
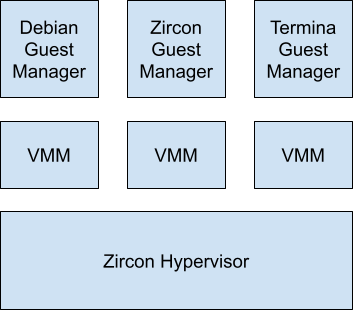
Fuchsia’s virtualization stack provides the ability to run guest operating
systems. Zircon implements a Type-2 hypervisor that
exposes syscalls to enable userspace components to create and configure CPU and
memory virtualization. The Virtual Machine Manager (VMM) component builds on
top of the hypervisor to assemble a virtual machine by defining a memory map,
setting up traps, and emulating various devices and peripherals. Guest manager
components then sit atop the VMM to provide guest-specific binaries and
configuration. Fuchsia supports 3 guest packages today; an unmodified Debian
guest, a Zircon guest, and a Termina-based linux guest.
Fuchsia virtualization is supported on Intel-based x64 devices that have VMX enabled and most arm64 (ARMv8.0 and above) devices that can boot into EL2. Notably, AMD SVM is not currently supported.
Hypervisor
The hypervisor exposes syscalls to allow creation of kernel objects to support virtualization. Syscalls that create new hypervisor objects require that the caller has access to the hypervisor resource so that a component’s ability to create a virtual machine may be controlled by the product. In other words, a Fuchsia component must be granted the capability to create a guest operating system so products have the ability to limit which components are capable of utilizing these features.
CPU Virtualization
The zx_vcpu_create syscall creates a new virtual-CPU (VCPU) object and binds
that VCPU to the calling thread. The VMM can then use the
zx_vcpu_{read|write}_state syscalls to read and write the architectural
registers for that VCPU. The zx_vcpu_enter syscall is a blocking syscall used
to context switch into the guest and a return from zx_vcpu_enter represents a
context switch back to the host. In other words, if there are no threads
currently inside zx_vcpu_enter then there will be nothing executing within the
guest context. All of zx_vcpu_read_state, zx_vcpu_write_state, and
zx_vcpu_enter must be called from the same thread that called
zx_vcpu_create.
The zx_vcpu_kick syscall exists to allow the host to explicitly request that a
VCPU exit back and cause any call to zx_vcpu_enter to return.
Memory & IO Virtualization
The zx_guest_create syscall creates a new guest kernel object. Critically,
this syscall returns a Virtual Memory Address Region (vmar)
handle that represents the Guest’s Physical Address Space. The VMM is then
able to supply the guest ‘physical memory’ by mapping a Virtual Memory
Object (vmo) into this vmar. Since this vmar represents the
Guest-Physical Address space, offsets into this vmar will correspond to
Guest-Physical Addresses. For example, if the VMM wishes to expose 1GiB of
memory at Guest-Physical address range [0x00000000 - 0x40000000), the VMM
would create a 1GiB vmo and map it into the Guest-Physical vmar at offset 0.
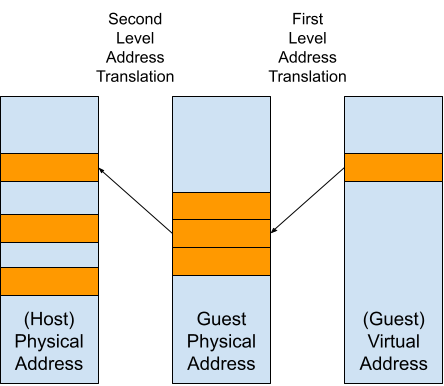
This Guest-Physical vmar is implemented using Second Level Address
Translation (SLAT), which allows the hypervisor to define
translations for Host-Physical Addresses (HPA) to a Guest-Physical Addresses
(GPA). The guest operating system is then able to install their own page tables
that handle translations from a Guest-Virtual Address (GVA) to a Guest-Physical
Address.
The zx_guest_set_trap syscall allows for the VMM to install traps that are
used for device emulation. Guests can interface with hardware using
Memory-Mapped I/O (MMIO) which involves the guest reading and
writing the device using the same instructions that are used for memory
accesses. For MMIO, there will be no mapping present in the SLAT for the
device's GPA which causes the guest to trap into the hypervisor.
x86 provides an alternate way of addressing IO devices called Port-Mapped I/O (PIO). With PIO the guest will use alternate instructions to access a device, but these instructions will still cause the guest to trap into the hypervisor for handling.
The details of how a trap is handled is specific to the type of trap that was created:
ZX_GUEST_TRAP_MEM - Sets a trap for MMIO. Read or write operations to the
address range in Guest-Physical Address Space associated with this trap will
cause the zx_vcpu_enter syscall to return to the VMM, which is then
responsible for emulating the access, updating the VCPU register state, and then
calling zx_vcpu_resume again to return back to the guest.
ZX_GUEST_TRAP_IO - Similar to ZX_GUEST_TRAP_MEM, except instead of setting
the trap in guest-physical address space, the trap will be installed into the IO
space of the processor. This will fail if the architecture does not support PIO.
ZX_GUEST_TRAP_BELL - Sets an async trap for MMIO. When a guest writes to the
guest-physical address range associated with this trap, instead of causing
zx_vcpu_enter to return to the VMM, the hypervisor will instead queue a
message on the port associated with this trap and immediately resume VCPU
execution without returning to userspace. This can be used to emulate devices
that are designed to work with this pattern. For example, Virtio devices allow
the guest driver to notify the virtual device that there is work to be done by
writing to a special page in Guest-Physical Memory.
Setting an async trap in IO space is not supported. Reads from a region with a
ZX_GUEST_TRAP_BELL set are not supported.
Trap Handling
A VCPU thread will typically spend most of its time blocked on zx_vcpu_enter,
meaning it’s executing within the guest context. A return from this syscall to
the VMM, indicates either an error has occurred, or more typically, that the
VMM needs to intervene to emulate some behavior.
To demonstrate, we consider a couple specific examples of how traps can be
handled by the VMM.
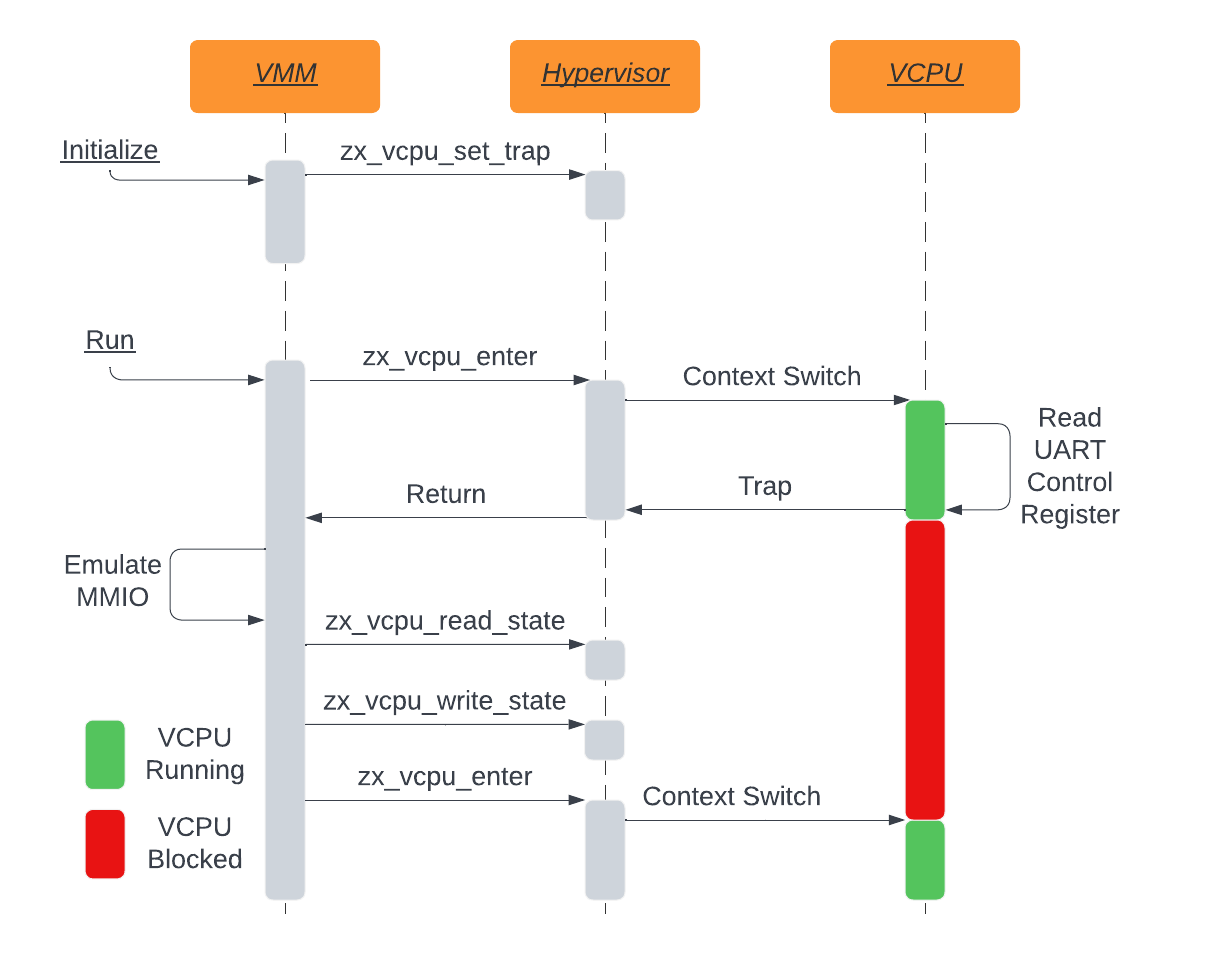
MMIO Sync Trap Example
For example, consider the ARM PL011 serial port emulation. Note that while this is an ARM-specific device in practice, the trap handling will happen similarly on both ARM and x86.
First, the VMM registers a synchronous MMIO trap
on the Guest-Physical Address range of [0x808300000 - 0x808301000), which
tells the hypervisor that any access to this region must cause zx_vcpu_enter
to return control flow to the VMM.
Next the VMM will call zx_vcpu_enter on one or more VCPUs to context switch
into the guest. At some point, the PL011 driver will attempt to read data from
the serial port control register UARTCR register in the PL011 device. This
register is located at offset 0x30 so this corresponds to Guest-Physical
Address 0x808300030 in this example.
Since a trap is registered for Guest-Physical Address 0x808300030, this read
causes the guest to trap into the Hypervisor for handling. The hypervisor can
observe that this access has an associated ZX_GUEST_TRAP_MEM and passes
control flow to the VMM by returning from zx_vcpu_enter with details about
the trap contained within the zx_port_packet_t. The VMM can then use the
Guest-Physical Address of the access to associate it with the corresponding
virtual device logic. In this situation, the device
is maintaining the register value in a member variable.
// `relative_addr` is relative to the base address of the trapped region.
zx_status_t Pl011::Read(uint64_t relative_addr, IoValue* value) {
switch (static_cast<Pl011Register>(relative_addr)) {
case Pl011Register::CR: {
std::lock_guard<std::mutex> lock(mutex_);
value->u16 = control_;
return ZX_OK;
}
// Handle other registers...
}
}
This returns a 16-bit value, but we still need to expose this result to the
guest. Since the guest has performed an MMIO, the guest will be expecting the
result to be in the whatever register was specified in the load instruction.
This is accomplished by using the zx_vcpu_read_state and zx_vcpu_write_state
syscalls to update the value of the target register
with the result of the emulated MMIO.
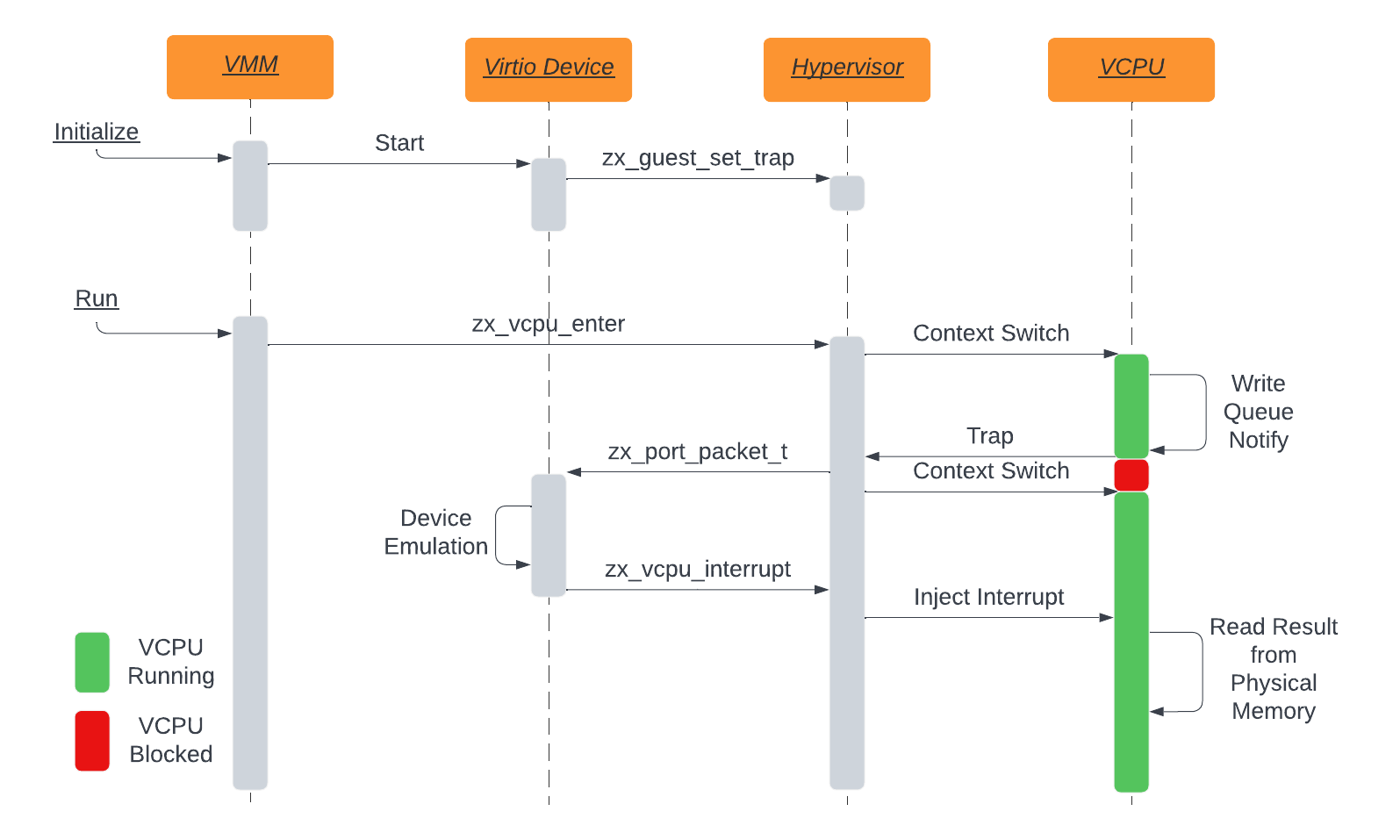
Bell Trap Example
Next we demonstrate the operation of a Bell trap. In this situation we have a
Virtio Device being implemented in a component outside of the main VMM.
During initialization, the VMM requests that the Virtio Device register Bell
traps itself so that the traps will be delivered to the Virtio Device
component and not the VMM. Once the Virtio Device completes setting up any
traps, the VMM begins executing VCPUs with zx_vcpu_enter and control flow is
transferred into the guest.
At some point a guest driver will issue a MMIO write to a Guest-Physical Address
that has been trapped by the Virtio Device. At this point the guest will trap
out of guest context into the hypervisor, which will cause a notification to be
delivered to the Virtio Device using a zx_port_packet_t. Notably in this
situation zx_vcpu_enter never returns during the handling of this trap and the
hypervisor can quickly context switch back into the guest, minimizing the amount
of time the VCPU spends blocked.
Once the Virtio Device receives the zx_port_packet_t, it will take
device-specific steps to handle that trap. Typically this involves reading and
writing directly to Guest-Physical memory, but it can do this without blocking
VCPU execution. Once the device has completed the request it can notify the
driver in the guest by sending an interrupt using zx_vcpu_interrupt.
Since this vast majority of communiciation is done using shared memory and not
using synchronous traps, Virtio devices are much more efficient than devices
that rely heavily on synchronous traps.
Architectural Differences in Trap Handling
While much of the trap handling is the same, there are some important
differences in what needs to be done in response to a trap depending on the
underlying hardware support. Most notably, on ARM, the underlying data abort
that is generated by the hardware provides some decoded information about the
access that we can forward to userspace (ex: access size, read or write, target
register, etc). On Intel this does not occur and as a result the VMM needs to
do some instruction decoding to infer this same
information.
Interrupt Virtualization
Fuchsia implements what some platforms call a ‘split irqchip’, with emulation of the LAPIC/GICC done in the kernel and the I/OAPIC/GICD emulation occurring in userspace. The userspace I/OAPIC and GICD forward interrupts to a target cpu using the zx_vcpu_interrupt syscall.
Virtual Machine Manager (VMM)
The Virtual Machine Montior (VMM) is the userspace component that
uses the hypervisor syscall to build and manage a virtual machine and perform
device emulation. The VMM constructs the virtual machine using the
GuestConfig FIDL structure provided to it, which contains
both configuration about which devices should be provided to the virtual machine
as well as resources for the guest kernel, ramdisks, and block devices.
At a high level, the VMM assembles the virtual machine by using the hypervisor
syscalls to create the guest and VCPU kernel objects. It allocates guest RAM by
creating a VMO and maps it into the Guest-Physical Memory vmar. It uses
zx_guest_set_trap to register MMIO and port-io handlers for virtual hardware
emulation. The VMM emulates a PCI bus and can connect devices to that bus. It
loads the guest kernel into memory and sets up boot data with various resources
needed by the guest kernel, such as device tree blobs or ACPI tables.
Memory
The VMM will allocate a vmo to use as guest-physical memory and map this vmo
into the Guest-Physical Memory vmar (created by zx_guest_create). When
addressing memory in the guest-physical memory vmar we call these addresses
‘Guest-Physical Addresses’ (GPA). The VMM will also map the same vmo into its
process address space so that it can directly access this memory. When
addressing memory in the VMM’s vmar we call these addresses ‘Host-Virtual
Addresses’ (HVA). The VMM is able to translate a GPA into an HVA since it
knows both the guest memory map, as well as the address in its own vmar that the
guest memory is mapped.
Virtio Devices & Components
Many devices are exposed to the guest using Virtual I/O
(Virtio) over PCI. The Virtio specification defines a set of devices that
are designed to run efficiently in a virtualization context by relying heavily
on DMA accesses to Guest-Physical memory and minimizing the number of
synchronous IO traps. To increase security and isolation between devices, we run
each Virtio device in its own zircon process and only route the capabilities
needed by that component. For example, a Virtio Block device is only provided
a handle to the specific file(s) or device that backs the virtual disk, and a
Virtio Console only has access to the zx::socket for the serial stream.
Communication between the VMM and devices is done using the
fuchsia.virtualization.hardware FIDL library. For each
device, there is a small piece of code that is linked into the VMM, called the
controller, that acts as the client to these FIDL
services and connects to the component that implements the device
during startup. There is one process per device instance, so if a virtual
machine has 3 Virtio Block devices, there will be 3 controller instances and 3
Virtio Block components in 3 zircon processes.
Virtio devices operate on the concept of shared data structures that reside in
Guest-Physical memory. The guest driver will allocate and initialize these
structures at boot and provide the VMM with pointers to these structures in
Guest-Physical Memory. When the driver wants to notify the device that it has
published new work to these structures, it will write to a special
device-specific ‘notify’ page in Guest-Physical Memory and the device can infer
specific events based on the offset of the write into this ‘notify’ page. Each
device component will register a ZX_GUEST_TRAP_BELL for this region so that
the hypervisor can forward these events directly to the target component,
without needing to bounce through the VMM. The device components can then read
and write these structures directly by reading these structures by their HVA.
Booting
The VMM does not provide any guest BIOS or firmware but instead loads the
guest resources into memory directly and configures the boot VCPU to jump
directly to the kernel entry point. The details of this vary which kernel is
being loaded.
Linux Guests
For x64 Linux guests, the VMM loads a bootable kernel image (ex: bzImage) into
Guest-Physical Memory in accordance with the Linux boot
protocol and updates the Real-Mode Kernel Header
and Zero Page with other kernel resources (ramdisk,
kernel command-line). The VMM will also generate and load a set of ACPI
Tables that describe the emulated hardware offered to the
guest.
Arm64 Linux guests behave similarly, except we follow the arm64 boot protocol and offer a device tree blob (DTB) instead of ACPI tables.
Zircon Guests
The VMM also supports booting Zircon guests according to the Zircon boot
requirements. Some details of how zircon boots can be found here.
Guest Managers
The role of the Guest Manager components is to package up the guest binaries
(kernel, ramdisk, disk images) with configuration (which devices to enable,
guest kernel configuration options) and provide these to a VMM at startup.
There are 3 Guest Managers available in-tree, two of which are fairly simple and
one more advanced. The simple guest managers don’t have any guest-specific code,
only configuration and binaries that are passed along to the VMM. These guests
are then used over the virtual console or virtual frame-buffer.
Simple Guest Managers: ZirconGuestManager DebianGuestManager
The more advanced Guest Manager is TerminaGuestManager which exposes additional
functionality using gRPC services running over Virtio Vsock. The
TerminaGuestManager has additional functionality to connect to these services
and provide more functionality (run commands in the guest, mount filesystems,
launch applications).
For more information on how to launch and use virtualization on Fuchsia, see Getting Started with Fuchsia Virtualization.