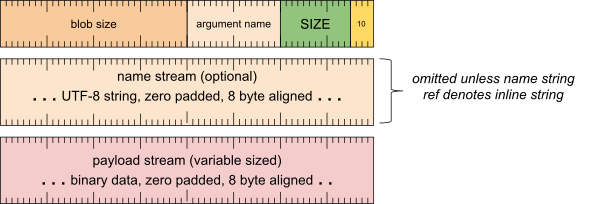
实参标题字词
[0 .. 3]:实参类型 (10)[4 .. 15]:实参大小(包括此字),以 8 字节为倍数[16 .. 31]:实参名称(字符串引用)[32 .. 63]:32 位无符号 blob 大小
实参名称流(除非字符串引用表示内嵌字符串,否则会省略)
- UTF-8 字符串,用零填充到 8 字节对齐
载荷流
- 二进制数据,用零填充到 8 字节对齐
- 最大大小为 32k 减去 8 字节的标头,以及用于内嵌实参名称(如果使用)的尽可能多的 8 字节字。
- 由于有效负载流可能会填充,因此读取器应舍弃超出 blob 大小标头字段中指定的长度的字节。