
直接記憶體存取 (DMA) 功能可讓硬體存取 不必為 CPU 介入處理 以最高層級來說,硬體是取得來源和目的地 並要求複製資料。 有些硬體週邊裝置甚至支援執行多個 「散佈 / 收集」樣式作業,其中多次複製作業 這些物件彼此可以逐一執行,不需額外的 CPU 介入。
指定行銷區域注意事項
為了充分瞭解相關議題,你必須 請留意以下事項:
- 每個程序在虛擬位址空間中運作
- MMU 可以將連續的虛擬位址範圍對應至多個 不連續的實體位址範圍 (反之亦然)
- 每個程序都有有限的實體位址空間
- 部分週邊裝置支援各自的虛擬位址 具有輸入 / 輸出記憶體管理單位 (IOMMU)。
現在來逐一討論每個重點。
虛擬、實體和裝置的實際位址
程序可存取的位址是虛擬的;也就是說 CPU 記憶體管理單位 (MMU) 建立的插圖。 MMU 會將虛擬地址對應至實際地址。 對應精細程度是以名為「頁面大小」的參數為依據。哪一個? 至少 4 K,但新型處理器支援更大的尺寸。
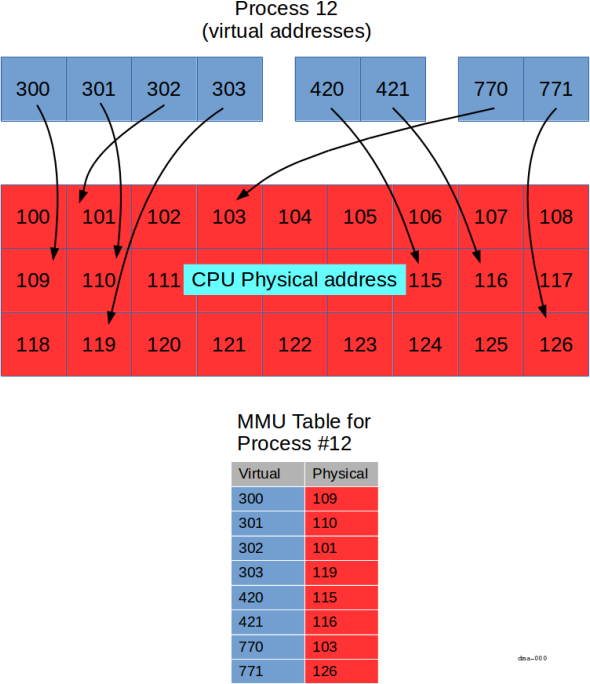
在上圖中,我們顯示特定的程序 (程序 12),並列出多項
虛擬通訊位址 (藍色)。
MMU 負責將藍色虛擬位址對應至 CPU 實體
公車地址 (紅色)。
每個程序都有各自的對應因此即便程序 12 具有虛擬位址
300,某些其他程序可能也會提供虛擬位址 300。
系統會將另一個程序的虛擬位址 300 (如有) 對應
實際地址與處理程序 12 中的實際地址不同
請注意,我們使用小的小數數字做為「地址」讓討論保持簡單 實際上,上方顯示的每個正方形都代表一頁記憶體 (4K 以上), 且可識別 32 或 64 位元的值 (視平台而定)。
圖表中顯示的重點如下:
- 虛擬位址可分配給群組 (顯示三個,分別為
300-303、420-421, 和770-771) - 幾乎連續 (例如
300-303) 不一定是連續的路段。 - 未對應部分虛擬地址 (例如沒有虛擬地址)
304) - 並非所有實際地址都適用於所有程序 (例如
「
12」無法存取實際地址 (120)。
裝置的位址空間 (視平台可用的硬體而定) 不一定會採用類似翻譯 如果沒有 IOMMU,週邊裝置使用的位址會與 CPU 使用的實體位址:

在上圖中,裝置位址空間的部分內容 (例如
影格緩衝區或控制暫存器) 直接顯示在 CPU 實體中
位址範圍
也就是說,裝置會佔用 122 到 125 的實體地址
總和。
為了存取裝置記憶體的程序,需建立
從部分虛擬地址到 122 實體地址的 MMU 對應關係
125。
具體做法如下。
但使用 IOMMU 時,週邊裝置顯示的地址可能會與 CPU 的實際位址
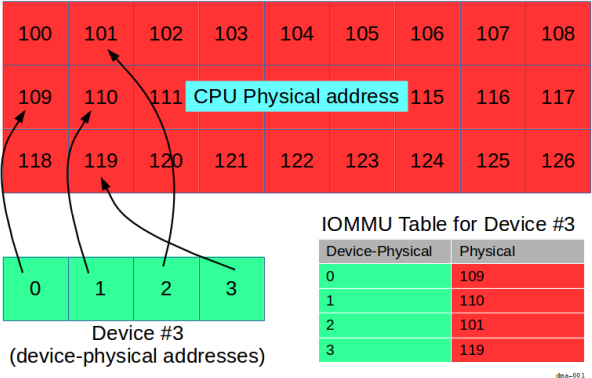
這裡,裝置有專屬的「裝置實體」任何已知位址
也就是說,0 到 3 之間的位址 (含首尾)。
裝置實際位址 0 到 3 的對應關係取決於 IOMMU
實體位址應分別轉換為 CPU 實體位址 109、110、101 和 119。
在這種情況下,為了使用裝置的記憶體,程序必須 排列兩個對應方式:
- 一組從虛擬位址空間 (例如
300至303) 移至 CPU 實體位址空間 (分別為109、110、101和119), 放送 MMU 類別 - 並從 CPU 實體位址空間中設定 (位址
109、110、101、 和119) 傳送到裝置實體位址 (0到3)。
雖然看起來好像很複雜,但 Zircon 提供的抽象層 變得複雜
此外,我們在下方看到採用 IOMMU 的原因,以及取得的好處 與 MMU 相比的結果
記憶體連續性
分配大型記憶體區塊 (例如使用 calloc() 時) 作業流程中當然會有很大的連續虛擬位址範圍, MMU 會在虛擬定址上建立連續記憶體的假象 雖然 MMU 可能會選擇復原記憶體區域 實體地址層級的不連續記憶體。
此外,當程序分配及釋放記憶體時, 虛擬位址空間中的實體記憶體 複雜,鼓勵更多「瑞士起司」圓點 (也就是說 繪製地圖中的不連續)。
因此請特別留意,連續的虛擬位址 不一定是連續的實際地址 但長期下來,實體記憶體容量就會變得越來越珍貴
存取權控管
MMU 的另一個優點是他們對 實體記憶體 (基於安全性和可靠性考量)。 對駕駛人造成的影響,是必須針對 將虛擬位址空間對應至實體位址空間。 同時擁有必要權限。
IOMMU
通常建議使用連續實體記憶體。 如要一次轉移一個資料 (只需一個來源位址和一個來源位址) 只能用來設定及管理多位個人 轉移 (這可能需要在每次傳輸間需處理 CPU 介入) 才能設定下一項)
可以的話,IOMMU 會重複執行相同程序來緩解這個問題 CPU 的 MMU 針對程序執行的周邊裝置,可提供週邊裝置 它會模擬處理連續位址空間的假象 將多個不連續的區塊對應至虛擬連續空間。 藉由限制對應區域,IOMMU 也能確保安全性 (如同 藉此防止週邊裝置存取「範圍內」以外的記憶體,藉此達到上述目的。 目前作業
融會貫通
因此,你似乎需要擔心虛擬、實體和裝置的實體 地址空間。 但事實並非如此。
《數位市場法》和你的驅動程式庫
Zircon 提供一組函式,可讓您輕鬆處理所有 。 下列方式搭配運作:
BTI 核心物件提供模型的抽象化機制,以及一個 API 可處理 與這些使用者相關聯的實體 (或裝置實體) 地址 VMO。
在驅動程式庫的初始化中,呼叫 Pci::GetBti() 取得 BTI 控制代碼:
#include <lib/device-protocol/pci.h>
zx_status_t Pci::GetBti(uint32_t index,
zx::bti* out_bti);
GetBti()
函式位於 ddk::Pci 類別 (就像所有其他 PCI 函式一樣)
並使用 index 參數 (保留供日後使用,請使用 0)。
它會傳回 BTI
物件。out_bti
接下來,您需要 VMO。 簡單來說,您可以將 VMO 做為對記憶體區塊的指標 這也比這更多 - 這是代表集合的核心物件 虛擬網頁 (不一定有實體網頁) 對應至驅動程式庫程序的虛擬位址空間。 (不只如此,但這是其他章節的討論)。
這些頁面最終可做為 DMA 移轉作業的來源或目的地。
有兩種函式 zx_vmo_create() 和 zx_vmo_create_contiguous() 來分配記憶體並繫結至 VMO:
zx_status_t zx_vmo_create(uint64_t size,
uint32_t options,
zx_handle_t* out);
zx_status_t zx_vmo_create_contiguous(zx_handle_t bti,
size_t size,
uint32_t alignment_log2,
zx_handle_t* out);
如您所見,兩者都會使用 size 參數來表示所需的位元組數,
然後都透過 out 傳回 VMO。
兩者都會針對特定大小分配幾乎連續的頁面。
請注意,這與標準 C 程式庫記憶體配置函式不同 (例如 malloc()),這個物件會分配虛擬連續的記憶體,但 設定優先順序資料列中的兩個小型 malloc() 呼叫可能會分配 例如「相同」頁面的兩個記憶體區域,而 VMO 建立函式一律會從「新」頁面開始分配記憶體。
zx_vmo_create_contiguous()
函式的作用是
zx_vmo_create()
確實遵循
適用於搭配指定的 BTI 使用
(所以需要 BTI 控制代碼)。
此 API 也提供 alignment_log2 參數,可用於指定
校正要求。
顧名思義,這必須是 2 的整數次方 (值為 0 表示
頁面對齊)。
目前,您收到了兩次「觀看次數」分配的記憶體:
- 代表記憶體的連續虛擬位址空間 從驅動程式庫的角度出發
- 一組 (可能的連續,也可能是) 實體網頁 供週邊裝置使用
使用這些網頁前,您必須確保這些網頁會出現在記憶體中 (也就是說 「已修訂」— 您的程序可以存取實體網頁),而且 週邊裝置也可以存取這些元件 (如有使用 IOMMU)。 你還需要頁面的網址 (從裝置視角) ,這樣就能在裝置上設定 DMA 控制器,以便存取這些控制器。
zx_bti_pin() 函式可用於完成上述所有操作:
#include <zircon/syscalls.h>
zx_status_t zx_bti_pin(zx_handle_t bti, uint32_t options,
zx_handle_t vmo, uint64_t offset, uint64_t size,
zx_paddr_t* addrs, size_t addrs_count,
zx_handle_t* pmt);
這個函式有 8 個參數:
| 參數 | 目的 |
|---|---|
bti |
這個週邊裝置的 BTI |
options |
選項 (請見下方) |
vmo |
此記憶體區域的 VMO |
offset |
與 VMO 開頭的偏移值 |
size |
VMO 中的位元組總數 |
addrs |
退貨地址清單 |
addrs_count |
addrs 中的元素數量 |
pmt |
傳回 PMT (請見下方) |
addrs 參數是指向您提供的 zx_paddr_t 陣列的指標。
這是各網頁的周邊裝置位址,
陣列包含 addrs_count 個元素,且必須與
原本應來自
zx_bti_pin()。
寫入
addrs的值適合編寫週邊裝置的程式 《數位市場法》控管者,也就是說,任何 可能由 IOMMU 執行 (如果有的話)。
從技術面來看 zx_bti_pin() 核心技術會確保 這些頁面不會遭拒 (已移動或重複使用)。
options 引數實際上是選項的點陣圖:
| 選項 | 目的 |
|---|---|
ZX_BTI_PERM_READ |
週邊裝置 (由驅動程式庫撰寫) 可讀取網頁 |
ZX_BTI_PERM_WRITE |
可透過週邊裝置寫入 (由驅動程式庫閱讀) |
ZX_BTI_COMPRESS |
(請參閱下方的「最低連續屬性」一節)。 |
例如,請參考以上顯示「裝置 3」的圖表。
如果存在 IOMMU,addrs 會包含 0、1、2 和 3 (也就是
例如裝置的實際位址
如果沒有 IOMMU,addrs 會包含 109、110、101 和 119 (也就是
實際地址)。
權限
請注意,權限是出於個人需求
週邊裝置,而非驅動程式庫。
舉例來說,在區塊裝置「寫入」作業中,裝置會從記憶體頁面讀取,
因此,驅動程式庫會在區塊裝置上讀取 ZX_BTI_PERM_READ,反之亦然。
最小連續屬性
根據預設,透過 addrs 傳回的每個地址都是一頁長。
您可以透過設定 ZX_BTI_COMPRESS 選項要求更大的區塊
在 options 引數中。
在這種情況下,傳回的每個項目的長度會對應至「最小連續性」資源。
您無法設定這個屬性,但您可以透過
zx_object_get_info().
事實上,至少連續屬性是保證能
zx_bti_pin()
一律能傳回至少連續這麼位元組的位址。
舉例來說,如果屬性值為 1 MB,則對 zx_bti_pin() 請求大小為 2MB 的請求,最多只會傳回兩次實體連續執行。 如果請求的大小為 2.5 MB,最多會傳回 3 個實體連續的執行作業。 依此類推
固定的記憶體權杖 (PMT)
zx_bti_pin() 會傳回固定的記憶體權杖
(PMT)
在 pmt 引數中傳回成功時的結果。
駕駛人必須在裝置符合下列條件時呼叫 zx_pmt_unpin()
應用程式完成記憶體交易,藉此取消固定並撤銷裝置對記憶體頁面的存取權。
進階主題
快取一致性
在完全 DMA 連貫的架構上,硬體可確保 CPU 快取中的資料 而非軟體介入並非所有架構 符合《數位市場法》規定。在這些系統上,驅動程式庫必須確保 執行 DMA 作業前,對記憶體範圍叫用適當的快取作業。 這樣就不會存取過時資料
如要在代表記憶體的
VMO 時,請使用
zx_vmo_op_range() 系統呼叫。經週邊裝置讀取前
(驅動程式寫入) 作業,請使用 ZX_VMO_OP_CACHE_CLEAN 清除快取,以便將骯髒的資料寫入
主記憶體。進行週邊裝置寫入作業 (驅動程式庫讀取) 前,請使用 ZX_VMO_OP_CACHE_CLEAN_INVALIDATE 來
清除快取行並標示為無效,確保下次從主記憶體擷取資料
資源存取權